ということでSandraの結果を一通り紹介したところで、Skylake-SPについて分かったことは
- CPU Pipelineでは、MicroOps Cacheの容量がおそらく大幅に増やされた(最低でも倍増)
- Mesh構造によるものか、キャッシュの排他構造によるものかは判断つきにくいが、キャッシュの帯域そのものは若干増えている一方、アクセスのLatencyそのものも増えている。
- Mesh構造のNetworkにより、コア間の同期のLatencyは20ns程度増えている(50ns→70ns)。
- Meshに起因するものかどうかわからないが、1 threadあたりのメモリアクセス帯域はむしろ落ちている。
- システム全体としてのメモリアクセス帯域はむしろ増えている。
というあたりだろうか。まず(1)は純粋にIPC改善であろう。Zenコアの話は2015年ごろから出ていたので、Intelがこれに対して何もしないと考えるほうがおかしい。できる策は全部打つのがIntel流である。ただ、CPUパイプラインそのものを全部いじるのはリスクが高い。その中で、MicroOps Cacheの容量を増やすのは(パイプラインそのものを変更することに比べれば)比較的容易である。
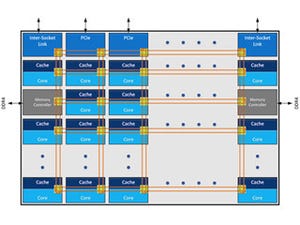
順序は異なるが、(3)はスケーラビリティの確保だろう。今回はLCCコアでの比較なので、当然Ring Busが1本のCore i7-6950Xの方がLatencyは少ない。ところがMCCあるいはHCCのダイの場合、こちらにあるように2本のRing BusをShared Unitで繋ぐという複雑な構造になるので、急激にLatencyが増える。今回のMesh構造の採用は、LCCでの性能低下を覚悟の上で、MCC/HCCでの性能改善を目指したものと考えられる。
そのMesh構造の採用で、より大規模なデータを効率よく扱えるようにする、というのがXeon Scalable Processorの目的であり、したがってMemory ControllerやMesh Controllerもこれに準じたものになる。つまり(4)の様にランダムアクセスなどでの性能は多少下がっても、規則的なメモリアクセスでのスループットを引き上げるという方向だ。
今回RMMTやSandraで試したSingle ThreadでのMemory Bandwidthのテストは、Xeon Scalableの方向から言えばランダムアクセスに近いものに位置するのだと考えると、異様に低いSingle Thread性能も理解できる。逆に規則的なアクセスで性能が上がりやすいという(5)の特徴も、こう考えれば理解しやすい。
逆説的だが、メモリコントローラをこの方向に振ったからこそ、L2を大容量化して局所的なデータアクセスが多いケースでの性能底上げを図ったと考えれば、L3を排他にする理由も理解できる。
非排他方式のままL2を大容量化する場合、L3をそれにも増して大容量化しないと効率が悪い。ところが、そうでなくても多数のコアを搭載する予定だから、ダイサイズは無駄に増やしたくない。排他方式は必然だったともいえる。その代償が(2)な訳だ。
ただこの結果として、アプリケーションの最適化は一からやり直しに近くなるだろう。MicroOps Cacheの容量が変わっただけでも大問題なのに加え、L2の大容量化とメモリコントローラの性格変更が加わったら、それはIntel MKLがまともに動かなくても不思議ではない。このあたりは、何れSkylake-SPに対応したあたらしいMKL(とLINPACK)が出てから評価しなおす必要があるだろう。