rinnaは10月31日、米Metaが公開した「LlaMa2」に日本語の学習データで継続事前学習を行った「Youri 7B」シリーズを開発し、LLAMA 2 Community Licenseで公開したことを発表した。同社はこれにより、日本のAI研究開発の発展を支援する。ちなみに、モデル名の由来は妖怪の「妖狸(ようり)」とのことだ。
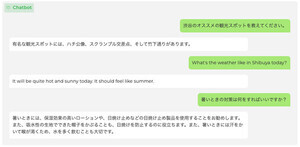
汎用言語モデルである「Youri 7B」の他に、日本語の一問一答に応える能力が高い「Youri 7B Instruction」と、複数ターンの対話データを用いて追加学習しているため対話性能が高い「Youri 7B Chat」などのモデルも公開している。
Youri 7Bは、70億パラメータを2兆トークンで学習したLlaMa2 7Bに対して、日本語と英語の学習データを用いて400億トークンで継続事前学習しているという。LlaMa2のパフォーマンスを日本語にも引き継いでおり、日本語のタスクでも高い性能を示す。日本語言語モデルの性能を評価するためのベンチマークの一つである「Stability-AI/lm-evaluation-harness」の8タスク平均スコアは58.87。
-

ベンチマークスコア

Youri 7Bのファイルサイズは12ギガバイトを超えており、メモリが少ないGPUでは動かすための工夫を要する。そこで同社はGPTQという手法を用いて4bit量子化を行うことで、ファイルサイズを4ギガバイト以下に抑えたモデル「Youri 7B GPTQ」「Youri 7B Instruction GPTQ」「Youri 7B Chat GPTQ」も公開している。なお、4bit量子化によるベンチマークスコアの低下は1〜2ポイント程度とのことだ。