拡張子「.tar」というファイルを見かけることがあります。これは、複数のファイルを1つにまとめて保存するTar形式のアーカイブです。特にLinuxなどの環境で使われていますが、仕様が単純なこともあり、現在ではさまざまな場面で活用されています。今回は、Rustでtarファイルの読み書きに挑戦してみましょう。
-

「tar」の構造を調べて読み書きしてみよう

tarファイルとは
「tar」とは 「tape archive(テープアーカイブ)」 の略で、複数のファイルやフォルダを1ファイルにまとめるための形式です。その名前にあるとおり、もともとは磁気テープを操作するためのものでした。
POSIX.1-1988、POSIX.1-2001で規格化されており、UNIX系OSでは、tarコマンドを介して標準で利用できます。また、現在ではWindowsでもコマンドラインツールが標準で搭載されています。
基本的に「tar」は、複数のファイルをまとめるだけの役割しかありません。それで、tarのファイル拡張子を「.tar」とし、tarをgzip形式で圧縮したものを「.tar.gz」あるいは「.tgz」としています。この拡張子の違いにより、単にファイルをまとめただけのものと、gzip形式で圧縮されたものを明確に区別できます。
tarファイルの構造
tarファイルの構造は極めて単純です。次の図のように、「ファイル1のヘッダ」「ファイル1のデータ」「ファイル2のヘッダ」「ファイル2のデータ」…「1024バイトの0x00」となっています。
-

tarファイルの構造を示した図

ファイルのデータブロックは必ず512の倍数であり、実際のデータサイズはヘッダー内の「size」で指定します。
また、ファイルのヘッダーは512バイトであり、次のようなデータを指定します。固定で512バイトもあるので、さまざまなメタ情報を記録できることが分かります。
| オフセット (byte) | 長さ | フィールド名 | 内容 |
|---|---|---|---|
| 0 | 100 | name | ファイル名(パス含む) |
| 100 | 8 | mode | パーミッション(8進) |
| 108 | 8 | uid | 所有者ユーザーID(8進) |
| 116 | 8 | gid | 所有者グループID(8進) |
| 124 | 12 | size | ファイルサイズ(バイト数、8進) |
| 136 | 12 | mtime | 更新日時(Unix時間、8進) |
| 148 | 8 | checksum | チェックサム値(8進) |
| 156 | 1 | typeflag | ファイルタイプ (0なら通常ファイル) |
| 157 | 100 | linkname | リンク先名前(リンク用) |
| 257 | 6 | magic | 「ustar」を指定 |
| 263 | 2 | version | 「00」を指定 |
| 265 | 32 | uname | 所有ユーザー名 |
| 297 | 32 | gname | 所有グループ名 |
| 329 | 8 | devmajor | デバイス major番号 |
| 337 | 8 | devminor | デバイス minor番号 |
| 345 | 155 | prefix | 長いファイル名用プレフィックス |
| 500 | 12 | padding | 余白(未使用) |
データのブロックサイズを512バイトの倍数にする理由
なお、先ほどの図でも見たとおり、各ファイルのデータ・ブロックのサイズは512の倍数にする必要があります。一見すると、とても無駄なものに見えます。しかし、tarが磁気テープ向けに設計されたフォーマットであることを考えると納得できます。
磁気テープは、現在のストレージのように、気軽に1バイト単位で自由に好きな位置からデータを読み書きすることができませんでした。それで、512バイト単位を1ブロックとして読み書きすることで、効率的にデータを管理することができました。
また、当時のUNIXシステムおよびストレージデバイスの多くが、512バイトを基本的な転送単位としていたことも、この仕様に反映されている理由の一つでしょう。
tarファイルの中のファイル名とサイズを表示するプログラム
tarファイルのヘッダーで特に重要なのが、オフセット124にあるファイルサイズです。このサイズの読み取りさえしっかりできれば、次々とtarファイル内のデータを取り出すことができます。
簡単にtarファイルを読み取るプログラムを作ってみましょう。それに先だって、実験用のtarファイル「test.tar」を用意しましょう。OS標準の「tar」コマンドを利用して、tarファイルを作成しましょう。下記のコマンドを実行することで、「file1.txt」「file2.txt」「file3.txt」を一つのtarファイル「test.tar」にまとめることができます。
# tarコマンドでアーカイブを作成
tar -cf test.tar file1.txt file2.txt file3.txt
それで、次のようなプログラムを作ると、tarファイル内のファイル名を順に表示できます。
use std::fs::File;
use std::io::{Read, Seek, SeekFrom};
fn main() -> std::io::Result<()> {
let mut file = File::open("test.tar")?; // 「test.tar」を読み出す
loop {
// ヘッダーの512バイトを読み込み --- (*1)
let mut header = [0u8; 512];
file.read_exact(&mut header)?;
// ファイル終端チェック(ヘッダが全部ゼロ) --- (*2)
if header.iter().all(|&b| b == 0) {
println!("End of TAR");
break;
}
// ファイル名を読み取る (offset 0, length 100) --- (*3)
let name = String::from_utf8_lossy(&header[0..100])
.trim_end_matches('\0')
.to_string();
// 8進数表記のファイルサイズ (offset 124, length 12)を読み取る --- (*4)
let size_str = String::from_utf8_lossy(&header[124..136])
.trim_end_matches('\0')
.trim()
.to_string();
let size = usize::from_str_radix(&size_str, 8).unwrap_or(0);
println!("File: {} (size: {}B)", name, size);
// データ部分をスキップ
// 次のヘッダ位置へ移動 (512バイト境界までパディング) --- (*5)
let padded_size = ((size + 511) / 512) * 512; // 512バイト単位に
file.seek(SeekFrom::Current(padded_size as i64))?;
}
Ok(())
}
プログラムを確認しましょう。(*1)では、512バイトあるヘッダー部分を読み取ります。(*2)では、もし、ヘッダーの値が全部0ならばファイル終端を表すので、読み取りを中止します。
(*3)では、ファイル名を読み取ります。これは、ヘッダーの0から100バイト部分にあるので、スライス[0..100]を文字列に変換して、末尾にある'\0'を除去します。
(*4)では、ファイルサイズを読み取ります。これは、ヘッダーのオフセット124から12バイトの部分にあります。ちょっと間違いやすいのですが、これは8進数表記の文字列となっています。そのため、該当バイトを文字列に変換し、末尾の'\0'を除去した上で、usize::from_str_radix(&str, 8)を利用して整数に変換する必要があります。
(*5)では、サイズを利用して、次のファイルのヘッダー先頭に移動します。データのブロックは512バイトの倍数にしないといけないため、このようなパディング分を計算します。
なお、プログラムを実行するには、ターミナル(WindowsならPowerShell、macOSならターミナル)を起動して、以下のコマンドを実行します。
# プロジェクトを作成して初期化
mkdir read_tar
cd read_tar
cargo init
そして、エディタで、ファイル「src/main.rs」を開いて、上記のプログラムを書き込みます。プログラムを実行するには、次のコマンドを実行します。
cargo run
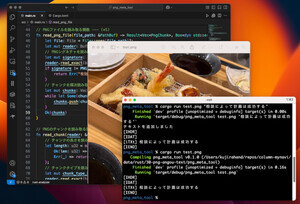
すると、次のように、tarファイルのエントリ一覧を表示します。
-

プログラムを実行して、tarファイルのエントリ一覧を表示したところ

tarファイルを読み書きしよう
さて、次にtarファイルを読み書きしてみましょう。今回は、tarファイルを簡単に読み書きするライブラリ「tar_light」を利用してみましょう。このライブラリを使うことで、tarファイルの作成と展開、gzipで圧縮した「.tar.gz」を扱うことができます。なお、このライブラリは筆者が公開しているものです。
ターミナルを起動して、次のコマンドを実行しましょう。
# tar_testプロジェクトを作る
mkdir tar_test
cd tar_test
cargo init
# tar_lightをライブラリに追加
cargo add tar_light
そして、ファイル「src/main.rs」を次のように編集しましょう。
use std::fs;
use tar_light::Tar;
fn main() {
// 簡単にtarアーカイブを作成する --- (*1)
let mut tar = Tar::new(); // Tarオブジェクトを作成
tar.add_str_entry("file1.txt", "Hello, World!"); // 文字列をエントリとして追加
tar.add_str_entry("file2.txt", "This is a test.");
tar.add_str_entry("file3.txt", "abcd");
let tar_bytes = tar.to_bytes(); // バイト列に変換
// ファイルに保存
fs::write("test.tar", tar_bytes).expect("Failed to write tar file");
// tarファイルを読む --- (*2)
let tar_bytes = fs::read("test.tar").expect("Failed to read tar file");
let tar = Tar::from_bytes(&tar_bytes); // バイト列からTarオブジェクトを作成
// エントリ一覧を表示 --- (*3)
for entry in tar.entries {
let body = String::from_utf8_lossy(&entry.data)
.trim_end_matches('\0').to_string();
println!("--- Entry ---");
println!("File: {}", entry.header.name);
println!("Body: {}", body);
}
}
プログラムを実行するには、下記のコマンドを実行します。


cargo run
プログラムを実行すると、tarファイル「test.tar」を作成し、そのファイルの内容を表示します。
-

プログラムを実行したところ

プログラムを確認してみましょう。プログラムの(*1)では、Tarオブジェクトを作成します。ファイルを3つ追加しますが、ここでは文字列をコンテンツとして追加します。そして、ファイル「test.tar」に保存します。
(*2)では、ファイル「test.tar」からバイナリを読み出して、バイナリからTarオブジェクトを作成します。(*3)では、tarファイルの中にあるファイルエントリの一覧を表示します。
まとめ
以上、tarファイルの構造を調べて、tarファイルを読み書きするプログラムを作ってみました。また、tarファイルの構造が、ヘッダーとデータの繰り返しから成るということが分かっていれば、プログラムの内容がよく分かるのではないでしょうか。複数ファイルを一つにまとめたい場面というのは意外と多いものです。そんなとき、tar形式を活用してみてください。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。これまで50冊以上の技術書を執筆した。直近では、「大規模言語モデルを使いこなすためのプロンプトエンジニアリングの教科書(マイナビ出版)」「Pythonでつくるデスクトップアプリ(ソシム)」「実践力を身につける Pythonの教科書 第2版」「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」など。