今回紹介するツール「Splunk Machine Learning Toolkit(以下、MLTK)」は、ログデータの検索・分析・可視化ソフト「Splunk」の拡張機能です。このツールも、コードを書くことなくGUI上で機械学習が可能です。大きな特徴は「Splunk上でシームレスに機械学習可能」「分類問題・回帰問題等の分析や異常検知が可能」の2点です。
今回は基礎編として、あらかじめ用意されているサンプルのデータとシナリオを用いて、MLTKで分析する手順を紹介します(本稿で利用するバージョンはSplunk Enterprise 8.0.0、MLTK 5.0.0)。
SplunkとMLTK
Splunkは、さまざまな機器から出されるあらゆるログを収集してインデックス化し、リアルタイムで高速に検索・分析できるソフトウェアです。さらに、ダッシュボードで検索・分析結果を可視化できるため、機器のトラブル対応やセキュリティインシデント調査などの分野で幅広く使用されています。
Splunkでは、「Apps」と呼ばれる拡張機能セットが、自社製・サードパーティ製を含めて数多く公開されています。今回紹介するMLTKは、Splunk社が2016年から公開している無償Appsです。
MLTKは、SplunkのGUI画面を通して、Pythonのアルゴリズムをベースに機械学習モデルを作成するツールです。Splunkに取り込んだデータを用いて、分類問題や回帰問題などの分析や異常検知の機械学習が可能です。
利用に際しては、Splunk EnterpriseのAppsからMLTKを選択してインストールすると、Apps一覧にMLTKが表示され(図1)、すぐに利用できます。
-

図1:Splunk Machine Learning Toolkit App

事前に用意されているサンプルデータセットと分析の種類
MLTKには、手法別・産業別のケースシナリオで用意されたサンプルデータ「Showcase」が数十個用意されており、チュートリアルに沿って使用感や効果を試すことができるようになっています。
「My Operation」を選択すると、手法別の4ケースが表示されます(図2)。
- Predict Fields:数値または分類の予測
- Detect Outliers:数値または分類の外れ値検知
- Forecast Time Series:時系列データの将来予測
- Cluster Events:イベントのクラスタリング
-

図2:手法別サンプルケース

「Industry」を選択すると、以下のように、産業別の6ケースが表示されます(図3)。
- IT:サーバ電力消費量予測、HDD障害予測、サーバ応答時間外れ値検知など
- Security:従業員ログイン数の外れ値検知、VPN使用量予測、ビットコイン取引の外れ値検知など
- Business Analytics:持ち家価値予測、テレコム顧客の解約予測、販売店の購入外れ値検知など
- IoT:発電所のエネルギー出力予測、車両メーカーとモデル予測、携帯電話利用の外れ値検知など
- Health:糖尿病予測、糖尿病患者の記録の外れ値検知など
- Finance:住宅ローン契約の外れ値検知、為替レート予測など
-

図3:産業別サンプルケース

Showcaseのサンプルデータで機械学習を体験
ここからは、Showcaseの「Predict the Presence of Malware」のサンプルデータを用いて機械学習(教師あり機械学習の分類推測)を進めていきます。このシナリオでは、ファイアウォールのトラフィックログのサンプルデータから、あるトラフィックがマルウェアによるものかどうかを判定します。
(1)データを読み込む
今回使用するデータ「firewall_traffic.csv」を読み込みます(図4)。構文はあらかじめ入力されています。
-

図4:サンプルデータの読み込み

(2)アルゴリズムを選択
「Algorithm」のプルダウンメニューからアルゴリズムを選択します。デフォルトでは「LogisticRegression」が選択されており、このままにします。なお、その他に選択できるアルゴリズムとして、「SVM」「RandomForestClassifier」「GaussianNB」「BernoulliNB」「DecisionTreeClassifier」があります。
(3)目的変数(予測したいフィールド)を選択
「Field to predict」のプルダウンメニューから、予測したいフィールド(目的変数)を選択します。今回は、マルウェアが使われているかどうかが記載されているフィールド「used_by_malware」を選択します。
(4)説明変数(予測に使うフィールド)を選択
「Fields to use for predicting」のプルダウンメニューから、予測に使うフィールド(説明変数)を選択します。今回は目的変数以外のすべてのフィールドを選択します。
(5)トレーニング用データとテスト用データの分割比率を決定
作成される機械学習モデルの予測精度を確認するため、サンプルデータをトレーニング用データとテスト用データに分割します。トレーニング用データで機械学習モデルを作成し、テスト用データで目的変数を予測します。なお、テスト用データには目的変数の実際の値も含まれているので、予測した値と比べて精度を測ることができます。
このトレーニング用データとテスト用データの分割比率は、「Split for training / test」のスライダーで指定します。デフォルトでは70:30となっており、今回もその値を指定します。ここまでの設定を行うと、図5のようになります。
-

図5:機械学習の設定

(6)機械学習モデル作成とその評価
図の「Fit Model」ボタンをクリックすると、機械学習モデルが作成されます。機械学習モデルによる予想結果とその評価はダッシュボード上で表示されます。
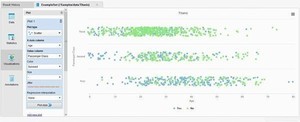
Prediction Resultsでは、目的変数の正しい値と予測値、またその他のフィールドを確認できます。目的変数の正しい値と予測値が異なる場合には緑色で表示されます。(図6)
-

図6:機械学習による予測結果

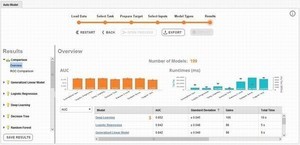
また、得られた予測値と正しい値を用いて、作成した機械学習モデルの評価が計算されます。具体的には、Precision(精度、適合率)、Recall(再現率、検出率)、Accuracy(正解率)、F値(PrecisionとRecallの調和平均)、実際の値と機械学習が予測した値を表にまとめたConfusion Matrix(混同行列)が表示されます(図7)。
今回の例ではマルウェアの検出が重要視されるため、マルウェアの見逃しが少ない機械学習モデルが優秀であると考えられます。もしも、満足できるモデルが作成できなかった場合は、使用する機械学習アルゴリズムや説明変数を変更するなど試行錯誤することによって、機械学習モデルを改良できます。
また、簡単な前処理機能も用意されているので、データの内容を理解した上で利用してみると、機械学習モデルを改善できるかもしれません。


図7:機械学習モデルの評価


今回は、あらかじめSplunkに用意されているサンプルデータを用いて、MLTKで分析する手順を紹介しました。次回は、新たなデータセットをSplunkに投入してMLTKを活用する事例を紹介します。
著者プロフィール
知念 紀昭
ネットワンシステムズ株式会社
ビジネス開発本部 第1応用技術部
仮想化ハードウェア・ソフトウェアの評価・検証業務、クラウドソリューション業務などを経て、現在は機械学習ビジネスを担当している。