最近、AI(人工知能)を使ったシステムやサービスで「自然言語処理」という言葉を目にすることが増えてきました。「第3次AIブーム」と言われてから月日が経過したAIですが、これまでは囲碁や将棋などのゲーム、車の自動運転、さらには画像・映像から何かを見つけ出す、判別するといった話が目立っていたように思います。
言語に関しては、ブーム当初は短文の自動応答であるBOT(ボット)で「AIが差別発言をした」といったことや女子高生AI「りんな」などが注目されました。
1. 自然言語処理とは?
AIの利用がある程度進み、成果の有無はさまざまなケースがありますが、次なるデータとして関心を集める「言語」を処理する機械学習技術の発展もあり、「自然言語処理」に注目が集まってきています。
数多くあるAI関連技術の中でも、身近なのに応用範囲が広く、使い方が多様なのが自然言語処理に関する技術ではないでしょうか。自然言語とは、私たち人間が普段使っている言語であり、そのデータは日常にあふれています。
例えば、日々やり取りしているメールやチャット、SNSのコメント、面談記録、日報、電子カルテ、問診記録、さらには電話などの会話も音声をテキストに変換することで解析することが可能になります。このような自然言語のデータを分析する上で、自然言語処理の技術が大変重要となっています。
-

自然言語データの種類

では、改めて「自然言語処理」とは何でしょうか?一言で説明すると“人間が普段使っている言語(=自然言語)をコンピュータで処理する技術"です。人が日常で使っている、自由に話している言語を、意味や構造などさまざまなアプローチで分解し、現代のAIの最大の特徴である“コンピューティングパワー"を使って処理や解析を行えるようにするものとなります。
余談ですが、第3次AIブームが生まれたのは「ビッグデータ」と「コンピューティングパワー」のおかげと言われていますが、実は「コンピューティングパワー」と「クラウドを含むネット環境」が肝とも言えると思います。「ビッグなデータ」は、これまでも世界中の業務システムの中にありました。
また、AIを使う時に必ずしもデータは「ビッグ」である必要はないこともあります。もちろん、人間では簡単に処理できない量だからこそ、AIが役立つのですが、それよりもネットを通じて、多種多様なデータがクラウド環境などを通じて集まり、容易に検証できることが現在の状況を作ったと考えられます。
2. 自然言語処理は、何が難しいか?
注目を集めている自然言語処理ですが、実は難しい点が多くあります。一番の課題は「数値ではない」ことが挙げられるでしょう。「AIを使う」とは、プログラムやアルゴリズムを用いることです。文字や文章そのままの形ではコンピュータは処理できないため、何らかのデータに変換しなければなりません。
画像や数値の場合、ある着目点や閾(しきい)値、データの分岐点を理解していれば、処理や判別が可能です。しかし、言語の場合はまず、処理できる数値などに変換することからはじまり、どのように変換することが適切かといった処理方法、アルゴリズム、自然言語ならではの曖昧さや特性など、コンピュータにとって扱いづらい点が多くあることが難しくしているのです。
ここで、自然言語処理の具体的な方法を解説してみます。まず、単体で意味を持つ最小の単位で文章を区切る「形態素解析」で、品詞(名詞、動詞、助詞、形容詞など)を判別します。特に、日本語や中国語、韓国語をはじめとしたアジアの言語は、欧米などの言語と異なり、単語が区切られていないため、形態素に分けることが重要です。
さらに、目的にもよりますが、品詞に加え、主語、述語などの言葉の並びや関係を明らかにする構文解析や、語の出現位置などは考慮せず、文章に単語が含まれているかどうかのみを考える手法(Bag of Words)などを用いたりします。
-
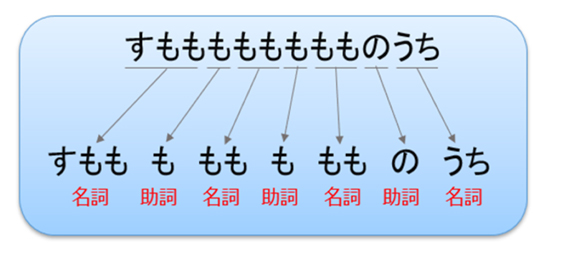
日本語の形態素解析の例

昔からよくあるやり方では、形態素解析や構文解析の情報を大規模に集め、構造化した「コーパス」や、単語の意味、同義や類義関係、上位/下位の関係を大規模に集めた「シソーラス」といった言語のデータベースを用いて、文章の意味理解、文脈理解を行うアプローチもあります。
ただし、単語の意味は日々移り変わっていくため、こういった辞書的なアプローチを行う場合、古い解釈で解析していては、求める結果を出すことは難しくなります。例えば、「ヤバい」という言葉はそもそも良くない意味で使われる言葉でしたが、今では「すごい」といったような良い意味で使われることが増えています。
そのため、最新の情報を解析しなくてはならない場合、特にニュースやマーケティング、医療のような分野では、データの更新を常にしなくてはなりません。
加えて、言葉そのものや意味の曖昧さのほかに方言や国籍、業界特有の用語、年齢による表現の違いなど、言葉のバリエーションが異なるため、どのように特徴やパターンを捉えて、大量のデータの中から、見つけるべき言葉や文章を見つけるかがポイントとなります。
“言語を処理する"には、大変な労力がかかることがなんとなくイメージできてきたかと思います。次回は、私たちの身近にある「自然言語処理xAI」の実際の使われ方を紹介します。
著者紹介
FRONTEO行動情報科学研究所
行動情報科学に基づいたビッグデータ解析および人工知能の研究開発を行っています。自然言語処理、機械学習の適用、アプリケーション開発などを推進し、サービスの運用から得られるユーザー体験を研究開発へとフィードバックすることで、開発のサイクルを加速し、社会に役立つ製品づくりに取り組んでいます。