以前、本連載ではSeleniumを使ってブラウザを自動操縦する方法を紹介した。とても便利だがブラウザごとのドライバが必要でセットアップが面倒という側面もあった。しかし最近では自動インストールの方法が確立されて便利になった。そこで改めてブラウザの自動操縦を試してみよう。
-

ブラウザを自動操縦して画像をダウンロードしたところ

Seleniumについて
SeleniumとはWebブラウザを自動操縦するためのライブラリだ。もともとブラウザを使って自動テストを行うためのライブラリだが、今ではWeb巡回(クローリング)からデータ抽出(スクレイピング)までいろいろな自動処理に使われている。
Seleniumで可能なのは次のような処理だ。
- ブラウザを自動操縦して任意のページを表示する
- ページ内の任意の要素を抽出する(id属性やclass属性、CSSセレクタで抽出できる)
- ページのスクリーンショットが取得できる
- 表示中のページに対して、JavaScriptを実行できる
- 任意のリンクやボタンをクリックしたり、文字を書き込んだりできる
つまり、ブラウザの大抵の操作を自動化できるのだ。
これを利用して、本連載の49回目と50回目で、クレジットカードや銀行の明細をダウンロードする方法を紹介した。
ブラウザ用のドライバインストールがとても面倒だった
そんな便利なSeleniumだが弱点もあった。上記の連載でも注意書きを記述しているが、PCにインストールされているブラウザのバージョンとインストールしたSelenium用のドライバが少しでも違うとエラーが出る。そのため、プログラムの実行前に、ブラウザの詳細なバージョンを確認し、それに応じたドライバを探してインストールするという作業が必要だったのだ。
ブラウザは定期的に自動アップデートするものなので、数日前には動いたのに今日は動かないということが多く起きており面倒に感じていた。
webdriver-managerのインストール
このドライバのインストールが面倒という問題に対処するために、「webdriver-manager」というパッケージが登場した。一度、webdriver-managerをインストールしておけば、自動的に利用中のブラウザバージョンを確認して必要なドライバをインストールしてくれる。これは非常に便利だ。
そのため、Seleniumをインストールするときに、webdriver-managerも一緒にインストールしてしまうと良いだろう。ターミナル(WindowsならPowerShell、macOSならターミナル.app)を起動して、次のコマンドを実行するとインストールできる(Windowsの場合は、python3のところをpythonと読み替えてください)。
$ python3 -m pip install -U selenium webdriver-manager
Google検索を自動でためしてみよう
なお、今回はブラウザのGoogle Chromeを利用してみよう。
簡単な利用例として、Googleで「python」を検索してその画面のスクリーンショットを撮影するプログラムを作ってみた。以下のプログラムを「hello_selenium.py」という名前で保存しよう。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time, os
# Chromeを起動 --- (*1)
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()))
# Google検索を行う--- (*2)
driver.get('https://google.com/search?q=python')
time.sleep(1)
# スクリーンショットを保存 --- (*3)
driver.save_screenshot('test.png')
time.sleep(60)
# ブラウザを閉じる
driver.close()
プログラムを実行するには、ターミナルで以下のコマンドを実行する。
$ python3 hello_selenium.py
すると、次のようにChromeを起動して、Googleで検索を行ってスクリーンショットを撮影する。
-

ブラウザを自動操作してGoogleで検索したところ

プログラムを確認しよう。(*1)の部分では、Chromeを起動する。もしもChromeのためのドライバがインストールされていなければ、ここで自動でドライバをインストールしてから実行してくれる。
(*2)では「python」という語句をGoogle検索を行うページを表示する。
(*3)ではスクリーンショットを撮影してファイル「test.png」に保存する。
ブラウザを自動操縦して画像を丸ごとダウンロードしよう


なお、せっかくブラウザの自動化処理なので、ページ内にある画像を丸ごとダウンロードするプログラムを作ってみよう。以下のプログラムを「download.py」という名前で保存しよう。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import time, os
import urllib.parse
# 画像の保存先を指定
IMAGES_DIR = './images'
if not os.path.exists(IMAGES_DIR): os.mkdir(IMAGES_DIR)
# Chromeを起動 --- (*1)
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 書道掲示板の「温泉」ページを開く --- (*2)
name = urllib.parse.quote('温泉')
driver.get('https://uta.pw/shodou/index.php?tag&show&name=' + name)
time.sleep(1)
# 画像一覧を得る --- (※3)
images = driver.find_elements(By.CSS_SELECTOR, '.art_frame img')
# 繰り返し要素を取り出す --- (*4)
for img in images:
alt = img.get_attribute('alt')
path = os.path.join(IMAGES_DIR, alt + '.png')
print(path)
# 画像をファイルに保存 --- (*5)
with open(path, 'wb') as f:
f.write(img.screenshot_as_png)
# 画像が切れるのを防ぐために少しずつスクロール --- (*6)
driver.execute_script('window.scrollBy(0,80)')
time.sleep(0.2)
プログラムを実行するには、ターミナルで以下のコマンドを実行する。
$ python3 download.py
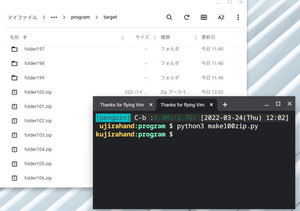
すると、次のようにサイト内に表示されている画像の一覧をimagesというフォルダに保存する。
-

プログラムを実行したところ

プログラムを確認してみよう。(*1)の部分でChromeを起動する。
(*2)では筆者が運営している書道掲示板の「温泉」ページを表示する。なお、アクセス先のサーバーに負荷を与えないように、time.sleep(1)を入れて負荷を下げるように配慮しよう。
(*3)ではCSSセレクタを指定して、任意の要素一覧を取り出す。ここでは「.art_frame」というclass要素を持つ要素の下にあるimg要素(つまり、
そして、(*4)ではfor文を利用して一つずつimg要素を処理するようにした。都合が良いことにalt属性には画像の作者とタイトルが入ったので、これをファイル名に利用した。
(*5)ではimg要素をPNG形式でスクリーンショットを撮影しファイルに保存する。ここでは、実際にはダウンロードではなく、ブラウザに表示されているimg要素のスクリーンショットを保存しているだけだ。大量の画像を効率よく収集したい場合には、改めてリンク先をダウンロードするのではなく、このようにスクリーンショットを保存する方法もある。ただし、(*6)でウィンドウを少しずつスクロールさせているように、必ずしも正確なスクリーンショットが取れるわけではない。
まとめ
以上、今回はwebdriver-managerを使う事で、手軽にSeleniumを使ってブラウザを自動操縦する方法を紹介した。昨今、業務でブラウザを使う事が多いので、Pythonで自動操作することで、さまざまな仕事を効率化できるだろう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。直近では、「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方 TensorFlow2対応(ソシム)」「マンガでざっくり学ぶPython(マイナビ出版)」など。