



検索システムでは検索する単語と一致する単語を含むドキュメントを見つけ出しますが、この単語をどのようなものにするかは検索システムの品質にも影響する重要な要素です。今回は、その単語を作る機能であるAnalyzerについて紹介します。
Fessは検索エンジンにElasticsearchを採用していますが、Elasticsearchは検索ライブラリとしてApache Luceneを利用しています。今回紹介するAnalyzerはApache Luceneが提供する機能です。
まず、Analyzerが作る単語がどのように使われるかを考えるため、転置インデックスについて説明します。
転置インデックスとは
転置インデックスは、検索対象の文書群から抽出した単語を利用して、その単語と文書の位置情報を格納した索引構造のことです。
たとえば、以下の左側のような2つの文書データがあり、検索対象としたいとします。
 |
|
転置インデックス |
検索対象数が少なければ、すべての文書を順に見ていけばすぐに見つけることができますが、量が増えれば増えるほど検索時間も増え、現実的ではありません。
検索システムでは効率よく見つめるために、右側のような索引(インデックス)を作っておきます。
「タワー」を検索する場合は、文書データ群を探すのではなく、インデックスの単語の中からタワーの行を見つけます。その行の文書IDリストから文書IDが2のものに「タワー」が含まれていることがわかります。
あとは、検索システムは見つけた文書を検索結果として応答するだけです。
Fessでは、Analyzerがインデックスで利用する単語を生成しています。
以下の図のようにクロール/インデクシング時に検索対象の文書群のテキストをAnalyzerで単語にしてインデックスに格納します。また、検索時にも検索語の文字列をAnalyzerで単語に分割して、その単語を元にインデックスから対象の文書群を見つけて検索結果として取得します。
 |
|
検索システムにおけるAnalyzerの役割 |
冒頭の検索品質に影響する重要な要素という意味に気づいたかもしれませんが、インデクシング時と検索時の単語が一致しないと文書を見つけることができませんし、細かく分割しすぎても単語数が増え(インデックスサイズが増え)、非効率になってしまいます。
そのため、検索システムを構築する上でAnalyzerの役割は大きいといえます。
Analyzerとは
Analyzerはテキストを解析する機能です。Analyzerは一般的なワードではありますが、本稿ではApache Luceneが提供するAnalyzerのこととして説明していきます。
簡単に説明すると、文書などのテキストを受け取り、単語に分割して返却する作業を提供しております。実際に試してみるのがわかりやすいので、ElasticsearchのAnalyze APIを利用して試してみましょう。
Fess 12.1のzip版を起動している状態であれば、以下のようなリクエストで「this is a test」をStandard Analyzerで解析できます。
 |
レスポンスは以下のようになります。
{
"tokens" : [
{
"token" : "this",
"start_offset" : 0,
"end_offset" : 4,
"type" : "",
"position" : 0
},
{
"token" : "is",
"start_offset" : 5,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "a",
"start_offset" : 8,
"end_offset" : 9,
"type" : "",
"position" : 2
},
{
"token" : "test",
"start_offset" : 10,
"end_offset" : 14,
"type" : "",
"position" : 3
}
]
}
分割された単語情報はトークンと呼ばれる情報で返却され、与えたテキストはトークン配列として取得することができます。
tokenが単語の文字列、start_offsetとend_offsetは元のテキストの中で何番目の文字の範囲にあったか、typeは単語の種類、positionは何番目の単語だったかになります。
これらの情報は、start_offsetとend_offsetから検索結果で表示するハイライトの位置情報として利用できたり、positionから単語の順番を考慮した検索ができたりと、トークンには検索に有用な情報が含まれています。
上記以外にも、日本語であれば読み情報など、さまざまなものが取得できる汎用的な仕組みになっています。
Analyzerについて、もう少し細かく見ていくと、AnalyzerはCharFilter、Tokenizer、TokenFilterと呼ばれる3つの機能から構成されています。
- CharFilter: 渡された文字列を文字単位に処理する
- Tokenizer: 渡された文字列をトークン配列にする
- TokenFilter: 渡されたトークン配列をトークン単位に処理する
Analyzerは解析対象の文字列を受け取ると、まず、文字列をCharFilter群に適用し、次にTokenizerでトークン配列に変換して、最後にTokenFilter群に適用することで、最終的なトークン配列を取得します。 今回、理解をしやすくするためにトークン配列と記述しましたが、Analyzerの内部処理は非常に効率化されているので、実際には配列を無駄に作らずストリーム的に処理が行われています。
以下の図のように「東京スカイツリーの①番出口」という文字列をAnalyzerに適用して変換していく例を考えてみます。
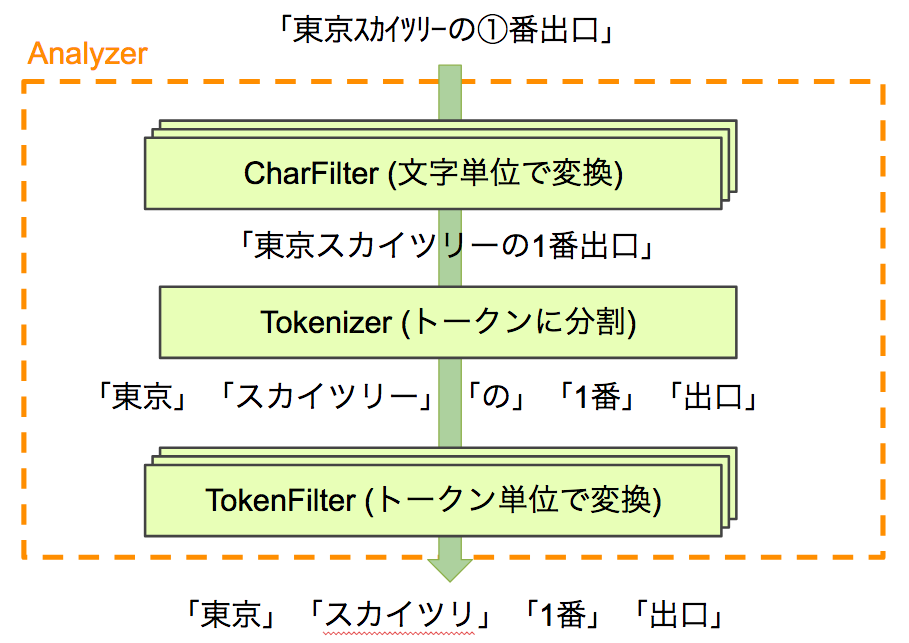 |
|
Analyzerの構成 |
検索にできるだけヒットさせるためには、まず始めにCharFilterに半角カタカナや丸数字を変換するものを用意して適用します。
文字単位の変換をすることで、「東京スカイツリーの1番出口」にすることができます。
これをKuromojiのような形態素解析を行うTokenizerに適用することで、「東京」「スカイツリー」「の」「1番」「出口」のトークンに分割することができます。
実際に検索する場合を考えると、長音符の有り無しで単語が一致しなかったり、助詞などの検索になくてもあまり影響がないものは取り除いてしまいます。 ですので、TokenFilter群にそれらの処理を行うものを設定して適用することで、最終的に「東京」「スカイツリ」「1番」「出口」というトークン配列を取得します。
ElasticsearchにはstandardなどビルドインされたAnalyzerもいろいろあります。また、Kuromojiなどをプラグインで追加したり、CharFilter、Tokenizer、TokenFilterを組み合わせることで独自のAnalyzerも定義することもできます。
Fessでは、多言語をサポートしていることもあり、さまざまな言語用のAnalyzerを定義して利用しています。
* * *
今回は検索システムの肝ともいえるAnalyzerについて紹介しました。
どのようなAnalyzerが最適なのか?などの要件は検索対象によって変わってくるので、より良い検索品質を目指していくのであればAnalyzerのチューニングは必要不可欠なものになります。
Analyzerの仕組みがわかれば、独自のAnalyzerを定義して利用することもできると思います。
次回は日本語文書でのAnalyzerについて詳しくみていく予定です。
著者紹介
 |
菅谷 信介 (Shinsuke Sugaya)
Apache PredictionIOにて、コミッター兼PMCとして活動。また、自身でもCodeLibs Projectを立ち上げ、オープンソースの全文検索サーバFessなどの開発に従事。










