連載第5回の目的
この回では、前回に引き続きMobileNetによる画像認識のサンプルを紹介します。この回では、カメラ画像をリアルタイムで認識するサンプルと、転移学習により画像認識をカスタム化するサンプルを紹介します。
完成サンプル
https://github.com/wateryinhare62/mynavi_tensorflowjs/
今回のテーマも引き続き画像認識です。本記事では、以下の2つのサンプルを通じて、MobileNetによるリアルタイムの画像認識と、分類器を用いた転移学習を理解します。
- カメラ画像が何の画像であるかをリアルタイムで予測
- 既存の学習成果を利用して新たに画像を学習して予測
[NOTE]サンプルについて
本記事のサンプルは、Google Codelabのチュートリアル「TensorFlow.js 転移学習による画像分類器」(https://codelabs.developers.google.com/codelabs/tensorflowjs-teachablemachine-codelab?hl=ja#0)におけるサンプルをベースに、一部改変して作成、掲載しています。
リアルタイムの画像認識――TensorFlow.jsによるカメラ画像のキャプチャを理解
前回の静止画像を認識するサンプルを活かした、カメラからの画像をリアルタイムで認識するサンプルです。TensorFlow.jsには、カメラからの画像をテンソル化する機能が備わっているので、それを使って画像認識を行います。
-

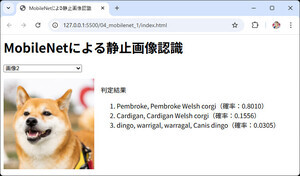
図1:サンプル「リアルタイムの画像認識」の実行結果

[NOTE]CSSファイル
本記事のサンプルでは見た目を整えるために適当なスタイルをstyle.cssで設定しています。TensorFlow.jsやMobileNetとの関連は薄いので掲載は省略しています。具体的な内容は配布サンプルを参照してください。
HTMLファイルを用意する
サンプルの基点となるHTMLファイル(index.html)を1_realtimeフォルダを作成して用意します(リスト1)。インポートしているライブラリなどは前回のリスト1とほぼ同様です。
リスト1:1_realtime/index.html
…略…
<h1>MobileNetによるリアルタイム画像認識</h1>
<!-- (1)カメラ画像のプレースホルダ -->
<video autoplay playsinline muted id="webcam" width="224" height="224"></video>
<!-- (2)判定結果の表示 -->
<div id="result" style="display: none;">
<p>判定結果</p>
<table>
<tr><th>No.</th><th>クラス</th><th>確率</th></tr>
<tr><td>1</td><td><span id="result-class-1"></span></td><td><span id="result-probability-1"></span></td></tr>
<tr><td>2</td><td><span id="result-class-2"></span></td><td><span id="result-probability-2"></span></td></tr>
<tr><td>3</td><td><span id="result-class-3"></span></td><td><span id="result-probability-3"></span></td></tr>
</table>
</div>
…略…
前回のサンプルと同様に、判定する画像のプレースホルダを(1)のように用意しますが、今回はカメラからの画像をリアルタイムで流すため、video要素を使用しています。
判定結果も前節のサンプルと同様に得られますが、リアルタイムでの結果表示となるため、表示のがたつきを抑えるためにテーブルとしています。結果を入れるためのspan要素があるのは同様です。
JavaScriptファイルを用意する
続けて、JavaScriptファイル(script.js)を用意します(リスト2)。
リスト2: 1_realtime/script.js
// (1)モデルとカメラオブジェクトを収納する変数とHTML要素を参照する変数の用意
let net;
let webcam;
const webcamElement = document.getElementById('webcam');
const resultElement = document.getElementById('result');
// (2)初期化関数。モデルを読み込んでカメラオブジェクトを生成する
async function init() {
resultElement.style.display = 'none';
console.log('mobilenetを読み込み中です...');
net = await mobilenet.load();
console.log('mobilenetの読み込みが終了しました');
webcam = await tf.data.webcam(webcamElement, {facingMode: 'environment'});
}
// (3)初期化の実行
init();
// (4)1000ミリ秒ごとに画像をキャプチャして判定、結果をテーブルに格納する
const interval = setInterval(async () => {
const img = await webcam.capture();
const result = await net.classify(img);
for (let i = 0; i < result.length; i++) {
document.getElementById(`result-class-${i + 1}`).innerText = result[i].className;
document.getElementById(`result-probability-${i + 1}`).innerText = result[i].probability.toFixed(4);
}
resultElement.style.display = 'block';
img.dispose();
await tf.nextFrame();
}, 1000);
(2)に登場するtf.data.webcamメソッドは、カメラからの画像(ビデオストリーム)をテンソルとして取得するイテレータを生成します。そのイテレータを用いて、(4)においてcaptureメソッドで画像をキャプチャしてテンソル化し、classifyメソッドに引き渡して判定するという流れです。
webcamメソッドの第1引数は使用するvideo要素ですが、第2要素は動作オプションのオブジェクトです。ここで指定されているfacingModeは、モバイルデバイスにおけるフロント/バックカメラの指定です。'user'でフロントカメラ、'environment'でバックカメラの指定となりますが、実際にどれが使われるかはデバイスに依存します。
なお(4)においてdisposeメソッドとnextFrameメソッドが使われていますが、それぞれの役割は以下の通りです。
- disposeメソッド:パフォーマンス保持のために用済みとなったテンソルのためのメモリをその場で破棄する
- nextFrameメソッド:次のフレームに切り替わるのを待つ
nextFrameメソッドの呼び出しは、確実に新しい画像をキャプチャするためですが、今回のように1秒おきにキャプチャするといったケースでは必須ではありません。しかしながら、間を置かずに連続してキャプチャするといった用途のために、定型処理として入れてあります。
動作確認する
index.htmlファイルをブラウザで読み込むと、カメラが起動して撮影を開始します。カメラ使用の許可を確認されたら、「許諾」を選択してください(以降も同様)。本節冒頭の図1のように、リアルタイムに結果が表示されればOKです。
カメラに写したのはブタさんのマスコットですが、piggy bank(ブタの貯金箱)もしくはpenny bank(いわゆる貯金箱)と認識されています。あくまでも、「モデルが何を学習したか」で判定結果は決まるので、必ずしも期待する結果とならないこともあることを押さえておきましょう。
画像認識のカスタム化――kNN分類器によるカメラ画像の追加学習と分類を理解
最後は、画像認識のカスタム化として、転移学習のサンプルを紹介します。「グーチョキパー」の手の形を撮影し、それぞれにラベルを付けて追加学習させます。何度も学習させることで、「グーチョキパー」を判別して「rock」「scissor」「paper」と表示することができるようになります。
サンプルは、カメラに向かって「グー」「チョキ」「パー」を映し出し、対応するボタンを押して学習させることを何回か繰り返し、「グー」「チョキ」「パー」に対して図2のように正しく認識できることを確認するというものです。


-

図2:サンプル「kNN分類器によるカスタム画像認識」の実行結果

転移学習とk近傍法
転移学習とは前回軽く触れたように、既存の学習モデルをベースとして、独自のデータをさらに学習させることです(追加学習ともいいます)。転移学習の方法にはいろいろありますが、ここでは「k近傍法」(kNN; k-Nearest Neighbors)というアルゴリズムを用います。このアルゴリズムは、新しいデータを最も近いk個の学習データ(近傍点)に基づいて分類または予測するというものです(図3)。つまり、学習済みのデータから近いものを選んで、このグループではないか?と提案するアルゴリズムと言えます。これにより、既存の学習成果を活かしながら、新しいデータへ対応することで、より精度を高めたモデルとすることができるわけです。
-

図3:k近傍法

k近傍法による分類には、knnClassifierという分類器ライブラリを使用します。


カスタム化の手順
既存モデルを利用した学習は、以下のように行います。
- カメラ画像からMobileNetのアクティベーションを取得する
- 分類器にアクティベーションとそれに対応するラベルをクラスに追加する
- カメラ画像からMobileNetのアクティベーションを取得する
- 分類器からアクティベーションに対応するクラスを探して取得する
アクティベーションとは、MobileNetにおけるモデルの内部表現です。特定の画像入力に対して、近いとされるものと思って構いません。つまり、似たものをモデルから探しだし、それにラベルを付けてクラスに追加することで、新たな判定候補とすることができるわけです。
分類器を用いた予測は、以下のように行います。
学習とほぼ同様のプロセスとなりますが、アクティベーションは追加ではなく予測に使用されます。似たようなカメラ画像からは同じアクティベーションが得られることを利用して、アクティベーションに対応するクラスがあれば、それを返すというわけです。
HTMLファイルを用意する
サンプルの基点となるHTMLファイル(index.html)を2_customフォルダを作成して用意します(リスト3)。ライブラリのインポートなどは前回のリスト1とほぼ同様です。
リスト3: 2_custom/index.html
…略…
<!-- (1)分類器ライブラリの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/knn-classifier"></script>
…略…
<h1>kNN分類器によるカスタム画像認識</h1>
<!-- (2)サンプル実行&クリアボタン -->
<div>
<p><button id="class-rock">クラス「Rock」として追加</button>
<button id="clear-rock">クリア</button><br>
サンプル数:<span id="count-rock">0</span></p>
<p><button id="class-scissor">クラス「Scissor」として追加</button>
<button id="clear-scissor">クリア</button><br>
サンプル数:<span id="count-scissor">0</span></p>
<p><button id="class-paper">クラス「Paper」として追加</button>
<button id="clear-paper">クリア</button><br>
サンプル数:<span id="count-paper">0</span></p>
</div>
<!-- (3)判定結果の表示 -->
<div id="result" style="display: none;">
<p>判定結果</p>
<p>クラス:<span id="result-class"></span><br>
確率:<span id="result-probability"></span></p>
</div>
…略…
kNN近傍法による分類器を、MobileNetに加えて(1)のように読み込みます。これにより、knnClassifier変数がグローバルに利用できるようになります。
画像を学習(サンプル)させるボタンと、サンプルをクリアするボタン、サンプル数の表示を(2)のように用意します。それぞれ適切なイベントハンドラを登録してサンプル/クリアを実行させることになります。
判定結果は1個だけなので、結果はspan要素があるだけ(3)のシンプルなものです。
JavaScriptファイルを用意する
JavaScriptファイル(script.js)を用意します(リスト4)。
リスト4 :2_custom/script.js
// (1)分類器を格納する変数とクラスのリスト
let classifier;
…略…
const classNames = ['rock', 'scissor', 'paper'];
…略…
// (2)初期化関数。分類器を生成する
async function init() {
…略…
classifier = knnClassifier.create();
…略…
}
// (3)分類器へサンプルを追加する関数
async function addExample(classId) {
const img = await webcam.capture();
const activation = net.infer(img, true);
classifier.addExample(activation, classId);
img.dispose();
const counts = classifier.getClassExampleCount();
document.getElementById(`count-${classId}`).innerText = counts[classId] || 0;
};
// (4)クラスの学習をクリアする関数
async function clearClass(classId) {
classifier.clearClass(classId);
document.getElementById(`count-${classId}`).innerText = 0;
}
// (5)初期化とイベントハンドラの登録
init();
for (const className of classNames) {
document.getElementById(`class-${className}`).addEventListener('click',
() => addExample(className));
document.getElementById(`clear-${className}`).addEventListener('click',
() => clearClass(className));
}
// (6)1000ミリ秒ごとに画像をキャプチャして判定、結果を表示する
const interval = setInterval(async () => {
if (classifier.getNumClasses() > 0) {
const img = await webcam.capture();
const activation = net.infer(img, true);
const result = await classifier.predictClass(activation);
document.getElementById('result-class').innerText = result.label;
document.getElementById('result-probability').innerText = result.confidences[result.label].toFixed(4);
resultElement.style.display = 'block';
img.dispose();
}
await tf.nextFrame();
}, 1000);
(1)では、クラスのリストを作成しています。リストの3つの要素が、分類器に渡されたり、DOMのid要素を参照したりするために共通で用いられます。
(2)に登場するknnClassifier.createメソッドは、分類器オブジェクトの生成です。このオブジェクトを使い、分類器へのサンプル追加、クラス判定などを実施します。
(3)に登場するnet.inferメソッドは、アクティベーションを取得します。引数の意味は以下の通りです。
- 第1引数はキャプチャした画像を指定する。テンソル、画像イメージ、img/canvas/video要素を指定できる
- 第2引数は結果の形式を指定する。trueを指定すると埋め込み層と呼ばれる次元圧縮したテンソルが返される。falseを指定するとLogitsと呼ばれる、確率に変換される前の値となる
次元圧縮とは、元の情報を最大限維持しつつ、データのサイズや複雑さを減らす(次元数を落とす)ための技術です。次元圧縮を利用することで、以降の計算負荷を減らし、モデルの効率を改善できます。
得られたアクティベーションを、分類器のaddExampleメソッドでクラスとともに追加します。これにより、MobileNetにおける特定のアクティベーションとクラスをひも付けて学習するわけです。また、knnClassifier.getClassExampleCountメソッドは、クラスごとのサンプル数を取得します。配列なので、クラスを指定してサンプル数を取得します。
(4)に登場するclassifier.clearClassメソッドは、引数のクラスのサンプル数をゼロにクリアします。学習状態をリセットし、そのクラスに関して学習をやり直す場合に使用できます。
(6)の流れはリアルタイムの画像認識とほぼ同様ですが、予測をMobileNetと分類器の組み合わせで行っている点が異なります。使われているメソッドの役割は以下の通りです。
- getNumClassesメソッド:分類器にあるクラスの数を取得する。分類器に登録済みのクラスがあるかを判定するために使う
- predictClassメソッド:アクティベーションからクラスを予測する
カメラ画像からinferメソッドでアクティベーションを取得しますが、それを分類器に渡してアクティベーションに近いクラスがあるか判定しているわけです。ですので、何回もサンプルの追加を行うと精度が向上します。
動作確認する
index.htmlファイルをブラウザで読み込むと、カメラが起動して撮影を開始します。カメラに向かって、「グー」「チョキ」「パー」を映し出し、対応するボタンを押すことを何回か繰り返し、「グー」「チョキ」「パー」に対して本節冒頭の図2のように表示されればOKです。
まとめ
今回は、MobileNetを利用したリアルタイムでの画像認識と、転移学習を用いた独自の画像認識のサンプルを紹介しました。シンプルな手順で画像認識を実施できるほか、独自の画像認識に転用するのも簡単であることをお伝えできたのではないかと思います。
次回は、手書き数字の認識を通じて、Kerasなどの外部で学習したモデルをTensorFlow.jsで利用するサンプルを作成します。
WINGSプロジェクト 山内直(著) 山田 祥寛(監修)
有限会社 WINGSプロジェクトが運営する、テクニカル執筆コミュニティ(代表山田祥寛)。主にWeb開発分野の書籍/記事執筆、翻訳、講演等を幅広く手がける。現在も執筆メンバーを募集中。興味のある方は、どしどし応募頂きたい。著書、記事多数。
RSS
X:@WingsPro_info(公式)、@WingsPro_info/wings(メンバーリスト)<著者について>
WINGSプロジェクト所属のテクニカルライター。出版社を経てフリーランスとして独立。ライター、エディター、デベロッパー、講師業に従事。屋号は「たまデジ。」。