DeepLは7月17日(ドイツ時間)、言語翻訳や文章校正に特化した次世代の大規模言語モデル(LLM)を実装したと発表した。
この実装はDeepLの翻訳サービスを大幅に強化するものという。言語学者を対象としたブラインドテストでは、英語と日本語および中国語簡体字を組み合わせた翻訳で、従来モデルに比べ1.7倍の顕著な改善を示したとした。
-

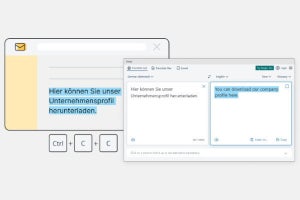
DeepLの会社概要

今回実装した新たな次世代言語モデルの特徴は、「特化型大規模言語モデル」「独自データ」「言語専門家によるモデルチュータリング」の3点。
具体的には、特殊な調整を施した言語に特化した“特化型LLM”を活用することで、偽情報や誤情報のリスクを低減し、従来より高い精度で文脈を捉え、より人間的な翻訳と文章作成を実現した。
また、ネット上に公開されている情報を学習する汎用AIモデルではなく、文章作成および翻訳のために特別にチューニングされた7年分以上の独自データを活用。このほか、特別に訓練された数千人の言語専門家によるモデルチュータリングを行ったとする。
同社がプロの翻訳者を対象として、次世代言語モデルをブラインドテストした結果、参加した言語専門家は、Google翻訳と比べ1.3倍、ChatGPT-4と比べ1.7倍、Microsoft翻訳と比べ2.3倍、DeepLの翻訳出力が好ましいと回答したという。
DeepLでは新たなLLMの実装で翻訳精度が大幅に向上したことで、手作業での校正にかかる時間を節約できるほか、チームや国・地域・市場を超えた、より効率的なコミュニケーションが可能になるとしている。