米Tabulaは2012年2月24日に都内で記者発表会を開催、Tabula本社から来日したAlain Bismusth氏(Photo01)が説明を行い、同社の3次元PLD(3PLD)の次世代製品に、Intelの22nmプロセスを利用することを明らかにした。

|
|
Photo01:TabulaのVice President of MarketingであるAlain Bismuth氏 |
Tabulaは2010年3月に、同社としては初製品になるABAXファミリを発表した。昨年6月には品川に東京事務所を開設しており、また昨年9月にはPresident兼CEOのSteve Teig氏が来日して説明を行うなど、日本でも積極的に活動を行っている。
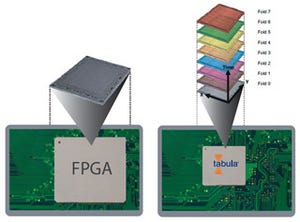
とはいえ、同社のSpacetime Architectureはまだ馴染みが薄いこともあって、まずはその説明を行うことに時間が費やされたが、これをもう少し簡単に説明してみたい。単純に言えば、3PLDは内部が2/4/8倍速で動くFPGAである。ただ面白いのは、各々のロジックセルが単純に2~8倍速で動くのではなく、毎サイクルごとにLUTの中身を切り替えて動作する。その結果として、例えば8倍速の場合であれば1つのロジックセルが見かけ上は連結された8つのロジックセルとして動作する(各々のロジックセルの速度は200MHz)という仕組みだ。これにより、必要とされる回路規模に対して、少ないロジックセルと配線でFPGAを実現できるという点が同社の強みである。
ここで既存のFPGAで問題になるのは、ロジックセルそのものよりもむしろ配線遅延だと氏は説明した(Photo02,03)。

|

|
|
Photo02:同社がPrimary TargetとしているTelecommunicationの分野では、通信速度の伸びにトランジスタの数や、そのトランジスタのゲート速度は全然追いついていないが、それよりも問題なのは次に説明する配線だと説明した |
Photo03:FPGAの問題。各々のブロックが異なるスピードで動作し、しかもその配線に限界があるために性能が上げられないという話 |
氏が例に取ったのは100GbpsのNon-Blocking Switchである(Photo04)。システム全体の帯域を確保するために、各々のメモリコントローラとは、最大512bitものバス幅で接続されることになる(Photo05)。これはFPGAの内部の信号が200MHz駆動で、必要とされる帯域が100Gbpsであれば、無条件に決まってしまうわけで回避しようがない(Photo06)。

|

|

|
|
Photo04:これは非常にラフな構造だが、と前置きして説明した。中央にあるのがFPGAで構築されたNon-Blocking Fablicであるが、そこには4ポートの100Gb EMACの他に4ポートのDDR3メモリコントローラが接続される |
Photo05:メモリチップ側そのものは、必要とされる帯域とメモリチップの性能で決まるので、これはどうしようも無い。ただDDR3 PHYとDDR3 Controllerの間が512bit×2というのが大問題という話 |
Photo06:今は100Gbpsだから512bitで済んでいるが、この先更に広い帯域が必要になると、更にピン数が増える事になる |
これに対し、Spacetime Architectureでは全てのブロックがもっと高速に動作する。このため、単にロジックセルの節約が可能なだけでなく、配線の節約にも効果的というのが氏の主張である(Photo07)。例えばメモリコントローラに関しては、DDR3 PHYとFablicの間は2.4GHz/64bit、DDR3 PHYとDDR3 Controllerの間は1.2GHz/128bit構成とすることが可能で、これにより大幅に配線が節約できる、としている(Photo08)

|

|
|
Photo07:2GHz、というのは単に説明上での都合で、実際の製品は1.6GHzとなる |
Photo08:BRAMそのものも高速化することで、こちらの配線も節約可能 |
さて、ここまではいわば長い前置きであって、本題はここから。2月21日~23日に掛けてサンノゼで開催されたEthenet Technology Summitにおけるパネルディスカッションに同社も招かれ、この中でTabulaは次世代製品をIntelの22nmプロセスを使って製造することを明らかにした。Intelは昨年11月に、同じくFPGAベンダであるAchronixの次世代製品の製造を行うことを明らかにしている(その1、その2)が、これに続いて2社目という事になる。氏によれば、「Intelの22nmプロセスは業界でも最先端のもので、これを組み合わせることでより低い消費電力と高い性能を実現することが出来る」としている。ただし、具体的な動作周波数とか集積するロジックセル数、サンプリング/量産時期などについては「現時点では一切公開できない」とした。ただ今年第2四半期にはもう少し詳細な情報を公開できると思う、との事であった。またIntelはこの件に関し「Tabulaの次世代製品の製造を行うのは事実だが、それ以上の詳細は現在公表できない」(インテル)との事であった。
発表内容は概ね以上であるが、質疑応答の内容などを踏まえつつ若干の考察など。Tabulaの場合、主にターゲットとしている顧客は現時点ではTelecommunication向けがメインとの事。今回なぜIntelをファウンドリとして使ったか、という質問に対し顧客の要望があったことを明らかにしており、やはり問題は動作周波数にあると考えられる。既存のABXAはTSMCの40nmプロセス(恐らく40nm Gと思われる)を使って1.6GHz駆動を実現しているが、これはTSMCの40nmとしてはかなり高い周波数の部類に入っている。ただここまでしても、見かけ上は200MHzのFPGAとしてしか見えないのがSpacetime Architectureの弱点である。勿論、400MHzとか800MHzとして扱うことも可能なのだが、その場合は4倍速/2倍速扱いになるわけで、今度は見かけ上のロジックセル数が不足する事になる。しかも1.6GHzと非常に高い動作周波数なので、セルの数を増やすと消費電力が急増することになる。
従って、もう一段上の性能を狙おうとする場合、最低でも2GHz、出来れば3GHz程度で連続動作するプロセスがどうしても必要になる。これはTSMCなどの28nm LPはもとより、28nm Gプロセスでもなかなか実現困難な数字である。Tabulaの場合、微細化によるトランジスタ数増加はあまり大きなメリットになっておらず、むしろ動作周波数を引き上げることが求められているからで、このあたりを勘案すると28nmのHS(High-Speed)プロセスを持ち込まないと間に合わないと思うが、今度は消費電力が急増するから、明らかにバランスを崩すことになる。Intelが22nm世代でTri-Gate構造を導入し、リーク電流を下げつつ高速動作を可能にしたトランジスタを手にしているのは、Tabulaにとって大きなメリットと映っただろう事は想像に難しくない。ちなみにこの22nm世代の製品の動作電圧だが、Startup Voltageは0.8V以下になるだろうと氏は述べている。
ではIntelの側からみるとメリットは何か?という事だが、22nm世代ではインプリメントの実績を若干増やす程度であまり大きなものはないだろう。Acronicsの際にはIntelが公式blogで「Acronicsの製品の製造は、22nmプロセス全体からみてごくわずかな量で、大勢には影響しない」としており、これは今回のTabulaについても恐らく同じことだろうと思われる(今のところIntelの公式blogにもTabulaに関する言及は見当たらない)。ただIntelの戦略は「他社に先んじて先端プロセスを導入し、大量出荷を行うことでマーケットを取る」事だが、先端プロセス製造に必要なコストがどんどん増えている関係で、今後はより多くの製品を出荷しないと開発費がカバーできない状況が見えつつある。そうした状況を自社製品の製造だけで無理やり賄うのか、あるいはIBMの様に自社製品に加えてファウンドリビジネスも兼業することで数量をカバーするのか、に関する明確な回答は今のところ出ていないと思われるが、ファウンドリビジネスを始める場合に備えて今のうちに経験を積んでおこう、と考えるのは不思議なことではない。
またFPGAの製造であれば、Intelの現在のビジネスと殆ど競合しないし、必要なのは高速ロジックと高速なSerDes、メモリコントローラ程度であるから現在のCPU向けに必要とされるIPがそのまま流用できる。この(Intelにとっての)敷居の低さも、今回の提携につながったものと考えられる。
ちなみにIntelとTabulaの関係であるが、あくまでも製造委託のみであって、それ以上の技術的な提携などは「今のところない」(Bismuth氏)との事であった。