今回紹介するツール「Elastic Machine Learning」は、ログなどの膨大な時系列データに教師なし機械学習を行うことで、従来型の閾値監視では気付けないような「いつもと違う」データを異常として検知可能にします。
主な用途としては、サーバやネットワーク機器などの障害につながるような異常の検知、Webアプリケーションへのアクセス数の急増(急減)の検知などが挙げられます。
今回は、Elastic Machine Learningの基礎編として、異常値の検知、原因の分析、将来予測などの基本的な操作方法を紹介します。
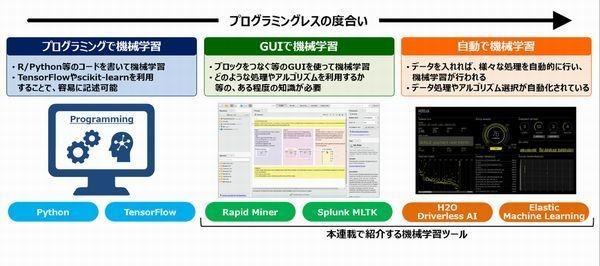
前回に取り上げたRapidMinerと同様、このElastic Machine Learningもプログラミングを行うことなく、GUIによる操作で機械学習が可能です。自社の環境に生かせると感じた方は、ぜひ挑戦してみてください。
Elastic Machine Learningとは
まず、Elastic Machine Learningの位置づけを説明します。Elastic Machine Learningは、Elastic社が提供している「Elastic Stack」の有償の拡張機能です(一部無償機能あり)。なお、30日間はMachine Learningを含めた全機能を試用できるため、気軽に試すことができます。
Elastic Stackは、オープンソースのプロダクト群であり、全文検索エンジンである「Elasticsearch」 、データの取り込み・加工処理・転送を行う「Logstash」 、Elasticsearchに貯めたデータを可視化するGUIツール「Kibana」 、データ取り込みに特化した非常に軽いエージェント「Beats」 から構成されています(本稿はElastic Stack ver.7.4.2で作成し、Kibana内にあるサンプルデータを用いています)
-

図1:Elastic Stackのコンポーネント

特徴は「いつもと違う」「まわりと違う」データを検知
Elastic Machine Learningは、Elasticsearchに貯めた時系列データに対して、教師なし機械学習を行います。これによって、時系列データのふるまいを学習してモデルを作成するとともに、「いつもと違う」「まわりと違う」データを、異常として検知することができます。特徴は、従来行われているような、事前に設定した閾値による監視では気付けないような異常に気付くことができる点です。
-

図2:周期性のあるデータに含まれる「いつもと違う」点

なお、時系列データの周期的な特性をモデルに反映させるには、取得するデータの取得間隔にもよりますが、最低4~5周期分のデータが必要です。
Data Visualizer:データ概要を把握
機械学習を行う際は、扱うデータの概要をあらかじめ把握しておくことが重要です。Elastic Machine Learningでは、「Data Visualizer」機能を使うことで、簡単にデータの数、ユニーク値の数、数値データの統計量(最小値・中央値・最大値)、ヒストグラムなどを表示することができ、データの概要把握に大きく役立ちます。
-

図3:Data Visualizerを使ったデータの把握

Elastic Machine Learningは、定常状態をモデル化した上で異常を検知するため、扱うデータの中に外れ値や意図していない値があると、良いモデルが作れないことがあります。そこで、この「Data Visualizer」機能で可視化した外れ値をあらかじめ排除することで、より適したモデルを生成できます。
Single Metric Job:異常の検知
では、実際の機械学習に入っていきます。最初に、単一のデータを対象にする「Single Metric Job」を用いて機械学習を行い、異常を検知します。
Single Metric Jobでは、以下の5ステップで設定します。
- Time Range(対象とする時間の設定)
- Pick Fields(対象とするデータをどのように集計するかの設定)
- Job details(Job idやdescriptionの設定)
- Validation(ここまでの設定が適切であるか確認)
- Summary(Jobの実行)
-

図4:Single Metric Jobの設定

今回は事前に準備した静的なデータ(Kibana内にあるWebサイトのトラフィックログのサンプルデータ)を使って分析していますが、作成したモデルに対してリアルタイムに取得したデータを評価し、異常なふるまいが起こっていないか随時確認する、という使い方もできます。
Single Metric jobの結果として、図5のような画面が表示されます。


-

図5:Single Metric jobの結果

濃い青色の実線が機械学習に使った値(実測値)で、実線の周りの水色で示されるエリアが機械学習によって求められた正常値の範囲です。図5の(1)を見ると、最初の数周期分のデータを学習した後にモデルが作成され、正常値の範囲がある程度定まったことがわかります。
(2)、(3)では異常を検知している様子(赤点や黄点)を表しており、明らかな外れ値だけでなく、微小な変化も周りとは異なる点として検知していることがわかります。検知された点は異常度(Anomaly score)が表示されるため、その後の対応に使うこともできます。
Multi Metric Job:異常の原因を分析
次に、複数のデータを分析対象にする「Multi Metric Job」を使います。Single Metric Jobでは、異常の発生には気付くことができますが、その原因まではわかりません。Multi Metric Jobは、複数のデータを分析することで、その異常を発生させた原因を調べやすくすることができます。
基本的な設定の流れはSingle Metric Jobと同じですが、分析対象とするデータを複数選択でき、それをどのような切り口で分析するかを指定することができます。
図6は、同じくウェブサイトのトラフィックログを分析対象として、アクセス数に対して時間帯とアクセス元の国を切り口として、Multi Metric Jobを行った結果です。時系列に並んだデータに対し、赤色や黄色で表示された時間帯に異常が発生していることを表しています。


-

図6:Multi Metric Jobの結果

(1)から特定の時間帯でアクセス数に異常があったことがわかり、(2)、(3)からインドからのアクセスが多くなったことによるものだと特定できます。あらかじめ分析したい観点でデータを入れておく必要がありますが(この例では、アクセス元の国)、事前準備をすることで分析が楽になります。
Forecast:将来予測
さらに、Elastic Machine Learningには、将来の値を予測する「Forecast」機能があります。機械学習の対象としたデータの取得間隔や量によりますが、最大10年先までの値を予測できます。
この機能の利用例としては、将来の値を予測して、あらかじめ設定した上限値に達したときにメールで通知し、障害発生前に対策を取る、といった予防保全があります。
-

図7:Forecast機能を使った、値の将来予測

人間の知識を機械学習に反映させる
データの裏にある、人間だけが知っている情報もあります。例えば、祝日や計画停電などで、取得するデータがいつもと異なることがあらかじめわかっている場合です。また、「特定のマシンのみCPUの使用率を監視したい」「特定のIPが起こしたイベントは監視から除外したい」という要望もあります。
こうした要望に対しては、図8の(1)のように、機械学習の対象から除外する設定も可能です。また、(2)のように、機械学習の結果から人間が判断したことを書き残しておく(アノテーション:正解のタグ/ラベル)ことで、気付きを共有することもできます。

-

図8:便利な機能

今回は、Elastic Machine Learningの基本的な機能を紹介しました。次回は、より複雑な分析を実現する最近追加された機能や機械学習の結果の活用例を解説します。
著者プロフィール
片野 祐
ネットワンシステムズ株式会社
ビジネス開発本部 第1応用技術部
ネットワンシステムズに新卒で入社。仮想化技術、ハイパーコンバージドインフラ、データセンタースイッチやネットワーク管理製品の製品担当を経て、現在はAI関連技術の技術調査やデータ分析業務の経験をもとに、さまざまな場面でのデータの利活用を推進している。