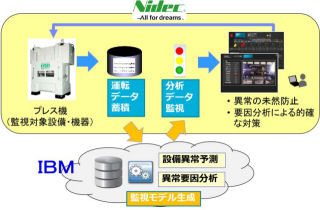
|
日本IBM 理事 アナリティクス事業部長 三浦美穂氏 |
日本IBMは7月8日、都内で記者説明会を開催し、オープンソースのビッグデータ処理基盤「Apache Spark」に対する同社の取り組みについて説明した。
理事 アナリティクス事業部長の三浦美穂氏は、同社がSparkを推進する理由の1つとして、 インサイト・エコノミーを促進することを挙げた。「インサイト・エコノミーとは、データ分析・活用を実経済に役立てることで、その試みはすでに始まっている。インサイト・エコノミーにおいては、大量のデータに対する多様な分析を遅延なくこなすスピード、それを実現するアルゴリズムも迅速に開発できることが重要になってくる」(三浦氏)
同氏は、インサイト・エコノミーでは現在、オープンソースの分散処理基盤「Hadoop」が活用されているが、Hadoopにはメリットがありながらも限界が来ていると指摘した。具体的には、Hadoopには「MapReduceによるアプリケーションの開発は簡単ではない」「バッチ処理に適しているが、リアルタイムの分析には適していない」「大量の分析処理においては、ディスクI/Oがボトルネックとなる」といった課題があるという。
こうしたHadoopの課題を解決するのがSparkとなる。同氏は、Sparkの特徴として、「分散インメモリのキャッシング技術により高いパフォーマンスを実現」「機械学習・グラフ処理・ストリーム処理など、ビッグデータ活用に必要な処理をライブラリとして提供するので、効率のよいアプリ開発が可能」といった点を挙げた。なお、SparkはHadoopを置き換える技術ではなく、Hadoopを補完する技術になるという。

|
「Apache Spark」の概要 |
同社は、Spark普及に向けて、以下のような取り組みを推進していく。
- 同社のアナリティクスとコマース・プラットフォームの中核にSparkを組み込む
- 機械学習技術「IBM SystemML」をSparkコミュニティに提供
- IBM Bluemix上のクラウドサービスとしてSparkを提供
- グローバルで3500人以上の研究者と開発者をSpark関連のプロジェクトに従事
- データ・サイエンスと開発者のコミュニティを対象とした「Sparkテクノロジー・センター」をサンフランシスコに開設
- グローバルで100万人以上のデータ・サイエンティストとデータ・エンジニアに対しSparkの教育を推進

|
Sparkが組み込まれる予定のIBM製品 |
同日、HadoopとSparkをエンタープライズ領域で容易に利用することを可能にする製品「IBM BigInsights for Apache Hadoop V4.1」も発表された。参考価格は21万6200円(税別)から。
「IBM BigInsights for Apache Hadoop」とは、同社が提供するHadoopのディストリビューションで、Hadoopにおけるデータ加工や管理の生産性を高める独自の機能を提供している。
最新版では、具体的には、データ・サイエンティストやデータベース技術者がSQLの高度な専門知識を生かしながら、Hadoopによるデータ分析を実現する「Big SQL」、一般的な表計算ソフトウェアの感覚でMapReduce処理を実装できる「BigSheets」、文章データの構造を分析するテキスト分析機能といった従来の機能に加え、Hadoop環境でオープンソースの統計解析用言語Rを実行する「Big R」、Big R上での機械学習機能の提供など、データ・サイエンティストの生産性向上を支援する機能を強化している。
同製品は機能が異なる3つのパッケージから構成される。
エントリーモデルとなる「IBM BigInsights Analyst Module」は、Big SQL、BigSheets機能を提供する。「IBM BigInsights Data Scientist Module」は、データ・サイエンティストの業務に必要な分析機能「Big R」、機械学習機能、Big SQL、BigSheets、テキスト分析を提供する。「IBM BigInsights Enterprise Management Module」は、Hadoop環境の高度な運用ツールを提供する。
「IBM BigInsights Quick Start Edition」は、「IBM BigInsights Data Scientist Module」の一部管理機能を除き、ほぼ同等の機能を無料で提供する(有料サポートの提供なし、利用環境に制限あり)。
さらに、100%オープンソースのApache Hadoopのディストリビューション「「IBM Open Platform with Apache Hadoop」も提供され、SparkをはじめとするOpen Data Platform Initiativeの最新の成果を迅速に利用できる。

|
「IBM BigInsights for Apache Hadoop」の構成 |