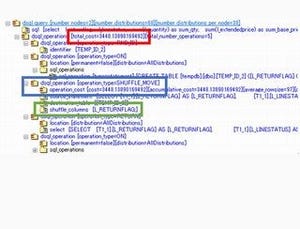
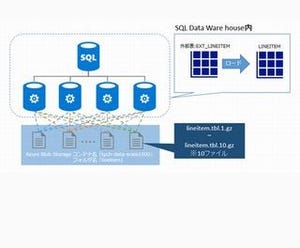
今回は複数のテーブルを結合するSQLのチューニングを行います。前回と同様にTPC-Hの環境を使います。今回の対象のSQLは以下の通りです。
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = ovorderkey
and o_orderdate < '1995-03-15'
and l_shipdate > '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate;
上記のように、今回は「customer」「orders」「lineitem」の3つのテーブルを結合します。各テーブルのリレーションはTPC-Hのサイトを参考にしてください。
 |
The TPC-H Schema 出展:TPC BENCHMARKTM H (Decision Support) Standard Specification Revision 2.17.2 |
また現時点では、すべてのテーブルはクラスター化カラムストアインデックスで構成されており、ROUND ROBIN分散でディストリビューションされています。
統計情報の取得
統計情報とは、SQL Data Warehouseが実行計画を生成する際のもととなるデータです。統計情報をもとに、SQL Data Warehouseは最適な実行計画を作ります。しかし、SQL Data Warehouseでは統計情報を自動で取得するような機能はありません。今回のデータもSQL Data Warehouseにデータを入れただけで、統計情報の取得は行っていません。まずは、統計情報を取得してみて、実行速度の変化を確認してみましょう。
統計情報の取得は、以下のようにいくつかの種類があります。
- 単一の列に対する統計情報の取得
- 複数列に対する統計情報の取得
- データの中の一部の行のみに対する統計情報の取得
また、MicrosoftのSQL Data Warehouseに関する公式ドキュメントでは、データベース内のすべての列の統計が取得できるストアドプロシージャも用意されていますが、一般的に統計情報の取得、更新の基準は以下の通りです。
- JOIN、GROUP BY、ORDER BY、DISTINCTの各句に使用されている列で取得
- 「日付」などで利用されている列は高頻度で更新が必要(特に新しい日付のデータが追加された時はできるだけ取得するようにする)
- 「性別」などデータの分布があまり変わらない列は更新頻度を下げる。
今回の例では、WHERE句の中で指定されている列に対して、以下のように統計情報を取得します。
CREATE STATISTICS customer_c_custkey ON customer(c_custkey);
CREATE STATISTICS customer_c_mktsegment ON customer(c_mktsegment);
CREATE STATISTICS order_o_custkey ON order(o_custkey);
CREATE STATISTICS order_o_orderkey ON order(o_orderkey);
CREATE STATISTICS order_o_orderdate ON order(o_orderdate);
CREATE STATISTICS lineitem_l_orderkey ON lineitem(l_orderkey);
CREATE STATISTICS lineitem_l_shipdate ON lineitem(l_shipdate);
統計情報の取得前後での実行結果の差は以下の通りです。
 |
オブジェクトの定義やSQLは何も変更をしておらず、統計情報を取得しただけですが、処理が約30%も高速化されていることがわかります。上記のように、統計情報を取得すること、また統計情報をメンテナンス(更新)することがいかに重要かわかっていただけたかと思います。
HASH分散の利用
次にHASH分散の利用を検討してみましょう。
SQL Data Warehouseでは、60のディストリビューションにデータが分散格納されており、コンピュートノードに均等に各ディストリビューションが割り当てられています。
SQLの実行をする際、GROUP BYによるデータの集計や、テーブル同士の結合を行う際に各コンピュートノードで完結して処理できることが非常に重要になります。なぜなら、各コンピュートノードで完結できない場合は、必要なデータを内部的に転送する処理が発生するからです(これは第5回で説明したDMSという機能です)。
この処理はSQL Data Warehouseの処理の中で非常に負荷が高いので、これを防ぐこと、すなわち可能な限り内部のデータ移動をなくし、各コンピュートノードで処理を完結させることがSQL Data Warehouseのチューニングの重要な要素となります。
テーブルの結合を行うようなSQLを実行する場合、ノード間データ移動(DMS)を抑える方法は、ずばりテーブルを「HASH分散」することです。 今回のSQLのWHARE句を見てみましょう。
where
c_mktsegment = 'BUILDING' ⇒絞り込み条件
and c_custkey = o_custkey ⇒結合条件
and l_orderkey = o_orderkey ⇒結合条件
and o_orderdate < '1995-03-15' ⇒絞り込み条件
and l_shipdate > '1995-03-15' ⇒絞り込み条件
絞り込み条件はテーブルから必要なデータを絞り込む(フィルターをかける)条件です。結合条件は1つ以上のテーブル同士を結合するための条件となります。この結合条件で指定されている項目にHASH分散のHASH KEYを指定することで、テーブル結合時のノード間データ移動の発生を抑制できます。ノード間データ移動の発生を抑制できるということは、負荷が削減でき、結果として高速な処理につながります。
以下のようなSQLで、既存のROUND ROBIN分散のテーブルをHASH分散に変更しました。
CREATE TABLE orders_HASH
WITH
(
DISTRIBUTION = HASH(o_orderkey),
CLUSTERED COLUMNSTORE INDEX
)
AS SELECT * FROM orders;
RENAME OBJECT orders to orders_ROUND_ROBIN;
RENAME OBJECT orders_HASH to orders;
CREATE TABLE lineitem_HASH
WITH
(
DISTRIBUTION = HASH(l_orderkey),
CLUSTERED COLUMNSTORE INDEX
)
AS SELECT * FROM lineitem;
RENAME OBJECT lineitem to lineitemROUNDROBIN;
RENAME OBJECT lineitem_hash to lineitem;
なお、テーブルをHASH分散のクラスター化カラムストアインデックスで再作成した後は、統計情報の取得は忘れないでください。
HASH分散を行う際のHASH KEYは複数の列を指定することはできません。このため、orderテーブルのo_custkey列(customerテーブルとの結合条件で使用)とo_orderkey列(lineitemテーブルとの結合条件で使用)のどちらをHASH KEYに指定するか悩ましいところですが、orderテーブルとlineitemテーブルとの結合のほうが、データ件数が多く、データ容量も大きいので、DMSが発生した際の負荷が大きくなることが予想されます。このことから、今回はordersテーブルの_orderkey列、linitemテーブルのl_orderkey列をHASH KEYに指定しています。
2テーブルをHASH分散させた結果は、すべてROUND ROBIN分散の場合と比較して性能はおよそ65%改善しました。
 |
以上が、複数のテーブルを結合するSQLのチューニングの例となります。SQL Data Warehouseでの統計情報の取得は忘れがちですが、きっちり取得・更新するようにしましょう。また、HASH分散を上手に使ってDMSの発生を抑えることが、SQL Data Warehouseのチューニングではとても重要です。逆にいうと、このポイントを押さえていれば、SQL Data Warehouseの性能問題の多くを解決できるのです。
山口 正寛
1984年生まれ。大阪府出身、東京都在住。データベースエンジニア。SQL Server、Oracle、MySQL、PostgreSQLなどのデータベースで、小規模から大規模な案件まで数多く経験。現在ではクラウドの流れに逆らうことなく、「データベース×クラウド」をキーワードに案件対応、セミナー活動、執筆活動など幅広く活動中。株式会社システムサポート所属。