Driverless AIにおけるデータ分析(機械学習)は「Experiment」画面で行います。
活用方法としては、例えば、収集したセンサーデータから製品や設備の特定の異常を検知する、顧客の行動履歴データから顧客の信用を評価する、サービスの履歴データから不正利用を検知する、などが挙げられます。
機械学習の設定
Experimentの設定画面では、まず、学習用のデータセット、予測したい「答え」の変数(教師ラベルの変数)、最終的な予測モデルのテスト用データセットを指定します。するとDriverless AIがデータセットの中身からExperiment設定を自動調整してくれるので、そのまま下の「Launch Experiment」をクリックすればデータ分析を実行できます。
-

図7:Experiment設定画面

あとはExperimentプロセスの完了を待つだけです。プロセスの進捗はいつでも確認できるので、ブラウザ画面を閉じてしまっても問題ありません。
-

図8:Experiment進捗画面

特徴量エンジニアリングの自動化
このExperimentの実行中に動いているのは、機械学習アルゴリズム(GLM・XGBoost・LightGBM・TensorFlowなど)の選択・ハイパーパラメータの調整・特徴量エンジニアリング、といった選択と調整のプロセスと、調整されたモデルの学習のプロセスになります。
「特徴量エンジニアリング」とは、データの変数(特徴量ともよばれます)から、機械学習で精度のでやすい形の変数(特徴量)を生成していくプロセスです。
例えば、「製品分類」というカテゴリデータは機械学習で扱いづらいため、「このカテゴリか否か」の二値データで表す、カテゴリの頻度を計算してその値で置き換える、などその特徴を数値データの形に変換する必要があります。
また、数値データに対しても、足し合わせたり掛け合わせたり、クラスタリングを試したり、などの処理によりデータの特徴が強調されてモデルの予測精度が上がることがあります。
上記のような「どの変数をどう変換するのが有効か」は、データの特徴や、データと教師ラベルの関係性、また機械学習アルゴリズムでも変わってしまうため、特徴量エンジニアリングはデータの扱い方に関する知識や経験値に加えて試行錯誤が重要なプロセスになります。
Driverless AIの大きな特徴は、Experimentにおいて、特徴量の生成・機械学習の実行・学習結果の精度評価、のサイクルを何度も繰り返すことで、有効な特徴量(と機械学習アルゴリズム)を自動で探索し、予測モデルの精度を高めていくことです。
生成された特徴量やその生成の手法については、変数重要度の欄に表示されるほか、Experiment完了後に取得できるレポートでも確認できます。
機械学習の調整
Experimentのプロセスに対して調整を行いたい場合は、Experimentの設定にて表示される「Accuracy」「Time」「Interpretability」のつまみと「Scorer」の選択で調整できます。
調整後のExperimentの挙動については、左側の欄に詳細説明が表示されます。機械学習アルゴリズムの候補・学習プロセスの繰り返し回数・特徴量エンジニアリング手法の制限などの項目が変動します。
-

図9:Experimentの設定調整

機械学習の結果の確認
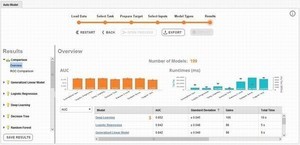
Experiment完了後は、このような画面になります。
-

図10:Experimentの設定調整

Experimentのサマリ、変数の重要度、予測モデルの精度の推移、ROC曲線、混同行列、予測誤差の分布、などExperimentの結果の情報を確認できます。
また、学習用・テスト用データセットの予測結果のダウンロード、他データセットに対する予測の実行、予測モデルを外部の環境で実行するためのモジュール(Pipelineとよばれます)のダウンロードなど、生成された予測モデルを活用するための機能が利用できます。
なお、Experimentのデータ分析機能ですが、対象は数値データやカテゴリデータだけでなく、時系列データに対する将来予測や、テキストデータに対する自然言語処理(NLP)にも対応しています。今回は割愛しますが、ご興味あればお試しいただければと思います。(日本語テキストのNLPの場合、事前に分かち書き処理をしてからデータをアップロード・分析したほうが分析精度は上がるようです)
以上、今回はDriverless AIの概要と、データセットの確認およびデータ分析の方法について説明しました。次回は、Driverless AIをさらに使いこなすための機能を紹介します。
著者プロフィール
有馬 直尭
ネットワンシステムズ株式会社
ビジネス開発本部 第1応用技術部
2018年入社。前職にて運用自動化への応用を目的とした機械学習の検証を担当していた縁で、入社後は製造業におけるデータ分析PoC案件に携わる。現在は主にデータ分析関連ツールの調査や検証に従事している。