GoogleのシニアフェローのJeff Dean氏が、GTC 2015においてGoogleのDeep Learningについて基調講演を行った。
Jeff Dean氏はMapReduce、BigTable、Spannerなどを開発してきたエンジニアで、最近ではGoogle TranslateやGoogle Brainなどを開発している。

|
|
GoogleのDeep Learningについて基調講演を行うJeff Dean氏 |
テキスト、画像、オーディオ、ユーザのアクティビティ、知識を関連付けるグラフなど大量のデータがあるが、それらを理解する手続き的なプログラムを作ることは困難である。そこでDeep Learningが必要となるという。
Deep Learningでは、脳に関する我々のもっているわずかな知識にヒントを得て作られた神経(ニューロン)のネットワークを使う。このネットワークは多層の構造を持っており、右側の層になるほど高次の抽象化が行われる。

|
|
脳の構造に関する(わずかな)知識からヒントを得て人工の神経ネットワークを構築。上位(右側)の層に行くほど高度の抽象化が行われる |
人工のニューロンは、ニューロンへの入力Xiに重みWiを掛けて、全入力の総和を求め、その値が負ならゼロ、正なら総和の値を出力する。なお、この図では3つの入力しかないが、実用的なニューラルネットワークでは数100、数1000の入力をもつニューロンが使われる。

|
|
人工ニューロンのモデル。X1、X2、X3の各入力に重みW1、W2、W3を掛けて総和をとり、総和が負の場合はゼロ、正の場合は総和を出力する |
このようなニューロンを相互接続してネットワークを作る。最下層が入力層で、最上層が出力層であり、中間の層は、外部から直接は見えないのでHidden Layer(隠れ層)と呼ばれる。

|
|
前記のニューロンを使って多層のネットワークを作る。最下層が入力層で、最上層が出力層であり、その間に2層の隠れ層がある構造となっている |
なお、ニューロンはどのように接続しても良いのであるが、学習のやり易さの点で、一般的には同一層内のニューロン同士には接続が無い構造が用いられる。
このニューラルネットワークに学習をさせるには入力画像と正解のペアであるトレーニングサンプルが必要である。トレーニングサンプルの入力画像をニューラルネットワークに入力し、出力を観測して、出力が正解に使づくように重みを調整するという操作を繰り返す。

|
|
学習の原理。トレーニング用サンプル(X,Y)を選ぶ。例えば、Xは前記の猫の写真で、Yは正解である「猫」。ニューラルネットワークに猫の写真を入力し、出力が「猫」に近づくように接続の重みを調整していく |
重みを調整するには、重みを変えるとどれだけ近づくかの傾き(偏微分)をそれぞれの重みWiについて計算して、その結果を使ってそれぞれの重みを調整する。

|
|
それぞれの重みを変えると、どれだけ近づくかを計算し、その傾きを使って正解に近づくように重みを変えていく |
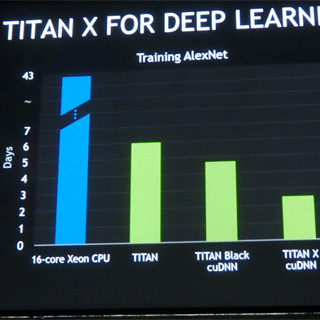
このように書くと簡単であるが、1つのニューロンに数100、数1000の重みがあり、ネットワークにはニューロンが何万個もあるので最適値を求めるのは容易ではない。最適値に近づけるためには、多数回の微調整の繰り返しが必要であり、それを多数のトレーニングサンプルに対して行うので、学習には非常に時間が掛かる。Jen-Hsun Huang CEOの基調講演では、AlexNetの学習には、16コアのXeonでは43日かかるが、Titan Xを使うと2~3日でできると述べられていた。
Googleでの実用的システムの学習ではGPUカードを使っても6週間かかり、モデルの並列性やデータの並列性を使って、これを1日でできるようにしているとのことであった。 次のグラフはトレーニングのサイクル(Epochと呼ぶ)の繰り返しでどのように誤差が減っていくかを示したものであるが、32ビットのFloatで計算した場合の黒線と8ビット、10ビット、14ビットの精度の浮動小数点数を使った場合をプロットしている。この図に見られるように、誤差の減り方は殆ど同じであり、数値に高い精度は必要ないことがわかる。このため、Titan XでサポートされたFP16などを使って演算速度を倍増し、学習時間を短縮することができる。

|
|
計算する数値の精度が、学習による誤差の減少にどの程度影響するかを示すグラフ。32ビットのFloatが一番良いが、8ビットのFL8でも大差ない |
Googleでは数十人年の工数を人工知能の開発につぎ込んでおり、何千個ものCPUやGPUを使って大量のサンプルデータを処理している。
そして、Googleは、画像認識、ビデオのカテゴリ認識、スピーチ認識、画像の説明文の作成、OCR、自然言語の理解、翻訳、オンライン広告に関して、研究論文を発表しており、AIは広い適用範囲がある。

|
|
Googleは、画像認識、ビデオのカテゴリ認識、スピーチ認識、画像の説明文の作成、OCR、自然言語の理解、翻訳、オンライン広告に関して、研究論文を発表している。AIは広い適用範囲がある |
成果の一例を示すと、次のスライドは、正解が付いていない生画像から(教師なしのUnsupervisedな学習)人間の顔を学習した結果である。左の写真が顔と判定されたスコアの高い48枚の画像で、右の図が最適化された顔で、ネットワークはこの顔に最も強く反応するようにチューニングされている。また、次の図は猫を学習した結果である。
ただし、人間の顔の左端の列の3段目や、猫の左端の列の5段目、3列目の3段目、右から3列目の最下端の段の写真は間違っているようである。

|

|
|
教師なし学習で学習した人間の顔のサンプル |
教師なし学習で学習した猫のサンプル。右は最も強く反応するサンプル |
また、昔懐かしいスペースインベーダなどの「Atari 2600」のゲームを、画面のピクセルデータとスコアだけを与え、ゲームのルールなどは教えないでプレイさせた結果、最初は、すぐにインベーダにやられてしまっていたが、経験を重ねると、トーチカの陰に隠れて敵弾をやり過ごしてからインベーダを攻撃するテクニックを発見してスコアをあげたという。また、上部にあるブロックの壁を崩すBreakoutでは、300ゲーム程度プレイすると、端に穴を開けて天井とブロックの間でパドルを反射させてポイントを稼ぐテクニックを発見したという。
このように、ディープニューラルネットワークは広範囲の用途に使え、知的なシステムを作っていく上で重要なツールである。学習時間の問題も、Googleでは、いろいろな並列処理を使って高速化することができ、大規模なネットワークを短い時間で学習させることができるようになっているという。

|
|
結論として、ディープニューラルネットワークは、広範囲の用途に使える。色々な並列化により、大規模なネットワークを短時間で学習させることができる。知性を持ったシステムを作るのに重要なツールである |