今回も以下のように、前回と同じSQLのチューニングを行います。
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < '1995-03-15'
and l_shipdate > '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate;
前回は、各テーブルに統計情報を取得したほか、HASH分散を行いDMS(ノード間データ移動)の発生を抑制しました。その結果、何もしていなかった時よりも65%高速化できることを確認しました。
このSQLはまだチューニングの余地がありそうなので、今回もこのSQLをベースにチューニングの手法を紹介します。
パーティション分割の検討
SQL Data Warehouseでは「パーティション分割」の機能が用意されています。パーティションの機能はさまざまなRDBMSで実装されており、SQL Data Warehouseでも利用可能で、主に以下の2点の目的で利用します。
- データのメンテナンス
- パフォーマンスの向上
パーティションの分割を行えば、データのメンテナンス性能とパフォーマンスの向上につながる可能性がありますが、パーティションの数を多くしすぎると逆にパフォーマンス低下につながってしまいます。特にクラスター化カラムストアインデックスに対してパーティション分割を行う場合は、この「多すぎるパーティション」は要注意で、1パーティション当たり最低でも6000万件以上のデータが必要になります(詳しくは第7回を参照してください)。
それでは、今回作成したlineitemテーブルのl_shipdate列でパーティション化を検討してみましょう。私の作成した環境ではl_shipdate列の年、月ごとに以下の件数が入っていました。
表1 l_shipdate毎のlineitemのデータ件数(縦:月、横:年)
| 1992年 | 1993年 | 1994年 | 1995年 | 1996年 | 1997年 | 1998年 | 計 | |
|---|---|---|---|---|---|---|---|---|
| 1 | 9,582,148 | 77,319,033 | 77,306,651 | 77,304,390 | 77,307,322 | 77,301,612 | 77,303,389 | 473,424,545 |
| 2 | 26,893,471 | 69,832,618 | 69,816,217 | 69,825,985 | 72,315,505 | 69,838,587 | 69,830,218 | 448,352,601 |
| 3 | 47,917,745 | 77,302,737 | 77,316,067 | 77,306,194 | 77,292,910 | 77,310,943 | 77,323,239 | 511,769,835 |
| 4 | 65,236,395 | 74,821,333 | 74,808,528 | 74,821,757 | 74,804,418 | 74,820,828 | 74,814,999 | 514,128,258 |
| 5 | 77,295,226 | 77,301,237 | 77,296,790 | 77,301,141 | 77,313,822 | 77,311,481 | 77,302,598 | 541,122,295 |
| 6 | 74,798,314 | 74,818,781 | 74,819,580 | 74,821,200 | 74,812,722 | 74,801,290 | 74,806,715 | 523,678,602 |
| 7 | 77,320,352 | 77,300,917 | 77,309,443 | 77,291,896 | 77,310,877 | 77,295,345 | 77,304,720 | 541,133,550 |
| 8 | 77,287,819 | 77,299,704 | 77,333,931 | 77,314,714 | 77,292,832 | 77,312,581 | 68,945,856 | 532,787,437 |
| 9 | 74,816,010 | 74,805,164 | 74,810,885 | 74,818,904 | 74,816,308 | 74,816,704 | 47,921,137 | 496,805,112 |
| 10 | 77,305,995 | 77,301,525 | 77,301,536 | 77,297,505 | 77,301,405 | 77,312,406 | 30,035,274 | 493,855,646 |
| 11 | 74,826,553 | 74,817,419 | 74,811,820 | 74,801,185 | 74,798,002 | 74,825,366 | 10,202,979 | 459,083,324 |
| 12 | 77,314,444 | 77,300,381 | 77,312,674 | 77,303,751 | 77,296,519 | 77,299,954 | 20,781 | 463,848,504 |
| 計 | 760,594,472 | 910,220,849 | 910,244,122 | 910,208,622 | 912,662,642 | 910,247,097 | 685,811,905 | 5,999,989,709 |
この表からは、年月でパーティション分割を行うと、1998年9月や10月は6000万件を下回っていることを確認できます。
また、本テーブルは前回にHASH分散を行いましたが、各ディストリビューションでデータが偏っている可能性があります。パーティション分割する際の「6000万件を下回らないようにする」という条件は、「各ディストリビューションで100万件を下回らないようにする」ことの絶対条件となります(100万件×60ディストリビューション=6000万件)。
しかし、ディストリビューションでの偏りが多少発生することも想定すると、ぎりぎり6000万件のデータをパーティション分割するよりも、少し余裕を持たせた範囲でパーティション分割するほうが安全です。以上により、今回の例では「年月」でパーティション分割するのではなく、年単位でパーティション分割します。
パーティション分割の方法
SQL Data WarehouseではSQL Serverと高い互換性のあるDatabase Serviceですが、パーティション分割に関してはSQL Serverでのパーティション分割とは作成の方法が少し異なり、定義が簡略化されています。
SQL Serverではパーティション分割する際、パーティション関数やパーティション構成を定義しなければなりませんが、SQL Data Warehouseでは定義する必要はありません。SQL Data Warehouseでのパーティション分割の構文は、パーティション分割を行う列と、パーティション分割の境界点の定義のみで、パーティションの構成が可能です。1つのテーブルに対して、1つの列のみパーティション化を行えます。また、境界点に対して「RANGE RIGHT」または「RANGE LEFT」を指定します。
では、lineitemテーブルのパーティション分割を行ってみましょう。
CREATE TABLE lineitem_PARTITION
WITH
(
DISTRIBUTION = HASH ( l_orderkey ),
CLUSTERED COLUMNSTORE INDEX,
PARTITION (l_shipdate RANGE RIGHT FOR VALUES(
'1992/01/01',
'1993/01/01',
'1994/01/01',
'1995/01/01',
'1996/01/01',
'1997/01/01',
'1998/01/01'
)
)
)
AS SELECT * FROM lineitem;
RENAME OBJECT lineitem to lineite_NON_PARTITION;
RENAME OBJECT lineitem_PARTITION to lineitem;
CREATE STATISTICS Stat_lineitem_l_orderkey ON lineitem(l_orderkey);
CREATE STATISTICS Stat_lineitem_l_shipdate ON lineitem(l_shipdate);
前回もお伝えしたように、統計情報は必ず取得するようにしましょう。また、上記のコマンドのようにクラスター化列ストアインデックスをパーティション分割により再構成をする時は、比較的大量のメモリを必要とします。SQL Data Warehouseで使用できるメモリ量をコントロールするために、リソースクラスをデフォルトのsmallrcから、largercなどに切り替えて実行するようにしてください。
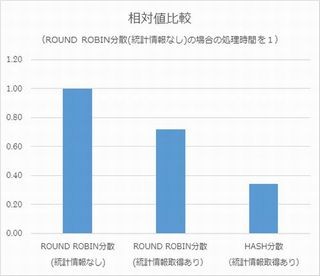
結果
それでは、パーティション分割によりどれくらい高速化できたか結果を確認してみましょう。結果は以下の通りです。

|
上記の通り、巨大なテーブルをパーティション分割することでクエリは高速化されました。SQL Data Warehouseでは大容量、大量の件数のテーブルとなることも多いと思います。パーティション分割を正しく利用すればクエリは高速化できるので、大量の件数が格納されているテーブルなどはパーティション分割を検討するようにしましょう。
山口 正寛
1984年生まれ。大阪府出身、東京都在住。データベースエンジニア。SQL Server、Oracle、MySQL、PostgreSQLなどのデータベースで、小規模から大規模な案件まで数多く経験。現在ではクラウドの流れに逆らうことなく、「データベース×クラウド」をキーワードに案件対応、セミナー活動、執筆活動など幅広く活動中。株式会社システムサポート所属。