最近では、古今東西、いろいろな小説がオンラインで公開されている。それらの小説を読み始めたら時間がいくらあっても足りないほどだ。そこで、今回は、簡単なネガポジ判定の手法を使って、その小説を読む前に、小説を解析して好きな小説の傾向を掴む方法を紹介しよう。セットアップ不要でブラウザで使えるPython環境の実行環境Colaboratoryを使うので、気軽に形態素解析や自然言語解析の初歩を実践してみよう。
ネット小説は読み放題!
今は小説好きには堪らない時代だ。明治以前の文豪たちの作品であれば、多くは著作権が切れているので「青空文庫で読み放題で、オンライン小説の投稿サイトの「小説を読もう!」なら70万を超えるタイトルが読み放題だ。筆者も小説が好きなので、時々読んでいるのだが、とにかくいろいろな種類があるので、どれを選んで良いのか悩むほど。そこで、今回は、ネガポジ判定の手法を利用して、小説を簡単に解析して、好きな小説の傾向を数値化してみよう。
ネガポジ判定とは?
ネガポジ判定とは『感情分析(英語:Sentiment Analysis)』と呼ばれる技術の一種だ。これは、文章に含まれる「嬉しい」とか「悲しい」という感情表現に関連する単語を抽出して解析を行う手法である。しかもその判定方法は難しいものではない。例えば、「嬉しい」という単語があれば、前向き(ポジティブ)な文章、「悲しい」という単語があれば後ろ向き(ネガティブ)な文章というように判定する。
既に、ある事件に関するTwitterのつぶやきをネガポジ判定するとか、Amazonの商品レビューを判定するなど、様々な分野で利用されている。代表的な応用例が、Yahoo!のリアルタイム検索で、検索語句のネガポジ判定を表示する機能があるので面白い。
ネガポジ判定の作り方
さて、ここから実際にさっそくネガポジ判定を作っていこう。最初に今回作成するプログラムの手順を確認してみよう。箇条書きすると、以下のようになる。
- (1)解析対象の文章を形態素解析して文章を形態素と呼ばれる最小単位に分割する
- (2)分割した各形態素がネガポジ判定用の辞書に合致するかを調べ、合致すればそれを数え上げる
- (3)数えた結果を基に計算して結果を表示する
今回、小説の解析を行うために、GoogleのColaboratoryを使ってみよう。これを使えば、ブラウザ上で、Pythonを実行できる。しかも、機械学習でよく使うライブラリはインストール済みなので、余分な手間がかからない。
Webブラウザで、こちらのColaboratoryにアクセスしたら、Googleアカウントでログインしよう。
そして、画面上部にあるメニューの「ファイル」から「Python3の新しいノートブック」をクリックして作成しよう。すると、以下のような画面が出るので、形態素解析のためのライブラリ「Janome」をインストールしよう。以下のコマンドをセルに書き込んで実行しよう。(実行するには、書き込んだプログラムの左側にある実行ボタンをクリックすれば良い。)
!pip install janome
-
ColaboratoryにJanomeをインストールしたところ

なお、Janomeを利用した形態素解析については、本連載18回目「夏目漱石が最も使った言葉は何? - 文章中の単語をカウントしよう」でも紹介しているので、参考にすると良いだろう。
ネガポジ辞書を準備しよう
次に、前向き(ポジティブ)、後ろ向き(ネガティブ)の判定に使う単語辞書「日本語評価極性辞書」をダウンロードしよう。こちらで公開されている。もし、URLが変更されていなければ、以下のプログラムを入力すれば、データをダウンロードできる。
! curl http://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/pn.csv.m3.120408.trim > pn.csv
上記のコマンドは、curlコマンドを利用してネガポジ辞書をダウンロードし、「pn.csv」というファイルに保存するというものだ。
小説をダウンロードしよう
次に、解析対象となる小説をダウンロードしてみよう。小説はオンライン小説であることを念頭に置くので、HTML形式であるとする。ここでは、青空文庫にある、太宰治の小説「走れメロス」を解析してみよう。ここでも、コマンドを実行してダウンロードしよう。ダウンロードしたファイルは「syosetu.html」という名前で保存する。
!curl https://www.aozora.gr.jp/cards/000035/files/1567_14913.html > syosetu.html
小説をダウンロードしたら、HTMLのタグを除去しよう。画面上ではただのテキストでも、ブラウザのポップアップメニューから「ページのソースを表示」で見てみると、たくさんのHTMLタグが埋め込まれているのが分かる。そこで、HTMLのタグを除去して、テキストだけにしよう。
HTMLのタグを削除するには、BeautifulSoup4というライブラリを使うと良い。これは、Colaboratoryに最初からインストールされているので追加インストールの必要はない。(もしも、インストールされていなければ『! pip install beautifulsoup4』でインストールできる。)
以下のコードを実行することで、HTMLのタグを削除してファイルに保存する。
from bs4 import BeautifulSoup
# ファイルを読み込む
with open("syosetu.html", "rt", encoding="sjis") as f:
html = f.read()
# HTMLをパースする
soup = BeautifulSoup(html, 'html.parser')
# ルビを削除
soup.find("rp").extract()
soup.find("rt").extract()
# テキストだけを取り出す
text = soup.get_text()
print(text)
# 保存
with open("syosetu.txt", "wt", encoding="utf-8") as w:
w.write(text)
実行すると、以下のようにテキストが表示される。またファイル「syosetu.txt」に結果が保存される。
-
タグを取り出したところ

ちなみに、「青空文庫」のHTMLの文字エンコーディングは一般的な「UTF-8」ではなく「Shift_JIS」となっている。「小説を読もう!」のHTMLはUTF-8なので、ファイルを読み込む際には、文字エンコーディングの部分を書き換えよう。なお、プログラミングで大量のファイルを連続でダウンロードするのは、サーバーに負荷をかける行為となるので気をつけよう。
ネガポジ辞書を読み込もう
次に、先ほどダウンロードした日本語評価極性辞書(ファイル名:pn.csv)をPythonの辞書形式として読み込もう。ここでは、CSVファイルを、Pythonの辞書型の変数「np_dic」に読む。
# ネガポジ辞書を読む
import csv
np_dic = {}
fp = open("pn.csv", "rt", encoding="utf-8")
reader = csv.reader(fp, delimiter='\t')
for i, row in enumerate(reader):
name = row[0]
result = row[1]
np_dic[name] = result
if i % 500 == 0: print(i)
print("ok")
このプログラムを実行して「ok」と表示されたら、以下のようなコードを記述して辞書が読み込めたか確認しておこう。
print(np_dic["笑顔"])
print(np_dic["嫌い"])
print(np_dic["時間"])
実行すると、以下のように表示される。結果の「p」がポジティブ、「n」がネガティブで、「e」はどちらとも言えないニュートラルな単語となる。
-
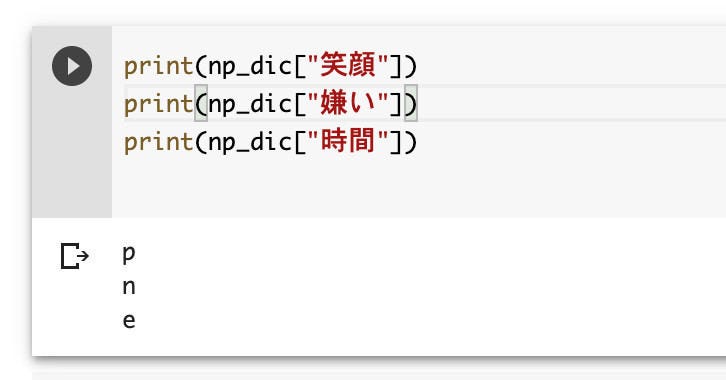
読み込んだ辞書の内容を確認

形態素解析してネガポジを数値化しよう
それでは、形態素解析を行い、ネガポジ判定しよう。Colaboratoryに以下のプログラムを書き込んで実行しよう。但し、上記の手順をすべて実行しておく必要があるので注意しよう。
# 小説を読み込む
fp = open("syosetu.txt", "rt", encoding="utf-8")
text = fp.read()
# 形態素解析
from janome.tokenizer import Tokenizer
tok = Tokenizer()
# 数える
res = {"p":0, "n":0, "e":0}
for t in tok.tokenize(text):
bf = t.base_form # 基本形
# 辞書にあるか確認
if bf in np_dic:
r = np_dic[bf]
if r in res:
res[r] += 1
# 結果を表示
print(res)
cnt = res["p"] + res["n"] + res["e"]
print("ポジティブ度", res["p"] / cnt)
print("ネガティブ度", res["n"] / cnt)
実行すると、以下のような結果が表示された。つまり、「走れメロス」はポジティブ度0.29とネガティブ度0.20となり、若干、前向きな小説であることが分かった。
-

走れメロスの実行結果

他の小説も試してみた
いくつかの小説も試してみたところ、次のような結果となった。
太宰治「走れメロス」の場合:
{'p': 118, 'n': 83, 'e': 208}
ポジティブ度 0.2885085574572127
ネガティブ度 0.20293398533007334
-
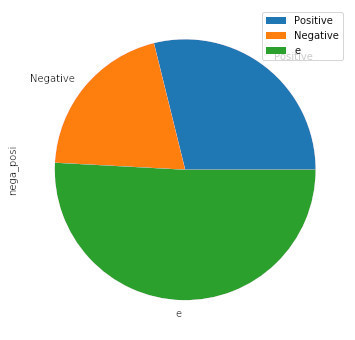
走れメロスの実行結果

夏目漱石「吾輩は猫である」の場合:
{'p': 3324, 'n': 3536, 'e': 7691}
ポジティブ度 0.22843790804755687
ネガティブ度 0.24300735344649851
-
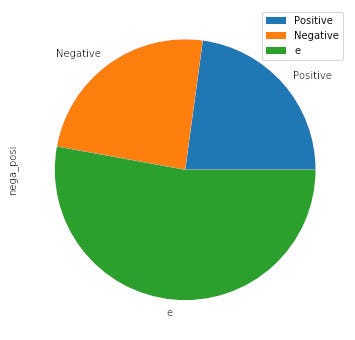
吾輩は猫であるの結果

芥川龍之介「羅生門」の場合:
{'p': 49, 'n': 76, 'e': 133}
ポジティブ度 0.18992248062015504
ネガティブ度 0.29457364341085274
-
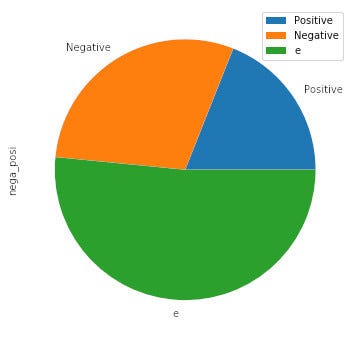
羅生門の結果

以下のようなコードでグラフを描画した。4行プログラムを書くとグラフがでるのが良いところだ。
import pandas as pd
df = pd.DataFrame({'nega_posi':[res['p'], res['n'], res['e']]},
index=['Positive','Negative','e'])
df.plot.pie(y='nega_posi', figsize=(6,6))
まとめ
このように小説をネガポジ判定して、数値で見られるというのはとても新鮮で面白いものだ。今回のプログラムでは、ポジティブ度を判定するのに『ポジティブな単語数 ÷ 判定できた全体の単語数単語』のように計算した。簡単な計算だが物語の雰囲気でこの数値はぐっと変わる。単純ながらそれなりに判定できていると思う。小説以外にも応用できるので、試してみよう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。