米Googleは12月6日(現地時間)、大規模訓練による新しいAIモデル「Gemini」の提供開始を発表した。このモデルは、今年6月に開発者カンファレンス「Google I/O」で次世代の基盤モデルとして紹介されたもので、当時はまだ訓練中であった。Geminiは最初からマルチモーダルで訓練されており、Googleが行なったベンチマークで、32のテスト中30でOpenAIの「GPT-4」を上回ったという。Google DeepMindのCEO、デミス・ハサビス(Demis Hassabis)氏は「これはAIモデルにおける大きな飛躍である」と述べている。6日からチャットベースのAIツール「Bard」への展開を開始し、最終的にはGoogleのほぼすべての製品に導入する計画である。

Gemini 1.0は、以下の3つの異なるサイズに最適化されており、モバイルデバイスからデータセンターまであらゆる場所で効率的に実行できる。
- Gemini Pro:幅広いタスクに効率的に対応する汎用的なモデル。6日からBardへの導入を開始。
- Gemini Nano:オンデバイス処理のための最も小さな軽量モデル。
- Gemini Ultra:最大かつ最も高性能なモデル。エンタープライズ・アプリケーションやデータセンターの複雑なタスクに対応する。2024年初めに登場予定。

Gemini UltraのMMLU(機械学習モデル、特に自然言語処理モデルの理解力と推論能力を総合的に評価するために設計されたベンチマーク)スコアは「90.0%」。Googleによれば、Gemini UltraはMMLUで人間の専門家を上回った最初のモデルだ。GPT-4のMMLUスコアは87.3%である。その他、LLMの研究開発で広く使用されている32の学術的ベンチマークのうち30で、Gemini UltraはGPT-4を上回っている。
-
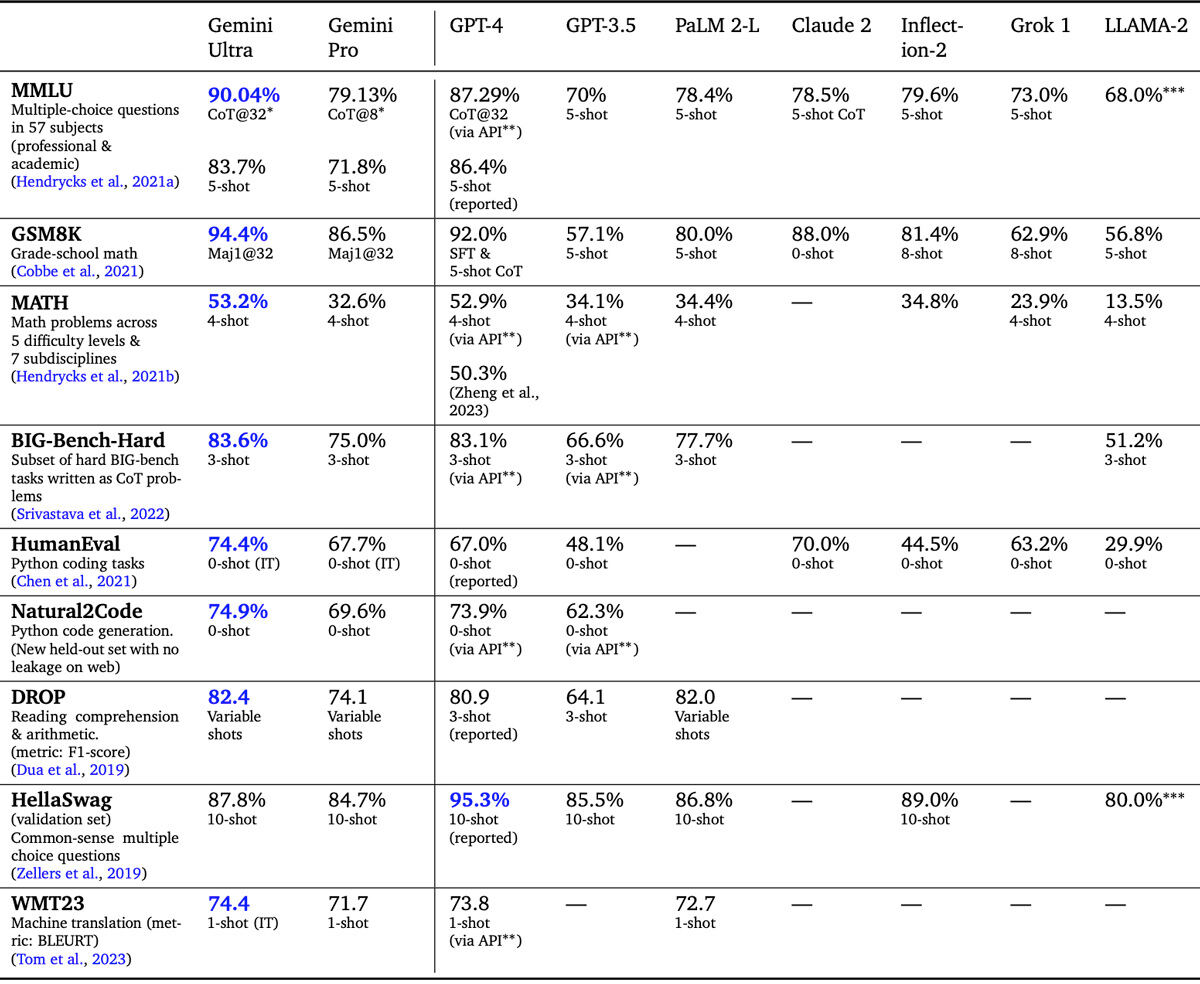
Gemini Ultra、Gemini Pro、GPT-4、GPT-3m、Claude 2、LLAMA-2などのベンチマーク・スコア

そうしたGeminiの優位性は、イメージや音声をより良く、複合的に理解する能力に由来している。従来のAIモデルは、マルチモーダルモデルを作成する際に、異なるモダリティごとに別々のコンポーネントをトレーニングし、それらを組み合わせていた。しかし、そうしたアプローチによるモデルは、たとえば画像を描写するような特定のタスクを実行するのは得意でも、より概念的で複雑な推論には苦労することがある。GoogleはGeminiを、異なるモダリティで最初から事前訓練されるマルチモーダル・ネイティブなモデルとして設計し、そして追加のマルチモーダルデータでファインチューニングを施して有効性を高めた。
-
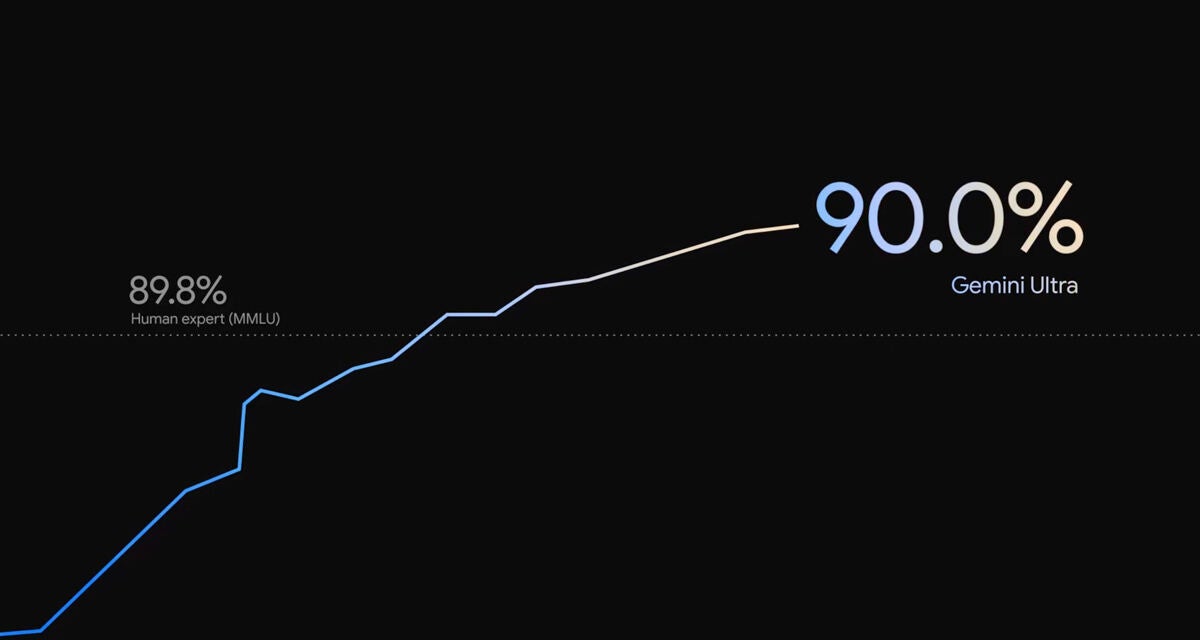
MMLUで人間の専門家(89.8%)を上回った

人が五感を用いて物事を理解するように、Geminiは多様な入力からの情報を読み取り、フィルタリングし、シームレスに理解する。それにより、微妙なニュアンスの違いをより良く理解し、複雑なトピックに関する質問に答える能力があり、既存のマルチモーダルモデルよりも膨大なデータの中から難しい知識を見つけ出すことに長けている。マルチモーダルモデルを評価するためにデザインされた新しいベンチマークMMMUのスコアは「59.4%」だ(GPT-4Vは56.8%)。
アイディアのブレーンストーミング、情報の検索など、マルチモーダルに優れたGaminiは人々の仕事や日常生活を幅広く支援できるが、中でもコーディングはその効果が顕著な分野になる。Gemini 1.0は、Python、Java、C++、Goといった人気のあるプログラミング言語を理解し、従来のAIツールよりも高品質なコードを生成する。
GoogleはAIコード生成システム「AlphaCode」をGeminiに特化した「AlphaCode 2」を構築した。競技プログラミングの問題を解く能力が大幅に向上し、複雑な数学や理論計算機科学の問題に対しても優れた性能を示している。AlphaCodeが約50%のコンペ参加者を上回るパフォーマンスであったのに対し、AlphaCode 2は85%のコンペ参加者を上回ると推定されている。
-

Pythonのプログラミング関数によるベンチマークで、Geminiの最初の正解率は75%(PaLM 2は45%)、さらにGeminiに回答の確認と修正をさせると90%以上に上昇した

そしてもう1つ、Geminiには効率的なモデルという特長がある。Googleは、Tensor Processing Units(TPUs) v4と、その新版であるv5eを使用したAIに最適化されたインフラストラクチャ上でGemini 1.0を訓練し、スケーラブル、安全かつ高効率でサービスを提供できるように設計した。TPU上でGeminiは、以前のより小型で性能の低いモデルよりも大幅に高速に動作する。

BardとPixel 8 Proで利用できるように
現時点でGeminiを体験できる方法は、BardとGoogleのスマートフォン「Pixel 8 Pro」の2つだ。
6日に展開が始まったBardは、Gemini Proによって、より高度な推論、プラニング、理解を提供できるようになる。これは170カ国以上で利用できるようになるが、現時点では英語によるテキストを用いたインタラクションに限られる。他の言語やモダリティについては、近々追加を開始する予定。また、最も高性能なモデルGemini Ultraを利用できる「Bard Advanced」を用意しており、間もなくテスター・プログラムを行い、2024年の初めの一般への提供を予定している。
「Pixel 8 Pro」では、Gemini Nanoによる「レコーダー」の録音内容の要約、Gboardのスマート返信を利用できるようになる。デバイス上で処理されるため、ネットワーク接続がなくても要約は生成される。
さらに、今後数カ月のうちに、Geminiは検索、広告、Chrome、Duet AIなど、より多くの製品やサービスで利用できるようになる。
開発者と企業顧客は、12月13日からWebベースの開発者ツール「Google AI Studio」またはGoogle Cloud Vertex AIのGemini APIを介してGemini Proにアクセスできるようになる。Gemini Ultraは、レッドチームなど広範な信頼性と安全性のチェックを終えており、ファインチューニングとフィードバック(RLHF)からの強化学習でモデルをさらに改良している。このプロセスの一環として、一部の顧客、開発者、パートナー、専門家にテスト提供してフィードバックを収集し、来年初めの開発者と企業顧客への展開を計画している。