Intelの小林氏のXeon Phiでの圧縮流体プログラムの最適化
続いて、Intelの小林広和氏が圧縮流体プログラムのXeon Phiでのチューニングについて発表した。対象は、青木教授から貰った圧縮流体のソースコードである。このオリジナルのコードをそのままコンパイルして実行すると、性能は73.8GFlopsであったという。
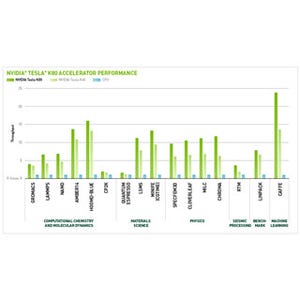
Intelの性能解析ツールであるVtuneを使って、効率の悪い部分を見つけ、それを改善するというステップを繰り返し、各ステップでどのような変更を行ったかは、ここでは省略するが、次の左側の図のように、22ステップのチューニングで、最終的には760GFlopsと10倍あまり性能を改善したという。
右の図は、効果の大きかったチューニング項目を抜き出したもので、一番効果があったのは、OpenMPによる並列化の部分で正しくPrivate指定を行うことで、これで2.48倍の性能向上が得られた。OpenMPは、デフォールトでは並列部分の中で使われる変数を共通変数として扱うため、スレッド間のメモリアクセスの排他制御が必要となり、変数のアクセスに非常に時間が掛かってしまう。本来、共通である必要がない変数はPrivateと指定すれば、スレッド個別の変数となり、排他制御は不要でアクセスは遅くならない。
また、このプログラムでは単精度浮動小数点数を使っているが、「3.0*a」などと書くと、文法上、aを倍精度に型変換し、それに倍精度の3.0を掛け、その結果を単精度に変換するという処理になる。これを「3.0f*a」と書けば、両方が単精度になるので型変換は無くなる。これにより性能が1.12倍に向上したという。小林氏は、これらはプログラムを書くときに気を付けて丁寧に書けば避けられると指摘した。
境界処理をループ外に追い出す変更で性能が1.24倍に向上した。ループの内側の処理はできるだけシンプルにすることが重要という。また、ブロッキング、プリフェッチの追加、一時領域の利用など、メモリアクセス回数を減らすことが効果的と指摘した。

|

|
|
青木教授の元のソースプログラムに22ステップの変更を加えて、性能を10倍あまり向上した |
性能改善効果が大きかったチューニング項目 |
首都大学東京の大久保准教授の電磁界解析のリアルタイム可視化
続いて、主催者でもある首都大学東京の大久保 寛准教授が、「リアルタイム可視化を目指したFDTD法電磁界解析におけるメニーコア計算の性能比較」と題する発表を行った。

|
|
発表を行う首都大学東京の大久保准教授。このワークショップの主催者の1人である |
次の左側の図に示すように、FDTD法も格子を使って計算するアプリケーションで、各セルでの演算数は少なく、メモリバンド幅が律速になるアプリケーションであるという。
次の右側の図は、CPUとMIC、GPUによるFDTD法の電磁界解析の計算速度を示すもので、横軸はセル数、縦軸は1秒あたりの処理セル数である。総じてCPUが一番遅く、次いでNativeのMIC。OffloadのMICはOpenACCでプログラムしたGPUと、まあ、同程度の性能である。そして、GPUは、CUDAでプログラムを書いた場合はOpenACCで書いた場合に比べて3~5倍の性能となっている。

|

|
|
FDTD法の電界計算コードの基本部分。計算が少なく、メモリアクセスが律速になる |
CPU、Xeon Phi、各種GPUでのFDTD法での電磁界解析の性能 |
リアルタイムで解析結果の描画も行おうとすると、描画速度も問題となる。次の左側の図は、CPU側のRAMからVRAMに転送して表示する時間とMICのメモリからCPUのRAMに転送する場合、そして、GPUで処理を行った場合の描画時間を示している。
CPUのメインメモリからVRAMへの転送は643セルの場合、PCIe2.0の場合は23.9msで、PCIe3.0ではその半分になる。一方、MICからメインメモリへの転送は69.0msで、逆方向の転送と比べてかなり遅く、MIC→メインメモリ→VRAMの転送には時間が掛かる。一方、GPU処理の場合は、計算に使ったVRAMから表示用のVRAMへのメモリコピーで転送できるので0.6msと非常に高速で描画できる。
最も速度の速い、GPUでの計算をCUDAでプログラムし、表示をOpenGLで記述した場合のセル数と描画速度の関係を表したのが、次の右側の図である。リアルタイム描画を行う場合、1923セル程度なら15fpsで描画でき、1283セルなら30fpsの描画ができるという結論が得られたという。
また、ここで得られた性能ではGPU+CUDA以外の実装では性能不足で、リアルタイムの可視化はできないという結論である。

|

|
|
計算結果の描画に必要な時間。MICではMICメモリ→メインメモリ→VRAMの転送が必要なので、遅くなる。GPUで計算し、描画する場合はGPUメモリ内の転送であるので高速で行える |
リアルタイム描画を行う場合の、セル数に対するフレームレートのグラフ。1923セルの場合は15fps程度。1283セルなら30fpsが可能 |
なお、青木教授は、問題にもよるが、OpenACCで書いてもCUDAの90%以上の性能が得られており、この発表の3~4倍も性能が開くというのは差が大きすぎるとコメントしていた。