今回はRustを使って、簡単なHTTPサーバを実装してみましょう。HTTPは単純ですが生活インフラとしても必須となっているWebの根幹となる技術です。Rustに対する理解を深めると同時にWebの根幹となるHTTPについても学びましょう。
-

RustでHTTPを実装してみよう

HTTPプロトコルとは?
「HTTP(Hypertext Transfer Protocol)」とは、WebサーバーとWebブラウザの間でデータをやりとりするための通信規則(プロトコル)です。 1990年末にイギリスの物理学者ティム・バーナーズ=リー氏と、ロバート・カイリュー氏によって設計されました。
HTTPプロトコルは、RFCとして公に発表されています。RFCとは、IETFが発行しているインターネットに関連する技術仕様などを共有するために公開される文書であり誰でも読むことができます。1996年にHTTP/1.0に関する「RFC 1945」が発表され、翌年にはHTTP/1.1が「RFC2068」として発表されました。その後も続々と改良されRFCが発表されました。最近では、より効率的に通信を行う、HTTP/3が「RFC 9114」が発表され話題となりました。HTTPは今でも改良され続けているのです。
それでは、実際にHTTPプロトコルについて確認してみましょう。HTTPでは、WebサーバとWebブラウザが通信を行います。つまり、末端のクライアント(Webブラウザ)が、サーバに接続してデータの送受信を行います。皆さんがご存じのように、Webブラウザを利用してWebサーバに接続して、HTMLや画像などのデータを取得します。
なお、データの送受信に関してですが、HTTPでは次のような流れで通信が行われます。
(1) ブラウザはサーバへ接続する
(2) ブラウザからサーバへ「リクエスト(Request)」を送信する
(3) サーバからブラウザへの「レスポンス(Response)」を返す
(4) 接続を切断する
サーバに接続したら、リクエスト(要求)に対するレスポンス(応答)があり、一回の通信が切れます。このように、HTTPは基本的にとてもシンプルな仕組みで成り立っています。
-

HTTP通信の仕組み

もちろん、昨今のHTTP通信では暗号化やセッション管理など、より複雑な仕組みが行われていますが、本稿でHTTPの全てを実装するのは無理なので、基本的な部分だけを実装してみましょう。
ここでは、Webブラウザでアクセスして、指定ディレクトリ以下にあるHTMLファイルを返信するという基本的な処理をRustで実装してみましょう。
HTTPサーバのプロジェクトの作成
それでは、Rustでプロジェクトを作成しましょう。ターミナル(WindowsならPowerShell、macOSならターミナル.app)を起動して、下記のコマンドを実行しましょう。
# フォルダを作成して移動
mkdir my_http_server
cd my_http_server
# プロジェクトを初期化
cargo init
そして、src/main.rs を編集します。
最も簡単なHTTPサーバのプログラム
以下は最も簡単なHTTPサーバのプログラムです。src/main.rsを書き換えましょう。
use std::io::prelude::*;
use std::net::TcpListener;
// サーバアドレスを指定 --- (*1)
const SERVER_ADDRESS: &str = "127.0.0.1:8888";
fn main() {
// HTTPサーバを起動 --- (*2)
println!("[HTTPサーバを起動] http://{}", SERVER_ADDRESS);
let listener = TcpListener::bind(SERVER_ADDRESS).unwrap();
// クライアントからの接続を待ち受ける --- (*3)
for stream in listener.incoming() {
println!("クライアントが接続しました。");
// クライアントとの通信を行う --- (*4)
let stream = stream.unwrap();
handle_client(stream);
}
}
fn handle_client(mut stream: std::net::TcpStream) {
// クライアントのリクエストを読み込む --- (*5)
let mut request_buf = [0; 4096];
let size = stream.read(&mut request_buf).unwrap();
let request = String::from_utf8_lossy(&request_buf);
println!("Request: {}B\n{}\n", size, request);
// クライアントへレスポンスを返す --- (*6)
let response = "<h1>Hello, World!</h1>";
stream.write(b"HTTP/1.1 200 OK\r\n\r\n").unwrap(); // ヘッダ
stream.write(response.as_bytes()).unwrap(); // 本体
stream.flush().unwrap(); // 出力
}
ターミナルからプログラムを実行してみましょう。
cargo run
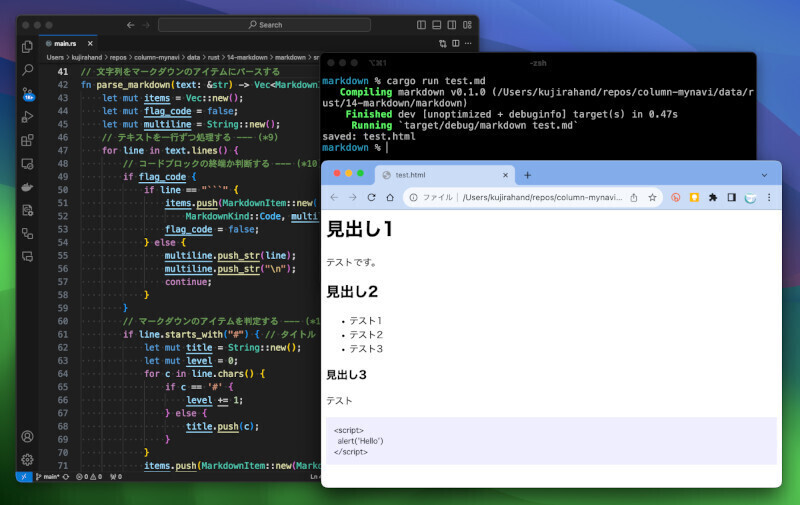
すると、HTTPサーバが起動します。そして、ブラウザの待ち受け状態になります。そこで、Webブラウザを起動して「http://127.0.0.1:8888」にアクセスしてみましょう。すると、次のように表示されます。うまく動かなかった場合は、以下の解説(*1)を参考にして修正してみてください。プログラムを終了するには、[Ctrl]キーを押しながら[C]キーを押すかターミナルを閉じます。
-

Webサーバを起動してブラウザでアクセスしたところ

プログラムを確認してみましょう。(*1)ではローカル環境でWebサーバのアドレスを指定します。ここでは、自身(localhost)を表すアドレス「127.0.0.1」のポート8888番でサーバーを起動します。
なお、既にポート8888で起動しているサービスがあると、サーバは起動に失敗します。その場合は、サーバアドレスを「127.0.0.1:8889」に変更するなど、適当な番号に変更して試してみてください。
(*2)では実際にサーバを起動します。ここでは、TCPソケットを扱うRust標準ライブラリ「TcpListener」のbind関数を利用してサーバを起動します。そして、(*3)ではクライアントからの接続を待ち受けます。クライアントが接続すると、(*4)のhandle_clientが実行されます。
(*5)以降では関数handle_clientの処理を記述します。これはクライアントが接続してきた際に行う処理です。(*5)ではクライアントのリクエストを読み、(*6)ではクライアントにレスポンスを返します。
このプログラムでは、クライアントのリクエストを何も解析せず、問答無用に(*6)で「<h1>Hello, World!</h1>」というHTMLを返信します。
リクエストを解析してHTMLファイルを返信しよう
それでは、少しだけサーバらしい処理をするように改良しましょう。先ほど、リクエストに対して、常に同じ応答を返すようになっていましたので、ブラウザからのリクエストをしっかり確認して、どのファイルを返すのか確認するようにしてみましょう。
先ほど作ったプログラムの実行ログを確認してみましょう。ブラウザのリクエストは次のようなものでした。
GET / HTTP/1.1
Host: 127.0.0.1:8888
Connection: keep-alive
Cache-Control: max-age=0
〜省略〜
続いて、サーバを起動した状態で、Webブラウザのアドレスバーで「http://127.0.0.1:8888/hoge.html」にアクセスしてみましょう。すると、下記のように表示されることでしょう。
GET /hoge.html HTTP/1.1
Host: 127.0.0.1:8888
Connection: keep-alive
〜省略〜
変更があった部分はリクエストの一行目です。一行目を比べてみると分かりますが「GET (取得したいファイル名) HTTP/(バージョン)」となっていることが分かるでしょう。
そこで、先ほど作成したサーバのプログラムの関数handle_clientを次のように書き換えてみましょう。なお、プログラム全体をこちらにアップしています。
fn handle_client(mut stream: std::net::TcpStream) {
// クライアントのリクエストを読み込む --- (*1)
let mut request_buf = [0; 4096];
let size = stream.read(&mut request_buf).unwrap();
let request = String::from_utf8_lossy(&request_buf);
println!("Request: {}B\n{}\n", size, request);
// リクエストを解析する --- (*2)
let request_lines: Vec<&str> = request.lines().collect();
// 一行目のリクエストを取り出してスペースで分割 --- (*3)
let request_line = request_lines[0];
let mut parts = request_line.split_whitespace();
// 結果を取り出す --- (*4)
let method = parts.next().unwrap();
let path = parts.next().unwrap();
let _version = parts.next().unwrap();
println!("Method: {}, Path: {}", method, path);
// ファイルを読み込む --- (*5)
let path = if path == "/" { "/index.html" } else { path };
let fullpath = format!("./html{}", path);
let fullpath = fullpath.replace("..", ""); // セキュリティ対策
println!("Fullpath: {}", fullpath);
// ファイルを読み込む --- (*6)
let response = std::fs::read_to_string(fullpath)
.unwrap_or("404 not found".to_string());
// レスポンスを返す --- (*7)
stream.write(b"HTTP/1.1 200 OK\r\n").unwrap();
stream.write(b"Content-Type: text/html; charset=utf-8\r\n").unwrap();
// データ本体を返す --- (*8)
stream.write(b"\r\n").unwrap();
stream.write(response.as_bytes()).unwrap(); // 本体
stream.flush().unwrap(); // 出力
}
最初にプログラムを確認してみましょう。(*1)ではクライアントのリクエストを読み込みます。ここは先ほどと同じです。
(*2)ではブラウザから送信されたリクエストを解析します。特に、ここでは1行目に書かれている「GET (URL)」の部分を抽出します。そのために、改行で分割した後、(*3)で先頭行を取り出し、さらにスペースで区切ります。そして、(*4)でリクエストのパース結果を取り出して表示します。
それで、(*5)では、ローカルにあるどのファイルを読むべきかパスを解決します。今回は「html」ディレクトリ以下にファイルを配置する仕組みにしました。ここで気をつけたいのが、ディレクトリの相対指定の「..」です。特定のディレクトリより上の階層にファイルを読めてしまうと機密ファイルが漏洩してしまう可能性があるので、ここでは上の階層へのアクセスを許さないようにしています。もちろん、こんなテストプログラムで本番運用しないと思いますが、Web関連のプログラムを作る時には、セキュリティ意識をしっかり持つことが大切です。
(*6)では実際にローカルファイルを読み込みます。ファイルが存在しなければ「404 not found」という文字列を返すようにしました。
(*7)ではレスポンスを返します。ここでは「HTTP/1.1 200 OK」というレスポンスコードと、その後でHTMLを表すMIMEタイプと文字コードを返信します。そして、(*8)でファイルの内容を返信します。
それでは、プログラムを実行してみましょう。ここでは、htmlというフォルダを作成して、その下に「index.html」と「hoge.html」の2つのHTMLファイルを用意しましょう。改めてプロジェクトのディレクトリ構成を確認してみましょう。
.
├── Cargo.toml
├── html
│ ├── hoge.html
│ └── index.html
└── src
└── main.rs


HTMLファイルの内容は次のような簡単なものです。なお、ファイル名が分かるように修正すると動作が分かりやすいでしょう。
<html><body>
<h1>「hoge.html」から「こんにちは」</h1>
</body></html>
プログラムを実行するには、次のコマンドを実行します。そして、ブラウザで「http://127.0.0.1:8888/hoge.html」にアクセスしてみましょう。
cargo run
すると、次のように表示されます。
-

URLに応じたHTMLファイルを読み込むように改良したところ

うまく行ったら「http://127.0.0.1:8888/index.html」にアクセスして表示される内容が変わるかも確認してみましょう。
まとめ
以上、今回は、HTTPの仕組みを確認しながら、Rustで簡単なHTTPサーバを実装してみました。RustのTCPソケットライブラリが使いやすいため、思ったよりも難しいという印象はないのではないでしょうか。
プログラムを見ると、エラー処理を無視する「.unwrap」が頻出しています。もちろん、実用的なサーバを作る場合には、しっかりとエラー処理を行う必要があることが分かりますが、基本的な仕組みは理解できたことでしょう。
なお、今回のプログラムでは、サーバの返すレスポンスに含めるHTTPのステータスメッセージを、全て「200 OK」と返しています。本来、存在しないファイルがリクエストされたなら、「HTTP/1.1 404 Not found」を返すようにする必要があります。また、HTMLを返すことしか想定していないので、MIMEタイプも「text/html」で固定しています。次のステップとして、こうした処理を実装してみると良いでしょう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。直近では、「実践力をアップする Pythonによるアルゴリズムの教科書(マイナビ出版)」「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方 TensorFlow2対応(ソシム)」「マンガでざっくり学ぶPython(マイナビ出版)」など。