日立製作所(日立)と東京大学(東大)の両者は6月19日、ビッグデータ分析の高速化に向け、相互に複雑なつながりを持つデータ(グラフ構造データ)の検索速度を大幅に高める「動的プルーニング技術」を開発したと共同で発表した。
-

開発技術の適用イメージのトレーサビリティ問い合わせ例(徹底的な製造検査)(出所:日立プレスリリースPDF)

同成果は、日立 研究開発グループと、東大 生産技術研究所の合田和生教授らの共同研究チームによるもの。詳細は、6月22日からドイツ・ベルリンで開催されるデータベース分野の国際会議「2025 ACM SIGMOD/PODS International Conference on Management of Data」で発表される予定だ。
トレーサビリティやデータ利活用を支援する新技術


AIやビッグデータの活用が急速に進む中、データ処理技術の重要性が高まっている。中でも、AIの性能向上や社会課題解決には、データ検索の効率化が強く求められている。
膨大なデータを格納するデータベースでは、データ同士の複雑なつながりを効率的に表現する必要がある。それを可能とするのがグラフ構造データだ。これは、データの対象物を表すノード(頂点)と、ノード間の関係性やつながりを表すエッジ(辺)でデータを表現する構造を持つ。グラフ構造データは、交通経路検索やeコマースの商品リコメンデーション、製品の品質管理、医療データ分析、不正アクセス分析など、多様な分析業務で利用されている。
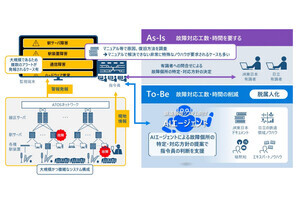
しかし、グラフ構造データはデータ量や階層が増加するのに伴って、検索速度が低下していくことが課題となっていた。検索速度の低下は、迅速なデータ分析や意思決定が困難になることを招く。この課題解決のため、日立と東大の共同研究チームは、新たなデータプラットフォーム技術の確立に向けた研究開発に取り組んだという。
今回の研究では、データベース内のグラフ構造データ検索を大幅に高速化する“動的プルーニング技術”が、成果の1つとして発表された。プルーニングとは、問い合わせの実行時、不要なデータの読み取りをスキップすることで問い合わせを高速化する手法である。
従来、データベース内でデータ分析を行う際のグラフ構造データの検索は、「再帰問い合わせ処理」と呼ばれる手続きで行われる。この処理方法は、データベースやプログラムにおいて、問題を小さな部分に分割し、それを繰り返し解決することで全体の問題を解決するものだ。グラフ構造データをたどる手法であり、特に親子関係や階層構造を持つデータの取得に用いられる。しかし、不要なデータを繰り返し読み取る必要があり、それが検索速度が低下させていた。
それに対し動的プルーニング技術は、再帰問い合わせ処理の実行中に得られる「中間結果」(再帰問い合わせの前段で得られた検索結果データ)に基づき、次に読み取るデータの範囲をリアルタイムかつ正確に特定する。これにより、各処理に必要なデータをより正確に特定し、不要なデータ読み取りを削減。データ量が増加した場合や、データ階層が深くなった場合でも読み取り量を抑え、検索速度の大幅な向上が可能になった。
製造業の製品出荷判定において、グラフ構造データの分析業務をモデル化したデータベースを用いて、動的プルーニング技術の検証が行われた。その結果、再帰問い合わせ処理におけるデータ読み取り量が大幅に削減され、日立製の従来技術との比較でデータ検索速度が最大135倍も向上したことが確認された。この技術は、製品設計から製造、流通、保守までの工程や部品の追跡といったグラフ構造データ分析業務を迅速化し、トレーサビリティの品質向上に貢献するとした。
-

再帰問い合わせ処理におけるデータの読み取り範囲とデータ検索時間の比較(出所:日立プレスリリースPDF)

動的プルーニング技術は、標準SQLに対応した日立製リレーショナルデータベース「Hitachi Advanced Data Binder」(HADB)にすでに組み込まれ、提供が開始されている。またHADBは、生産工程における業務とデータ間のつながりをデジタル空間に再現する「IoTコンパス」と共に、IoTやデータの利活用を支援するサービス群「Hitachi Intelligent Platform」で利用可能だとする。
日立と東大は今後、動的プルーニング技術のさらなる高度化やAI連携を進め、製造業のほか、社会保障や金融分野などへの適用を目指すとした。社会課題の解決に向けた技術革新を推進していく方針としている。