インテルは11月27日、都内でAIに対する最新の取り組みを紹介しました。一言でいえば、インテルの持つ多くの技術をAIに総動員するというものです。
インテル日本法人の執行役員常務 技術本部 本部長の土岐英秋氏は、AI関連の売上額は、同社グローバルではすでに35億ドルと大きな規模に成長していると言います。
-

インテル 執行役員常務 技術本部 本部長の土岐英秋氏

CPU/GPU/FPGA/ASICと多種多様な製品と開発ツールが強み
AIというとGPUや専用のNPU(Neural Processing Unit)を使うというイメージがありますが、実際には利用する用途に応じての使い分けが重要です。インテルはCPU/GPU/FPGA/ASICという幅広いハードウェアラインナップと性能を生かすための周辺技術、そしてハードの違いを気にせずに開発できるソフトウェアと検証環境まで、持ち得る技術の全てを使って全方位でAIに対応する考えを示しました。
-

汎用プロセッサから専用ASICまで幅広いハードウェアラインナップを揃えているのがウリ

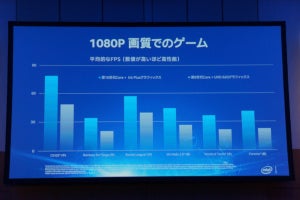
CPUでは「Deep Learnig Boost」によって従来の30倍の推論性能を実現し、「bfloat」というAI向けの高速演算が可能な数値表現を複数製品でサポート。コンシューマー向けのPCであっても、アドビ環境でモノクロ写真をAIでカラー化する作業を行った場合、競合のRyzen 7よりも同社のCore i3の方が最大4.3倍速く作業ができるとアピールします。
-

モノクロ画像をAIで着色というシーンならば、CPU単独のRyzen 7よりもCPU+iGPUのCore i3の方が速いとアピール

FPGAに関してはエッジ用途で最近特に注目されています。これは電力効率がGPUよりも高く、高速処理が行えるだけでなく、ASICと違って機能が固定化されていないので状況によって全く別の処理にも対応できるから。
インテルは自社内に多くの技術を所有しているため、単にCPUやFPGAと言ったパーツにとどまらず、メモリやチップ間、機器間の接続など幅広い分野でトータルでの性能アップが行えることが強みです。メモリに関してはNANDメモリよりも速く、DRAMよりも安価で大容量の3Dクロスポイントメモリを持り、DIMMやSSDに組み込んだ製品を揃えています。また、ボード上のASICに統合されたメモリを別のASICからも直接見えるようにした接続技術や、ボード間、ラック間で接続する技術もあります。
-

ボード内、ユニット内のASICユニットの内部メモリを自らのメモリ空間し、データの流れを高速化

それらに加えて大きな強みが、ソフトウェア技術です。CPUの性能が目に入りがちですが、インテルのコンパイラ最適化技術は定評があります。同社のSDK「OpenVINO」は異なるアーキテクチャでも一つのソースファイルで開発可能なので、柔軟にAIシステムを構成できるというメリットがあります。
-

OpenVINOプラットフォームで、アーキテクチャの異なるハードウェアを一つのソースファイルで活用可能

次世代の製品は? ワット性能、面積あたり性能でエッジ向け強調
ASICでは次世代のMOVIDIUS VPUとして「KEEM BAY」を来年第1四半期に投入予定。これはチップ単体、M.2やPCIeカードと柔軟な形状で製品化され、競合の「NVIDIA TX2」の4倍の速度と6.2倍の電力効率、8.7倍の小型化を実現でき、エッジAIのために設計されたといいます。
-

次世代MOVIDIUS VPU「KEEM BAY」はワット性能が高くかつ小型でエッジAI向け

もう一つの新製品が「Nervana」と呼ばれるニューラル・ネットワーク・プロセッサです。推論用に投入されるのが「NNP-I」と呼ばれる製品で、今年は限定された顧客向けに投入され、公開された製品写真を見るとM.2形状での提供もあるようです。現時点で最高のワット性能を誇るといいます。学習用の「NNP-T」も今年中に生産を開始し、こちらはスケーラブルに性能を上げる結合能力が魅力となっており、10ラックに480枚のカードを収めたデモも行われたといいます。
-

NERVANAニューラルネットワークプロセッサは学習用と推論用の2種類が登場し、どちらも今年中に限定的な顧客に出荷されます

-

学習用のNNP-T 480台を10のラックに収めた構成ですが、これらのボード間、ラック間の転送能力を備えており、他のスイッチを必要としません

最後に紹介されたのが新しいGPUとなる「Xe」アーキテクチャで、ウルトラモバイルからHPCまでの幅広い用途を一つのアーキテクチャでサポートし、Xeをベースとした「PONTE VECCHIO」と呼ばれる製品では、製造プロセスに7nmの次世代プロセスを用い、チップを垂直統合する新たなパッケージング、そして、CXL規格ベースの内部コネクション「Xeリンク」が使われます。
-

新しく登場するXeアーキテクチャはGPUながらウルトラモバイルからHPCまで一つのアーキテクチャで対応

-

XeアーキテクチャのPONTE VECHIOがいつ登場するのかは未定。7nmやForerosの技術を使うとあるので、登場が遅れそうな心配も

インテルが「データセントリックな会社になる」と宣言してからかなり経ちますが、AIビジネスという観点でいうと。いくつか出ていたピースがソフトウェア技術でキレイにまとまった感があります。今回の説明は、今後の展開に期待が持てる内容に見えました。