
-

話した言葉がそのまま文字に。Googleの音声文字変換アプリ「Live Transcribe」。Google Playでベータ版が提供中

音声変換を10年前から続けてきたGoogleが、2019年2月に聴覚障害者向けの音声文字変換アプリ「Live Transcribe」(ベータ版)をリリースし、その技術セミナーが日本で3月28日に開催された。世の中には多くの音声変換技術が登場しているが、このLive Transcribeは何が新しいのか、どんな用途を目指して開発されたのか。裏側をひもといていこう。
リアルタイムで70の言語・方言を文字に変換
Live Transcribeは、現在Google Playでベータ版が配付されているアプリで、Android 5.0(Lollipop)以上で動作する。
このアプリは、スマートフォンのマイクから拾った音声をリアルタイムで文字変換してくれるのだが、同じ音声入力・変換でも、Google音声入力と違い、話し言葉をほぼ1文字単位で拾って逐次変換してくれる、リアルタイム性の高さがポイントだ。対応する言語・方言は70以上と、幅広い言語に対応している点もポイントだ。
-
アプリ自体はGoogle Playでベータ版として配付中だ。動作環境はAndroid 5.0以上で、数年前の機種でも軽快に動作する

特にスイッチなども存在せず、普通にスマホに向かって話しているだけでどんどん文字に置き換わる。また、文脈をきちんと把握して変換してくれるので、意味の通らない不思議な変換になることも少ない。変換が終わったように見えた後でも文脈を確認して、変換結果が変わることもある。
仕組みについては後ほど詳しく説明するが、基本的に変換はクラウド上で行われるため、利用にはインターネット接続が必須となる。回線速度はそこまで早くなくても、サクサクと変換される様が小気味良いので、ぜひ一度インストールして確かめてみてほしい。
-

セミナーの冒頭でグーグル広報の挨拶がどんどん変換されていく様がデモンストレーションされた。話し言葉のスピードでも問題なく、ほぼリアルタイムにサクサクと変換される。なお、日本語では句読点をサポートしていない

AIの力で聴覚障害者をサポート
技術説明のために登壇した、同社シニアプロダクトマネージャのサガー・サブラ氏は、元々このアプリは、聴力にハンディキャップを負った人々のためのコミュニケーションツールを作ることを目標に開発したという。
-

インド出身のサブラ氏は、インドにある22の公用語のひとつ、グジャラート語を話す地域の出身。Live Transcribeはグジャラート語にも対応しているため、サブラ氏の祖父母も耳が遠くなってきているが、Live Transcribeを使ってコミュニケーションが取れているという

サブラ氏によれば、病気や事故、加齢によって、世界中で聴力にハンディを負っている人の数は、国連の推定で、日本の人口の約3.7倍にあたる約4億6,600万人。これらの人々を1つの国だと想定すると、中国・インドに続く世界3位の人口になるという。
これだけのハンディキャッパーが現実におり、人口増加率などを考慮すると、2055年には9億人に達するという見込みなのだ。このため、AIなどの技術を使ってこうした人々のコミュニケーションをサポートすることは、ひとつの国を救うにも等しい壮大な事業になるというわけだ。
また、サブラ氏には、こうした技術は先進国のためでなく、発展途上国で役立ててほしいという思いもあったという。それだけに最新の端末だけでなく、ちょっと古かったり、パフォーマンスの低めな端末でも軽快に動作することを念頭に開発が進められた。非常に志の高いアプリと言えるだろう。
-

世界中で聴力にハンディを負っている人の数は、国連の推定で約4億6,600万人だという。日本の人口の約3.7倍にあたる人数だ

-

Live Transcribeの特徴

音声はどうやって文字に変換される?
それでは、Live Transcribeの変換について、技術的な側面からも見ていこう。
実はこのアプリでは、端末内(ローカル)とクラウドの両方で、音声から文字への変換が行われている。具体的には、まず端末側でニューラルネットワークを使い、音声データがどんな種類の音なのか、570ものジャンル分けがなされるという。話し声、笑い声といったものから、犬の吠え声、赤ん坊の泣き声、皿の割れる音……といった具合だ。
こうしてラベル付けされた音は、クラウドに送られて、RNN(Recurrent neural Network:再帰型ニューラルネットワーク)ベースの自動音声認識システム(ARS:Automatic Recognition System)にかけられる。RNNは、自然言語処理において高い効果があるとされるアルゴリズムの一種だ。
ARSでは、送られてきたデータをアコースティックモデル、発音モデル、言語モデルの3段階を通じて言語処理する。こうして音声ファイルがテキスト化されて端末に送られ、端末のディスプレイに表示されるのだ。言語モデルの開発には、聴覚障害者専門の大学である米ワシントンD.C.のギャローデット大学の協力を受けているという。
-
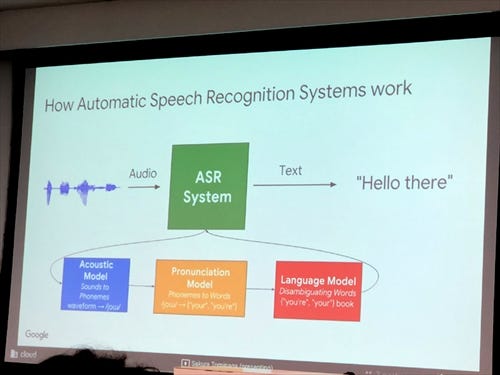
まず送られてきた音声データを、アコースティックモデルで音素(最低限の音の単位)に分ける。この段階で、その音が「こ」なのか「に」なのかを決める。続いて前後の音を繋いで発音モデルを用い、単語を作成する。最後に言語モデルを用いて、作成された単語がどんな語であるかを決定する。たとえば、「こ」と「に」が出てくる単語は、この文脈では「こんにちは」であろう、といったようにだ

実は、バックグラウンドでの処理自体はGoogle音声入力などと同じ技術が使われているのだという。
ただし、Google音声入力が短めのセンテンスを正確に変換することを意識して設計されているのに対し、Live Transcribeでは会話などの長文をできるだけ高速に処理するよう設計されている。
実際、Live Transcribeではネットワークの種類にもよるが、概ね200ミリ秒程度(=0.2秒)でレスポンスがあるという。やりとりするデータは30分程度の会話で150〜250メガバイト程度というから、想像するほど大きくはない。高速なLTE回線などが整備されていない発展途上国などでも、十分動作するというわけだ。
オフライン変換や録音、翻訳機能にも期待
非常に強力かつ高速な音声文字変換能力を誇るLive Transribeだが、聴覚障害者はもちろんのこと、筆者のような取材・インタビューを行う機会が多い人間にとっても、文字起こしの強い味方に見える。
しかし、残念ながら現時点では、Live Transcribeには変換結果をテキストファイルとして保存する機能や、音声を録音する機能がない。あくまでその場で逐次変換してくれるだけだ。
これについては同様に残念がっていたメディア関係者が多かったようで、セミナーでも多くの質問、というか希望が寄せられたのだが、サブラ氏によれば、録音しながらの変換だと、相手に心理的な負担をかけかねないので、あえて録音機能は付けなかったとのこと(テキストファイル化についても同様)。ただし将来的にはこうした機能も付けたいとのことだったので、筆者としては大いに期待しておきたい。
また、将来のバージョンにおいては、クラウドを使わず、オフラインの端末だけでディープニューラルネットワーク処理を行うことも視野に入れているという。
これはGoogle Pixelシリーズと、モバイルデバイス用のキーボードソフト「Gboard」の組み合わせで実現しているオフライン変換機能と同様に、超小型に圧縮された認識エンジンを使って実現するというわけだ。英語のみだがすでにPixelシリーズ向けにテストリリースしているといい、こちらも大いに期待できる。
このほか、大勢が同時に話している環境での正確な認識(俗にいう「カクテルパーティー問題」)や、ノイズの多い環境での認識率なども高めていきたいとのこと。将来のAIは聖徳太子のように、同時に10人の言葉を聞いて変換し分けることができるようになるのかもしれない。
加齢に伴う聴覚の衰えというのは徐々に進むこともあり、なかなか本人が気付きにくい。気付いた頃には日常に支障があるレベル、ということも多いという。今、障害がなくても、いつか自分の身にも降りかかる可能性は小さくはない。こうした問題に対して、スマートフォン+最新技術で解決する手段が開発・提供されているというのは、大いに心強いものがある。
将来はこうした機能がモバイルデバイスの標準となり、変換だけでなく翻訳や音声合成までも連携し、世界中の誰とも自在にコミュニケーションが取れるような世の中になることが期待できる、そんな夢のあるアプリとして注目したい。








