

Hit&BlowとHangmanを合わせたようなWordleというゲームがはやっているらしい。Hit&Blowのようなゲームは、いまでもプログラミング学習の課題として使われる。筆者もBASICが動くマシンを手に入れたとき作ってみたことがある。三山崩しのように必勝アルゴリズムがあるゲームは、ゲームを作る過程で自分も学んでしまうため、ゲームなのに、ちっとも楽しくない。だが、それに気がつくのはプログラムを作ったあとだ。背が伸びないとアトムをサーカスに売り払う天馬博士に同情したくなる。
筆者はへそ曲がりなので流行り物には手を出さない主義だが、Hit&Blowなどのプログラムを作った関係で、Wordleの解法にはちょっと惹かれるところがある。答えを探すのに最適な単語を選べば試行回数を減らせるはずだ。
UNIXにはwordsという英単語のリストが含まれている。これは、スペルチェックなどを想定したもの。そもそもUNIXの開発時には、ワードプロセッシングのシステムを開発するといって予算を取ったという話がある。筆者は、その存在と利用方法を雑誌サイエンスに連載されていたコラム記事で知った。1980年台のことで今となっては記憶があいまいだが、メタマジックゲームかコンピュータリクリエーションだったと思う。wordsを使えば英単語全体を対象にするような処理ができる。
Linuxでは、wordsファイルはSCOWL(注01)のパッケージとして入手可能だ。Ubuntuなどで使われるdpkg系の「wamerican」パッケージには収録単語数の違いで5つのパッケージがある。筆者が試してみたところ、wamerican-smallには含まれない単語がWordleの正解になったことがあり、それ以上の収録数のパッケージでは、Wordleで辞書にないとして入力ができないものがあった。ということで境界にあたるwamericanパッケージが適当と考えられる。このパッケージをインストールすると/usr/share/dict/wordsファイルが作られる。
※注01: Spell Checker Oriented Word Lists
http://wordlist.aspell.net/
Wordleの答えは大文字で5文字なので、大文字で5文字の英単語だけのリストを予め作っておく。grepとtrを使いsortで並べ替え、重複行を抜く(先頭が大文字になった固有名詞が含まれるため)。
egrep -i '^\w{5}$' /usr/share/dict/words | tr a-z A-Z | sort -u >word5Wordleでは6回の試行で5文字の単語を探す。1回目、2回目の試行を、どの文字が含まれているのかを探すことに専念して、出現頻度の高い文字を含む単語を探す。文字の出現頻度は、あちこちにあるが注意すべき点がある。相手はWordleの中の辞書(単語リスト)であり、辞書なら見出し語は原則1つだけ、このため一般的な英文から計算された文字の出現頻度とは異なるパターンになる。
ここでは、Concise Oxford Dictionary(11th edition revised, 2004)から求めた文字の出現頻度を使う(注02)。筆者がまとめ直した表を(表01)に示す。出現頻度を高い順に並べると「EARIOTNSLCUDPMHGBFYWKVXZJQ」となる。
※注02: Which letters in the alphabet are used most often?
https://www.lexico.com/explore/which-letters-are-used-most
| ■表01 | ||
| 文字 | 出現頻度 | 累積頻度 |
| E | 11.16% | 11.16% |
|---|---|---|
| A | 8.50% | 19.66% |
| R | 7.58% | 27.24% |
| I | 7.54% | 34.78% |
| O | 7.16% | 41.95% |
| T | 6.95% | 48.90% |
| N | 6.65% | 55.55% |
| S | 5.74% | 61.29% |
| L | 5.49% | 66.78% |
| C | 4.54% | 71.32% |
| U | 3.63% | 74.95% |
| D | 3.38% | 78.33% |
| P | 3.17% | 81.50% |
| M | 3.01% | 84.51% |
| H | 3.00% | 87.51% |
| G | 2.47% | 89.98% |
| B | 2.07% | 92.06% |
| F | 1.81% | 93.87% |
| Y | 1.78% | 95.65% |
| W | 1.29% | 96.94% |
| K | 1.10% | 98.04% |
| V | 1.01% | 99.05% |
| X | 0.29% | 99.34% |
| Z | 0.27% | 99.61% |
| J | 0.20% | 99.80% |
| Q | 0.20% | 100.00% |
累積出現頻度50%以上の「EARIOTN」から5文字を含む単語は17個ある(写真01)。以下のコマンドで、先頭のgrepは探索用に文字が重複しない単語を抽出するもの。否定的先読み“(?!……)”の中で、カッコによるグループ化“(\w)”と、参照“\1”を利用して同じ文字を含むパターンが先行しないアルファベット文字の並び“\w+”を探す。2つめのgrepは「EARIOTN」のうち5文字を含むパターンを探す。
-
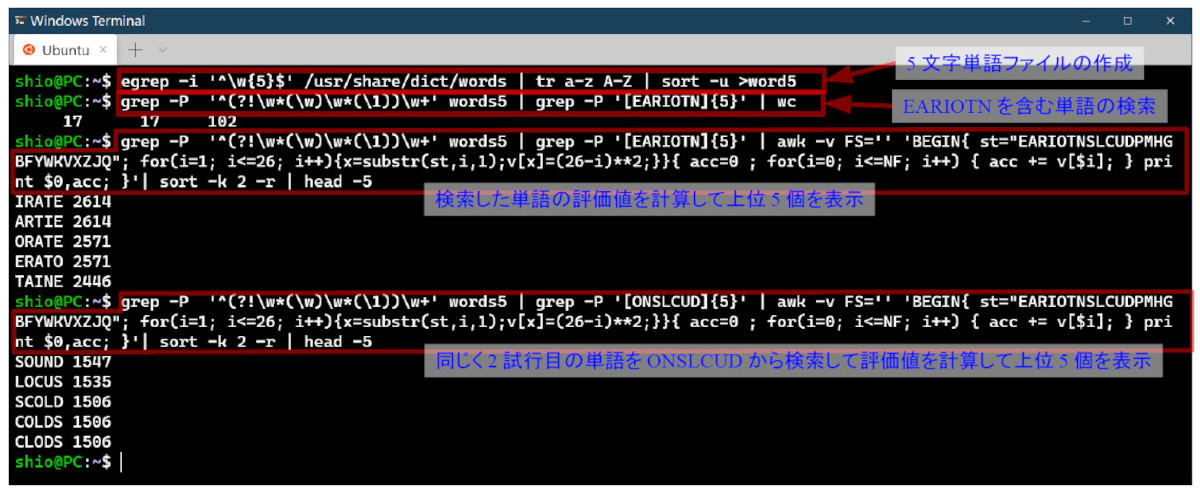
写真01: 5文字単語のリストを作り(1行目)、その中(word5)から文字が重複せず、利用頻度の高い文字を使う単語を検索すると候補は17個(2行目)。文字出現頻度を元にした評価値の合計で評価する(3行目)。awkのBEGINブロックは、順位から評価値を計算して連想配列に入れる処理である。一回目に試行すべきはIRATE、2回目(4行目)はSOUNDとするのが効率的なやり方と考えられる

grep -P '^(?!\w*(\w)\w*(\1))\w+' words5 | grep -P '[EARIOTN]{5}' | wcこの17個の単語に文字の出現順序に対して評価値をつけ、単語に含まれている文字の評価値合計を出す。それを計算して上位5個を表示するのが、下のコマンドだ。
grep -P '^(?!\w*(\w)\w*(\1))\w+' words5 | grep -P '[EARIOTN]{5}' | awk -v FS='' 'BEGIN{ st="EARIOTNSLCUDPMHGBFYWKVXZJQ"; for(i=1; i<=26; i++){x=substr(st,i,1);v[x]=(26-i)**2;}}{ acc=0 ; for(i=0; i<=NF; i++) { acc += v[$i]; } print $0,acc; }'| sort -k 2 -r | head -5最も評価値の合計が高いのはIRATEまたはARTIEだが、ARITEはWordleに撥ねられるため最初の試行ではIRATEを使うことにする。
2回目の試行は1回目の結果に関わらず、同様に確率の高い未試行の文字からなる単語を使う。1回目の試行でIRATEを使ったので「ONSLCU」(これ以下では単語が見つからない)で検索するとLOCUSだけが見つかる。この単語には現時点での出現確率が2番目になるNが入っていない。そこで1文字追加して「ONSLCUD」で単語を探すと12個が見つかる。同様にこれを評価するとSOUNDが浮上する。これが2番目としては適当なのではないかと思われる。この時点で未試行の文字は「LCPMHGBFYWKVXZJQ」である。
なお、この計算では、あくまでも辞書からランダムに選択されたような単語を想定しているが、Wordleはゲームなので、こうした手法が使われることを想定して出現確率の低い文字からなる単語を選んで出題するという可能性もあるため、必勝法ではないことにご注意願いたい。
さて、今回のタイトルの元ネタは、Edgar Allan Poeの“The Golden-Bug”(1843年)(邦題 黄金虫)である。暗号解読をテーマにした小説で「暗号物」の嚆矢と呼ばれる作品。解読方法として文字の出現頻度を使うという方法を一般に紹介した作品でもある。暗号物としてはホームズの「踊る人形」やルパンの「奇巌城」といった著名なものがあるが、黄金虫はその60年以上前に書かれていた。現在から約180年前の作品である。




