

Unicodeでは、収録した「文字」に名前と符号位置(文字コードの元になるもの)をつけて区別している。似たような字は複数あるが、それぞれに異なる符号位置と名前がある。ただし、残念なことに漢字に関しては、名前は付けられていない。Unicode制定初期の頃、全ての文字を16 bit空間に入れようとして、中国、日本、韓国の漢字で同じ形のものを1つの符号位置に統合してしまった過去があるからだ。統合したものは、それぞれの国で発音や表記がちがう別の文字であるため名前のつけようがないのである。もっとも、アルファベットに比べれば大量にあるので1つ1つ名前を付けるのは困難だっただろう。
Unicodeに収録されている文字は「Unicode Character Databse」(UCD)と「Unicode Han Database」(Unihan。漢字のみ)で検索できる。ちなみに“Han”は、中国語での「漢」の発音である。
Unicodeに収録されている文字は、Unicode.orgのサイトで調べることができる。たとえば、文字の名前からなら、以下のURLで調べることができる。
・Character Name Index
https://www.unicode.org/charts/charindex.html
Unicodeの符号位置からなら以下のページで閲覧ができる。
・Unihan Database
https://www.unicode.org/charts/unihangridindex.html
UCDもUnihanもDatabaseというが、実際に成果物として公開されているのはテキストファイルだ。だから、文字を表示するのは、これを読み込んで動作するプログラムにまかされている。とはいえ、プログラムを書くのはちと荷が重い。なのでExcelを使うことにする。
さて、UCDで公開されているテキストファイルのうち、もっとも重要なのは、UnicodeData.txtというファイルで、以下のURLでアクセスが可能だ。
https://www.unicode.org/Public/UCD/latest/ucd/UnicodeData.txt
このファイルは、Unicodeの符号位置を先頭に持ち、セミコロンで区切られた行形式のデータになっている。これをExcelで読み込めば、Unicode文字のデータベースになる。フィールドは(表01)のような構造になっている。定義は以下にある。
・UAX #44: Unicode Character Database
https://www.unicode.org/reports/tr44/tr44-26.html#UnicodeData.txt
| ■表01 | ||
|---|---|---|
| 位置 | フィールド名 | 意味(簡易) |
| 0 | Code point | 符号位置または範囲 |
| 1 | Name | 文字の名前 |
| 2 | General_Category | 分類 |
| 3 | Canonical_Combining_Class | 正準結合文字のクラス |
| 4 | Bidi_Class | 双方向文字クラス |
| 5 | Decomposition_Type | 分解のタイプ |
| 6 | Numeric_Type-Numeric_Value | 10進数(Numeric_Type=Decimal)の値 |
| 7 | Numeric_Type-Numeric_Value | 数字(Numeric_Type=Digit)の値 |
| 8 | Numeric_Type-Numeric_Value | 数値(Numeric_Type=Numeric)の値 |
| 9 | Bidi_Mirrored | 双方向のとき鏡面対称になるか |
| 10 | Unicode_1_Name | 旧Unicode 1.x時の名称 |
| 11 | ISO_Comment | ISO 10646のコメントフィールド |
| 12 | Simple_Uppercase_Mapping | Upper Caseの場合の符号位置 |
| 13 | Simple_Lowercase_Mapping | Lower Caseの場合の符号位置 |
| 14 | Simple_Titlecase_Mapping | Title Caseの場合の符号位置 |
まずは、UnicodeData.txtを読み込もう。これには、ExcelのPowerQueryという機能を使う(図01)。ちなみにExcelは、Microsoft 365版を想定しているが、Excel 2016でも同じ事ができる(ただしメニューやダイアログ名称、手順には違いがある)。
-
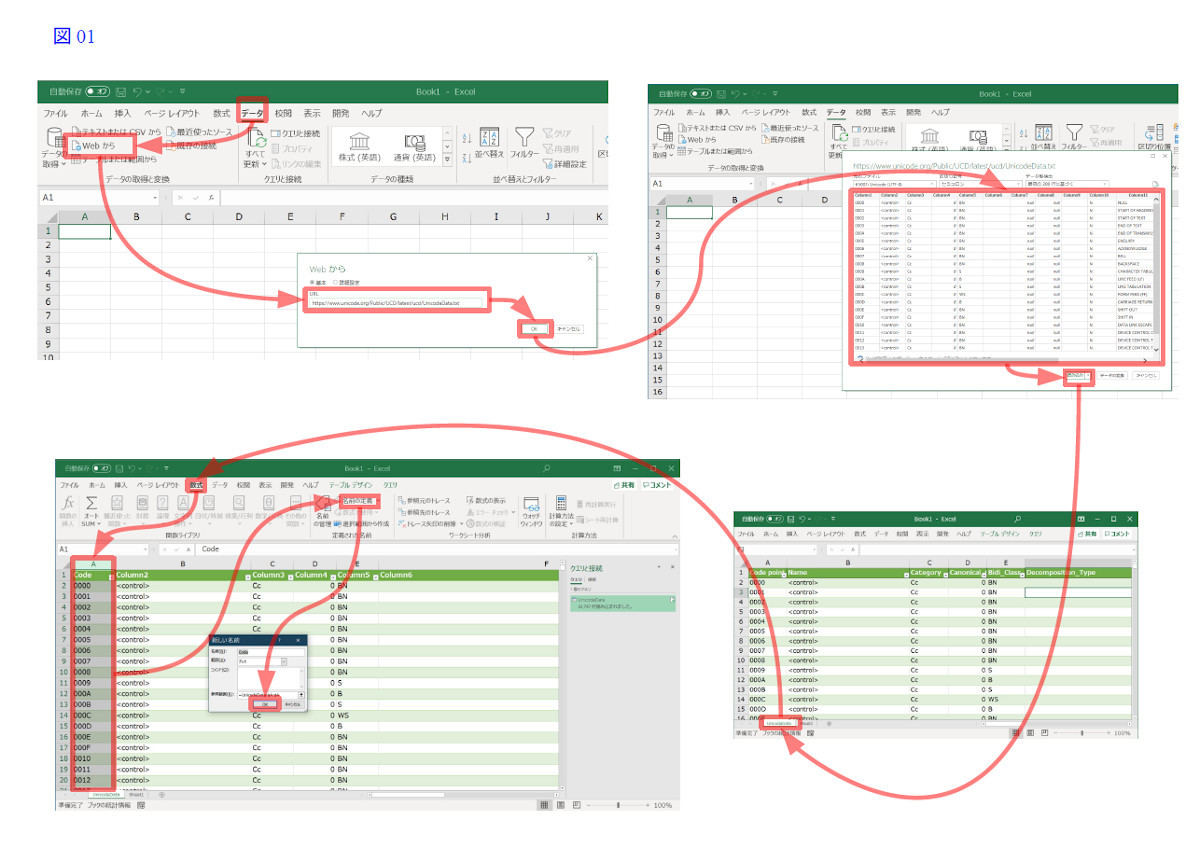
図01: リボンのデータタブにある「データの取得の変換」にある「Webから」をクリックして、UnicodeData.txtのURLを入れる。するとPowerQueryのダイアログが開くので、「読み込み」ボタンを押す。UnicodeData.txtがシートに読み込まれたら、1行目にフィールド名を入れる(表参照)。そして各列に数式タブの「名前の定義」で「名前」を付ける。先頭行にフィールド名を設定してあれば、それが名前になる

UnicodeData.txtから作られたテーブルの各列に名前を付けるのは、他のシートから参照するためだ。なお、標準状態では、自動更新されることがあるので、手動でのみ更新するようにしておく(クエリのプロパティダイアログの使用タブにあるコントロールの更新の項目を全てオフ)。UnicodeData.txtは、Unicodeバージョンに連動しているため、更新は最短でも年一回程度である。
Excelでは、Unicode文字はUNICHAR関数で表示でき、UNICODE関数で文字から符号位置を取得することもできる。読み込んだUnicodeData.txtは、VLOOKUP関数を使えば、先頭のコードをキーに各フィールドを取り出すことができる。まずは、新規のシートに表を作る。検索キーになるのは、Unicodeの符号位置だ。ここでは、Unicodeでハイフンやダッシュなど、横棒の文字のキーを集めてみた。
Unicodeの符号位置は、通常「U+2010」など「U+」を先頭につけた16進数で表現されるが、ここでは、「U+」なしの16進数を左端(仮にA列とする)に置いた。隣にUNICHAR関数「=UNICHAR(Hex2Dec(A1))」、そしてVLOOKUPを並べる(図02)。とりあえずNameフィールドを取り出す場合、見出し行に、Nameフィールド列につけたExcelの「名前」(Name)を置き、以下のようにVLOOKUP関数を使う。
=VLOOKUP($A2,UnicodeData,COLUMN(INDIRECT(C$1)),FALSE)-
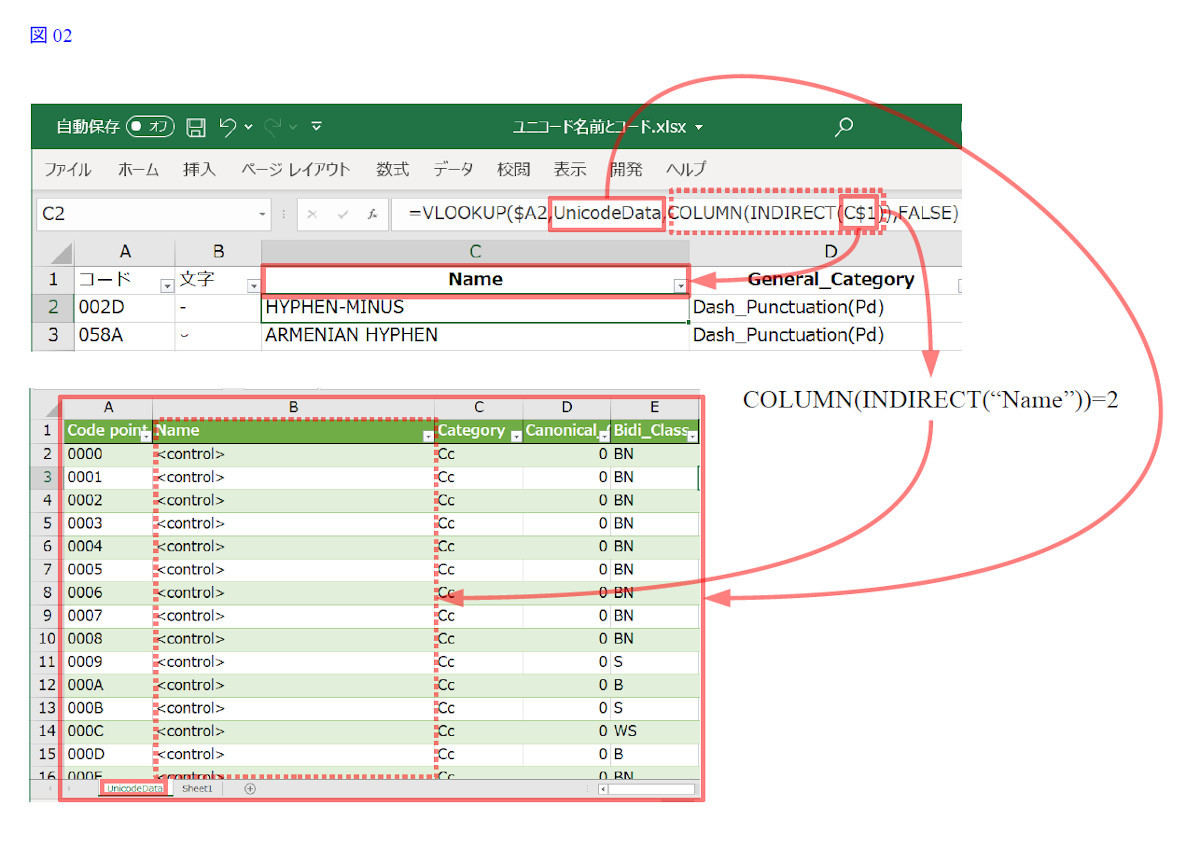
図02: 符号位置から情報を引き出すには、A列に符号位置(コード)を入れ、VLOOKUP関数を使う。このとき、UnicodeData.txtを読み込んだテーブルの名前(UnicodeData)と自分でつけた各列の名前を使うと、テーブルの列(フィールド)を簡単に取り出せる

数式は同一のままで、見出し行に必要なフィールド名を並べれば、データを取り出してくれる。だから、数式はオートフィルでコピーするだけでよい。ざっと探しただけでUnicodeには、横棒となる記号文字(Dash_Punctuation)が30個近くあった。その他にも、漢数字や音引き、罫線文字などもある。さすがに形から検索することはできないが、General_CategoryがPd(Dash_Punctuation)になるものを探すことは可能だ。
UnicodeData.txtには、文字の組み合わせで作られる合字(正式には分解可能文字。Composite Characterという)などに関する情報もある。たとえば日本語のカタカナ、ひらがなの濁音文字は、清音文字と濁点の組み合わせで表現することも可能だ。これを示すのが「Decomposition_Type」だ。たとえば「が」(U+304C。HIRAGANA LETTER GA)では「304B 3099」になっていて、304Bは「か」(HIRAGANA LETTER KA)、3099は濁点(COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK)を表す(写真01)。
-
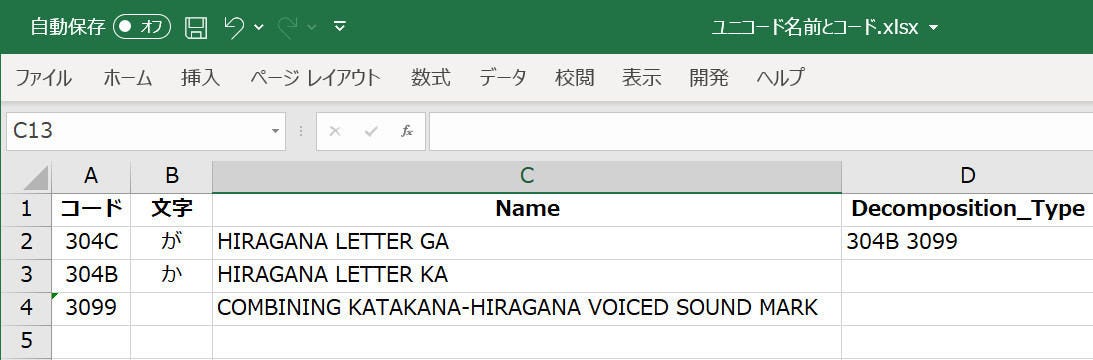
写真01: ひらがなの「が」は、「U+304B」と「U+3099」に分解できる。「U+304B」は「か」、「U+3099」は日本語のカタカナ、ひらがな用の濁点である

Excelが便利なのは、テキストを読み込んで、データベースのようなものを簡単に作ることができる点だ。しかも、ほとんどの場合プログラム(VBA)さえ書く必要がない。筆者は毎日のように仕事でExcelを使っているが、プログラムを書くのは年に数回程度だ。もし、プログラムを書かねばならないとしたら、そもそもExcelでやるべきことなのかを考えた方がよい。




