
第7回で紹介したように、デジタルフォレンジック調査を行うと、膨大な量のデータが証拠(もしくはその候補)として、検出される。そこで指摘したが、到底、人手で処理できるものではない。そこで、フォレンジック調査では、AI機能を活用したツールが使われる。
今回紹介するのは、デジタル証拠調査分析ソフトウェアのNuixである。その目的を一言でいえば、莫大な証拠データの調査・関連付けを高速、かつ効率的に行い、証拠の最重要部分を抽出することにある。
今回は、AOSデータの一居政宏氏に、デモを披露していただき、さらに最近のフォレンジック調査についてお話をうかがった。
Nuixの前処理:保全と推定
さて、いきなりNuixによる調査・分析を行うのではない。フォレンジック調査のもっとも重要な手順である「保全」といった前提作業が必要となる(保全については、こちらを参照)。
一般的には、不祥事や不正が発生した場合には、まず、カストディアン(調査対象者)を決める、もしくは数名に絞り込む必要がある。他にも、情報漏えいであれば、どんな情報が漏えいしたのか、その規模なども100%ではないにしろ、ある程度、見当を付けておく必要がある。そうしないと、膨大なデータをどう絞り込んでいくか、その方針すら立たない状態になる。まるで、地図もなく、山中を歩き回るようなものである。
カストディアン(調査対象者)を決めたら、どのデータを取得するかを決める必要がある。カストディアン(調査対象者)がどのパソコンを使っていたのか、それともスマホを対象とするのか、どこからデータを抽出するかを決めなければいけない。ここが第一段階の話になる。
そのためのツールの1つとして、本誌ではAOS Fast Forensicsを紹介した。USBメモリから起動し、高速モードを使えば、専門家でなくても、不正行為の実態に迫ることができる。そして、重要なのが最後の保全である。裁判で証拠として採用されるためには、改ざんが行われていないことなどが求められる。そこまでの作業をワンストップで行えるのが、AOS Fast Forensicsである。
こうして、AOS Fast Forensicsを使い、調査対象者が3人であったとしよう。当然であるが、その3人が普段、使用していたパソコンは特定されるし、どの記憶媒体(HDD)などを保全すれば、よいかもわかる。パソコン以外にもスマホや携帯端末なども調査対象になるかもしれない。さらに、メールを調査対象とするのであれば、どのメールサーバーを対象とするのかといったことをあらかじめ、決定しておく必要がある。
調査対象者が数名で留まればよいが、部署全体といったこともありうる。かなり絞り込んでいるようにも見えるが、これでもデータ量としては膨大なものとなることがほとんどである。
そして、ここからが、Nuixの出番となるのだ。
Nuixにデータを取り込み
図1は、Nuixを立ち上げたときの画面である。
-
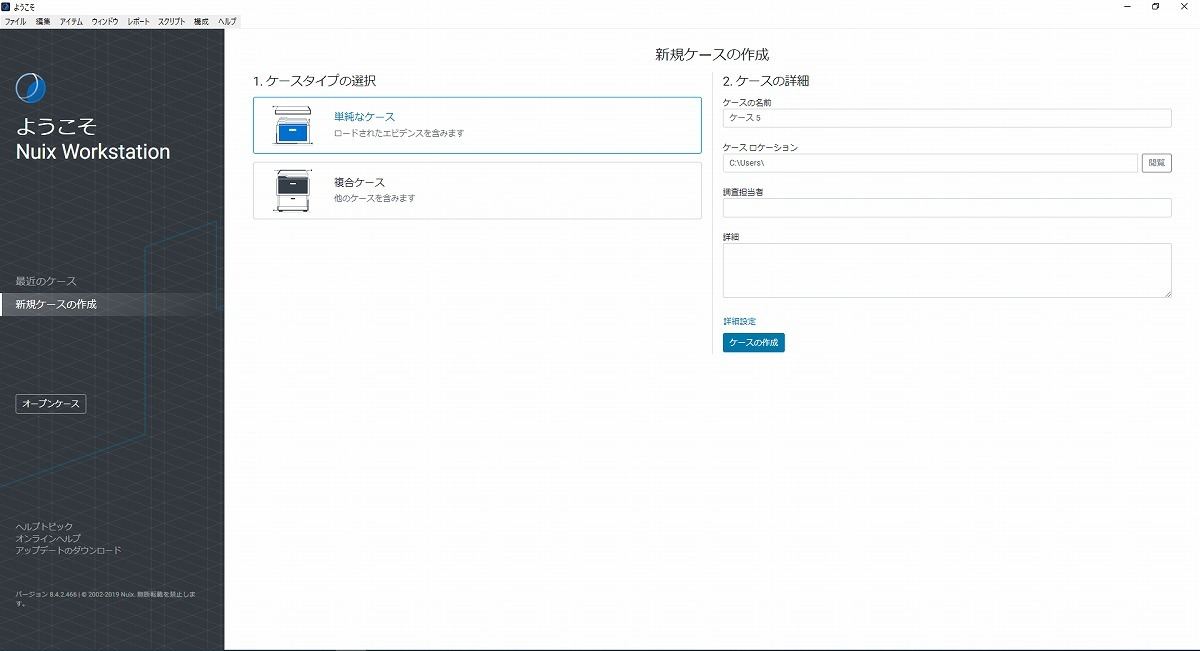
図1 Nuixの起動画面

「ケース」と呼ばれるものがいくつか並んでいる。Nuixでは、調査対象データを「ケース」と呼ばれる、まさに箱のようなオブジェクトを作成し、そこにデータを入れて処理をしていく。ここでは、すでに取り込まれたケースが存在する。
新規にケースを作成するには、図1の左のメニューから[新規ケースの作成]を選ぶ。
ケースのタイプや名前などを設定する。多くの場合、ケースタイプは[単純なケース]で問題ない。右下にある[ケースの作成]をクリックする。[ケースエビデンス追加]となる。[追加]をクリックし、プルダウンメニューの[エビデンス追加]を選ぶ。
-
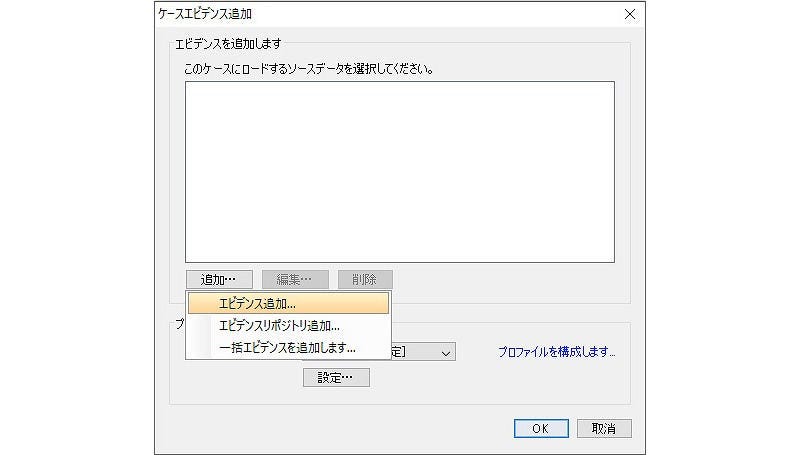
図2 ケースエビデンス追加

次いで、[エビデンス追加/編集]となる。
-
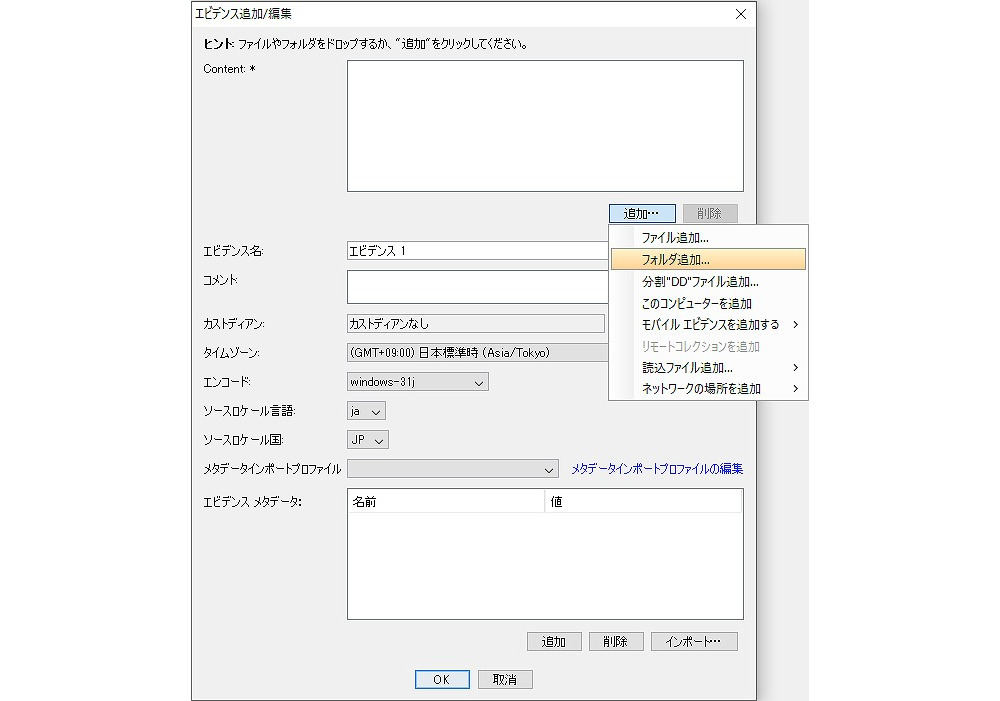
図3 エビデンス追加/編集

一番上のボックスに保全したファイルやフォルダをドロップしてもよいが、[追加]をクリックし、任意のファイルやフォルダを追加してもよい。[追加]からは、このコンピュータ全体やネットワークフォルダなども指定できる。いくつかの確認画面を経て、[プレフィルタ]となる。
-
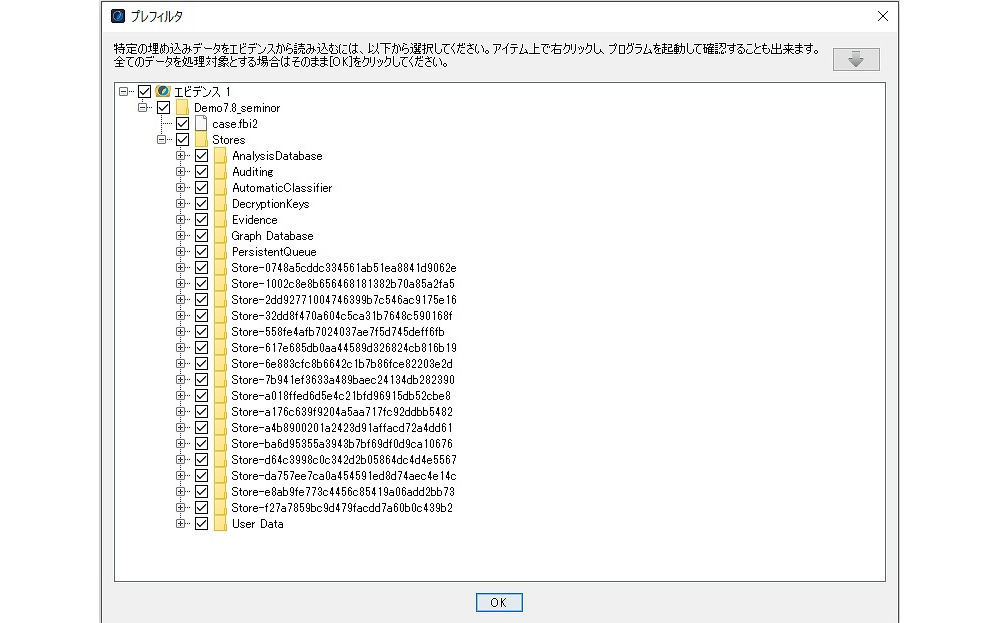
図4 プレフィルタ

実際に取り込まれるファイルやフォルダが表示される。[OK]をクリックすると、プロセスが開始される。
-
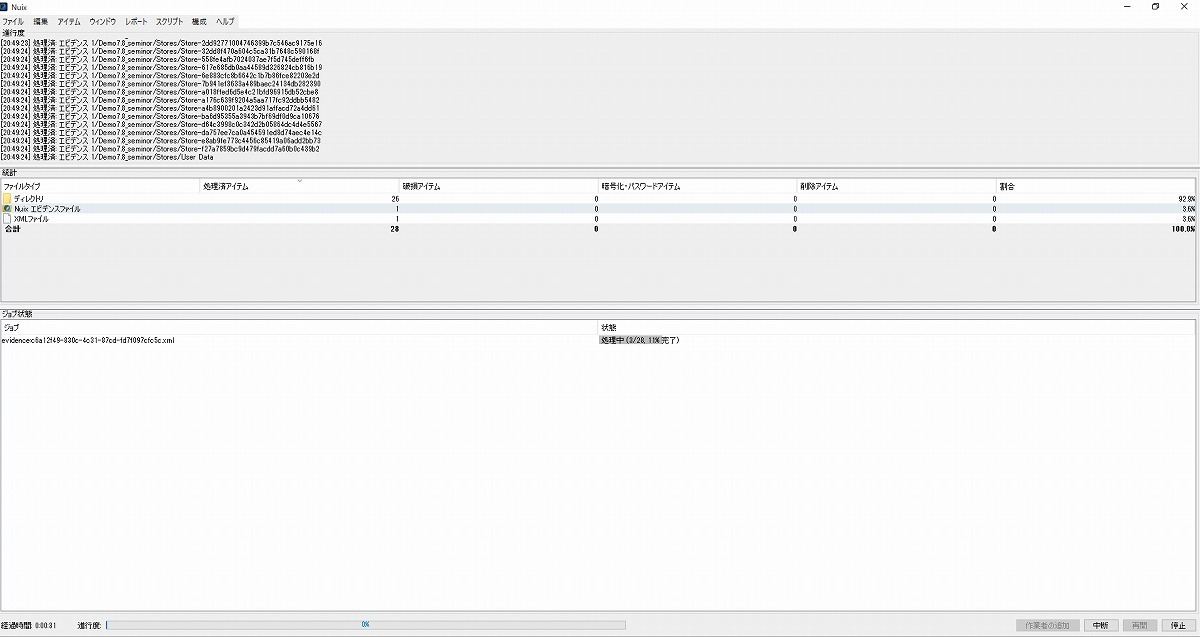
図5 取り込み中

ここでは、実際にデータの取り込みや復元などが行われる。この作業は、かなり時間がかかる。一居氏によれば、処理するデータの内容や、設定、PCのスペックによるが、10GBで3時間ほどかかるとのことだ。したがって、退社前の18時くらいから起動し、翌朝、見れるようにするといった作業手順が多いとのことだ。
Nuixに取り込まれたデータは、そのままでは検索できないので、プロセシングという作業を行って、インデックスを付けたり、メタデータを抽出する。
作業プロセスとしては、見ることはできない。しかし、この処理を行わないと大量のデータの調査・分析は難しい。そこをNuixが自動的に行っている。しかし、それなりのコンピュータリソースを必要とする作業となる。
データの絞り込み
図6は、今回のデモ用に用意したあらかじめデータを取り込んだケースである。
-
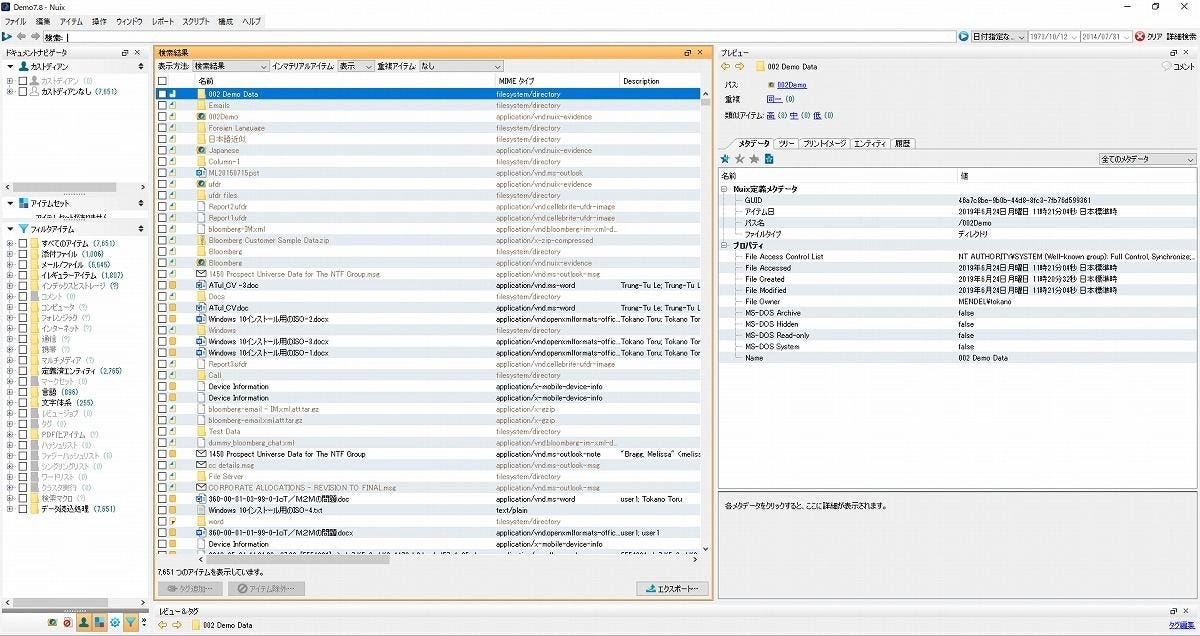
図6 データを入れたケース

図6の左側にカストディアン(調査対象者)が並ぶ。Aさん、Bさんといった感じで人名が並ぶ。ここでの作業は、カストディアン(調査対象者)を決め、どのデータを抽出するかを設定する(前述したように、この段階で調査対象者が絞り込まれていないこともある)。
図6をみると、中央のペインには、読み込まれたデータの検索結果の全リストが表示される。メールであったり、オフィスデータ、画像などさまざまなアイテムが並ぶ。この例では、すべてのアイテムが7,651件あり、そのなかにメールが約6,600件ある。ここから1つをクリックすると、右側のペインの[プレビュー]ペインに詳細が表示される。
-

図7 詳細を表示

メールやテキストの中身はもちろん、メタデータ(ファイルが持つ情報)やバイナリ情報などを表示させることができる。こういった内容をチェックすることで、調査を進めていく。
まずは、「キーワード検索」や「調査期間の設定」を行うことで、データの絞り込みが可能となる。ここでは、「価格」というキーワードで検索してみた。約6,600件あったメールデータを36件に絞り込むことができた。
-
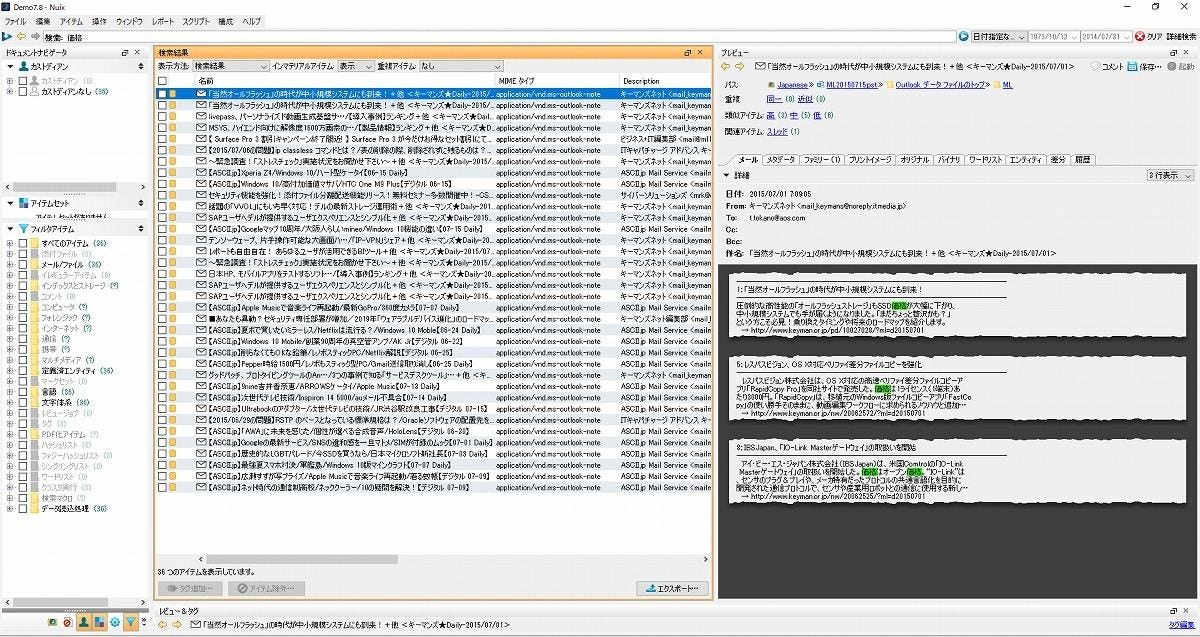
図8 キーワード検索による絞り込み

詳細には、「価格」の文字が含まれるメールデータが確認できる。このように36件になれば、1つ1つ確認することも決して不可能ではない。また、合わせて日付などの調査期間による絞り込みも可能である。「期間内」、「期間外」「以前」、「以後」といったプルダウンメニューが並ぶ。
-
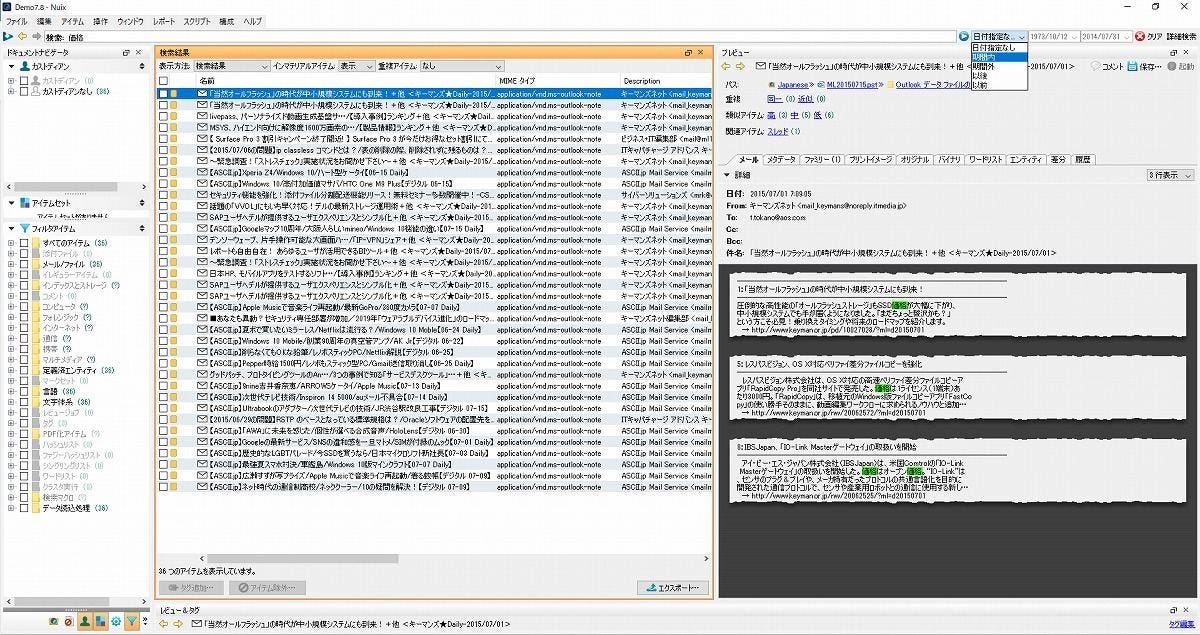
図9 調査期間による絞り込み

同時に日付を入力し、絞り込んでいく。
複数のパソコンからデータを保全し調査を行うと、かなりの頻度でデータが重複することがある。したがって、重複データの削除も効果的な絞り込みとなる。調査対象によっては、重複削除によって大幅にデータを削減することができる。
-
図10 重複削除

最初の7,651件のデータが6,281件となり、1,370件ほど削除された。一居氏によれば、調査対象にもよるが、最初に行ってもよい絞り込み作業とのことだ。
また、表示方法を変えることでも、絞り込みが可能となる。
-

図11 表示方法の切り替え

図12は、アドレスで、表示したものだ。
-
図12 アドレスで表示

アドレスごとにメールが表示される。たとえば「nuix.com」ドメインのデータは、47件ある。そこで、これを選択すると、「nuix.com」ドメインのデータのみが表示されるようになる。
-
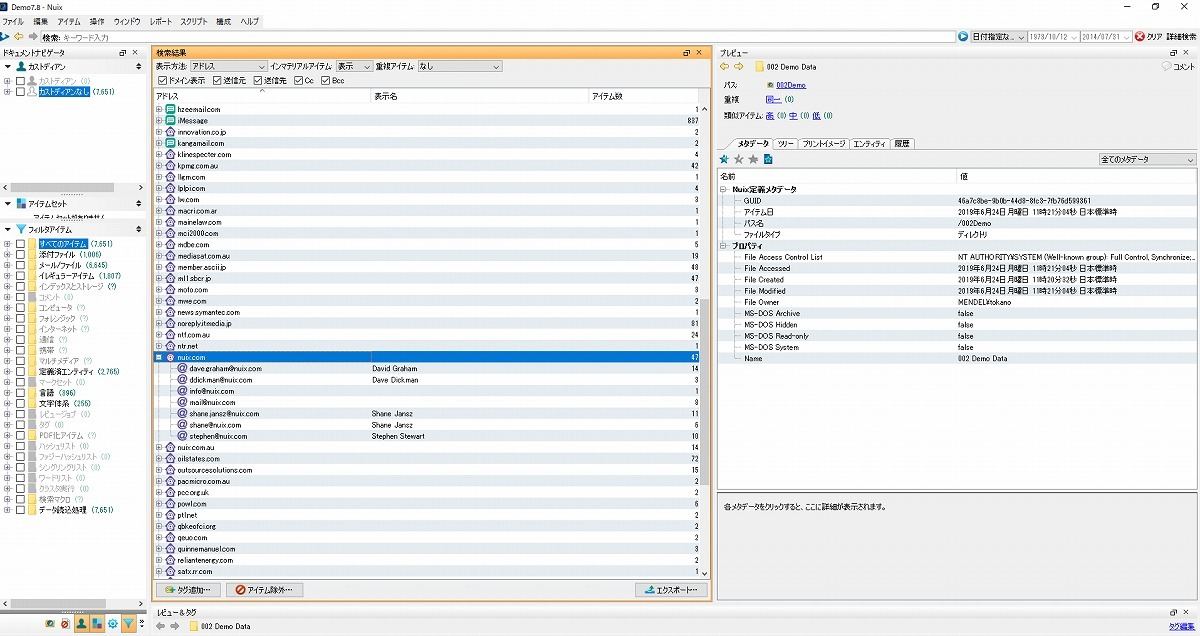
図13 「nuix.com」ドメインのデータ

このドメインを持つメールやデータだけを抽出することで、より範囲を限定して調査を行うことができる。
調査対象にもよるが、隠語での調査が必要になることもある。Nuixでは、その調査には[プレビュー]ペインの[ワードリスト]タブで行うことができる。
-
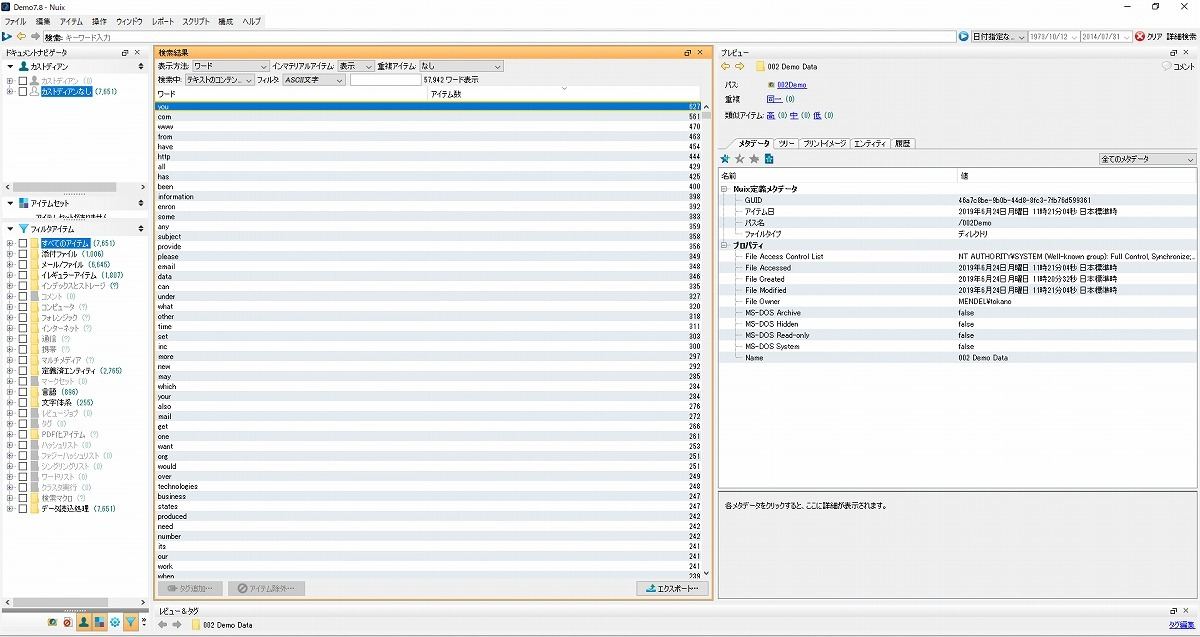
図14 [ワードリスト]タブ

頻出単語リストである。この例では英語であるが、もっとも頻出する単語をダブルクリックすると、それに関連するデータが表示される。
-
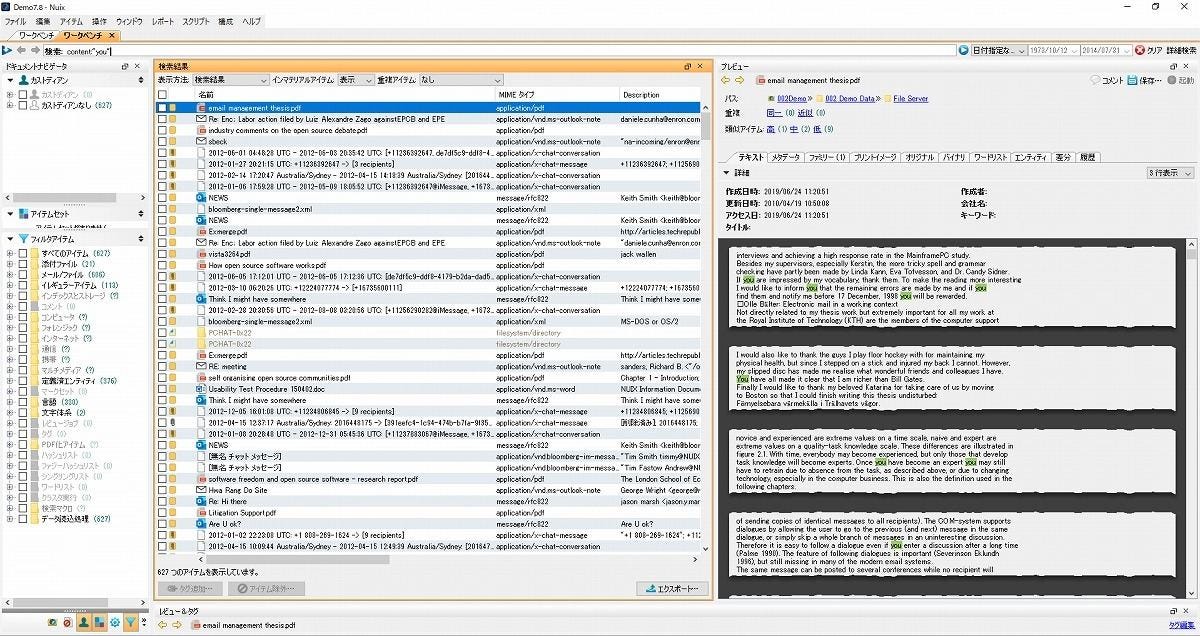
図15 頻出単語に関連するデータ

不正行為などでは発覚を恐れ、一般の人にもし見られても、それとわからないようにすることがある。たとえば「大麻」とあれば、薬物取引と推測しやすい。しかし、「野菜」では、犯罪取引とは気付きにくい(SNSを使った薬物取引などで若年層がよく使う手法のようだ)。こういった調査もできる点は、非常に興味深かった。
さまざまな調査方法があるが、不自然な単語が頻出している場合など、隠語を使って犯罪グループが意思疎通を図っている可能性もあるだろう。
このように複数の絞り込みを行い、人間が直接、チェックできるレベルまで絞り込みを行うのである。こうして、絞り込みをし、データチェックを行うのであるが、ここでも重要な機能がある。タグ付けである。
データをチェックしたら、適切なタグを付けていくのである。ここでは、いくつかに「関係無し」のタグを付けていく。このタグ付けであるが、関係あるデータと無関係なデータに分けることが主な目的である。多くの場合、関係ないデータがほとんどなので、タグ付けによってより必要なデータのみを取り出すことが可能になる。タグは、自由に設定できるが、もっとも使われるのは、図16の「関係あり」と「関係無し」である。
-

図16 ケースタグ編集

ここは人間の手による仕分けのような作業にあたり、やや手間のかかる作業となる。
-
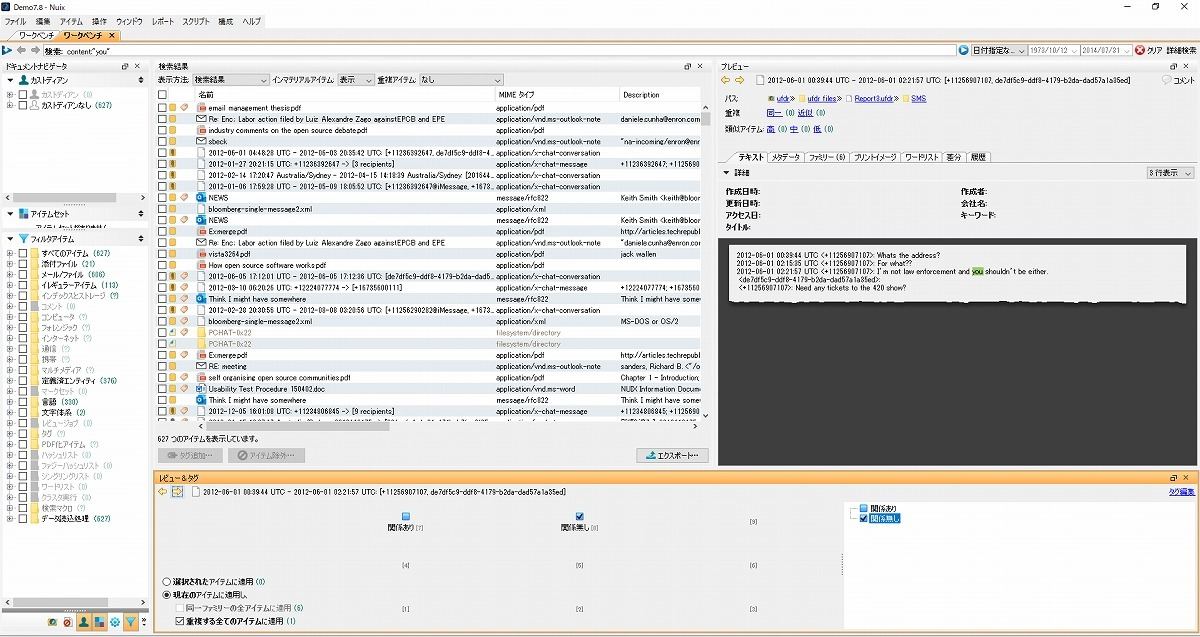
図17 タグの設定

しかし、最初にいくつかの仕分けを行うことで、この作業をAIに学習させることもできる。そして、その後の作業を自動化させることもできる。大量のデータを扱うには必須の機能ともいえるであろう。
図17の左のフィルタアイテムに[タグ]フィルタがある。そこで「関係無し」を付けたデータのみをチェックすることもできる。
-
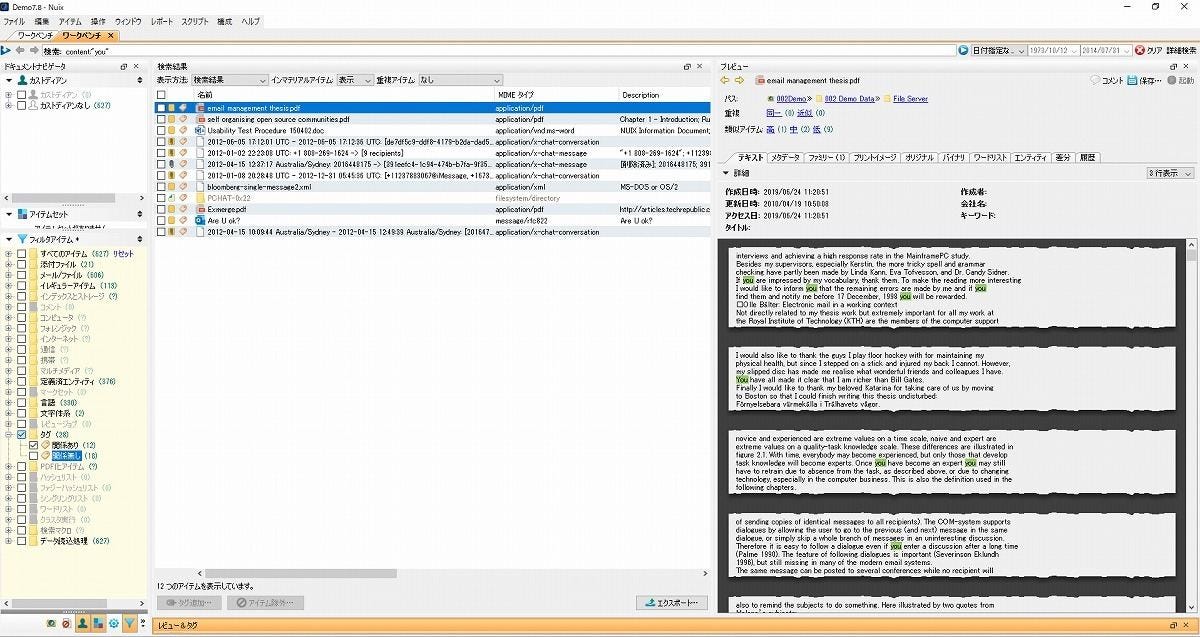
図18 「関係無し」タグを付けたデータの確認

逆に「関係あり」のデータのみをチェックしたり、任意に付けたタグのデータのみをチェックすることもできる。
まとめると、Nuix調査の初期段階では、すべてのデータをNuixに入れて、ファイルの種類、調査期間、キーワードなどで絞り込みを行っていく。そして、タグを付けた結果を、上司なりにセカンドチェックをしてもらう、という手順となる。
紙数もつきたようなので、今回はNuixの基本操作までを紹介した。次回は、よりビジュアルな分析結果を表示する機能(スキントーン、ネットワーク)などを紹介する予定である。



