
NVIDIAは「Ampere」アーキテクチャを採用する初のGPU「NVIDIA A100」を発表した。既に生産も本格化され、全世界に出荷中であるとのことだ。
-

NVIDIA A100

NVIDIA A100はデータセンター向けGPU。製造はTSMCの7nmプロセスでTSMCのCoWoSと呼ばれる3Dチップスタック技術によりチップとメモリを同一基板上に実装する。トランジスタ数は540億以上。GPUメモリはHBM2でその帯域は1.555TB/s。テラバイト級の帯域を実現する初のプロセッサと言う。容量も40GB搭載する。
-

NVIDIA A100の5つのキーフィーチャ

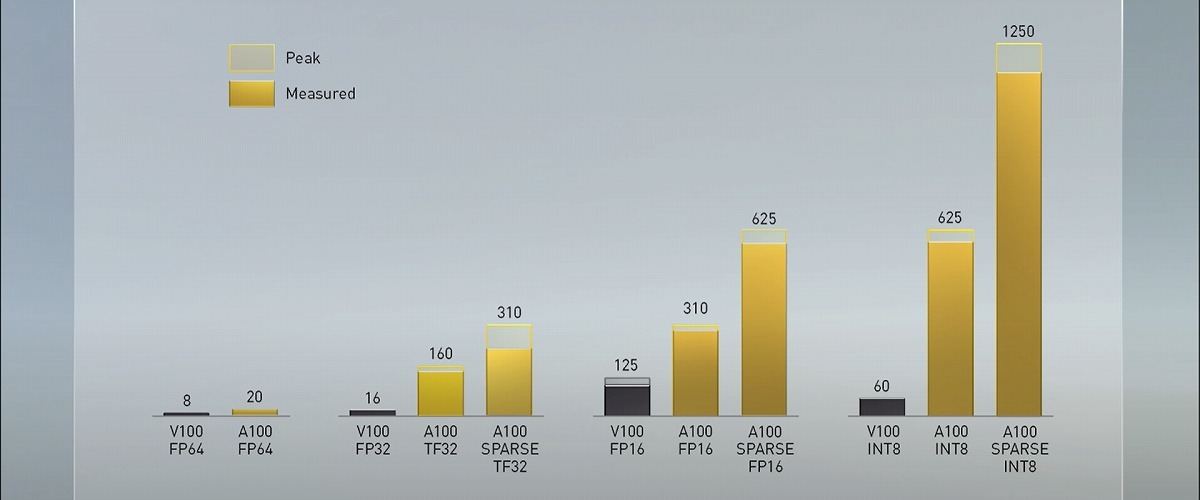
Tensorコアは第3世代。新たにTensor Froat 32(TF32)と呼ぶ数値表現をサポートし、コードを変更することなくFP32の精度を維持しながらAI性能を最大で20倍に向上させることが可能と言う。参考として示された性能値は、前世代V100のFP32性能が16 TTFLOPSに対し、A100のSPARSE TF32性能は312 TFLOPS。あわせてTensorコアがFP64に対応し、こちらはV100が8 TFLOPSに対しA100は19.5TFLOPSと、2.5倍の性能向上を果たしている。
-
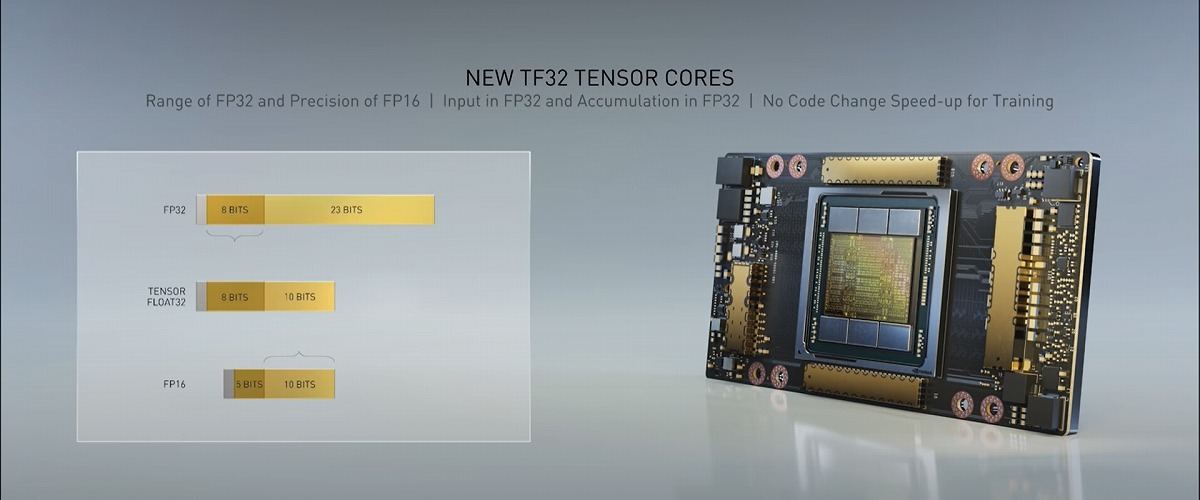
TF32をサポート

-

SPARSITYによるアクセラレーションにも対応

-
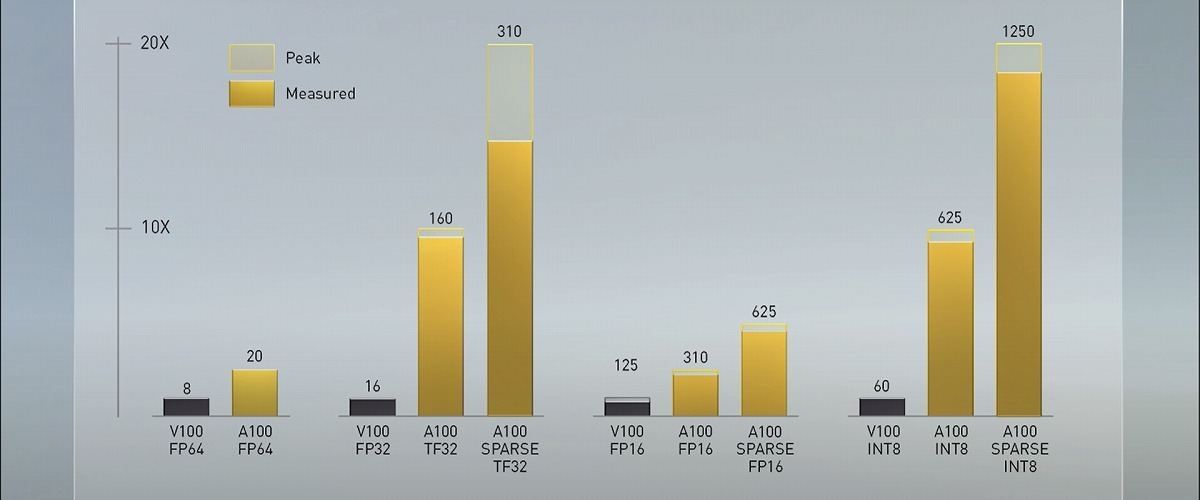
FP64、FP32、FP16、INT8など各種性能とV100を1とした際の性能比


新機能Multi-Instance GPU(MIG)もサポートされる。これは1つのA100 GPUを最大7つのGPUに分割して利用できるもの。大規模な演算では単一GPUとして、小規模で複数の演算では分割してといった具合に、規模に合わせて演算能力を調整することで利用率を最適化、投資効果を最大化すると言う。
-

Multi-Instance GPU機能

合わせてNVLinkやNVSwtchも第3世代となる。NVLinkは600GB/s。AIシステム向けの「NVIDIA DGX A100」ではNVLinkを介して8基のNVIDIA A100を実装する。320GBのメモリ、NVIDIAが買収したMellanoxの200Gb/s高速インターコネクト、15TBのGen4 NVMeストレージなどを搭載し、5P(ペタ)FLOPSの性能を1ノードで実現する。単一ラックに5台のDGX A100を搭載したシステムでは、従来のAI学習/推論データセンターシステムを20分の1の消費電力、25分の1のスペース、10分の1の費用に置き換えるとされる。DGX A100は199,000米ドルとされる。
-

NVIDIA DGX A100

-

DGX A100の各部スペック


-

25ラックのAIデータセンターを1ラックへ、630kWの消費電力を28kWへ、1,100万ドルのコストを100万ドルへ










