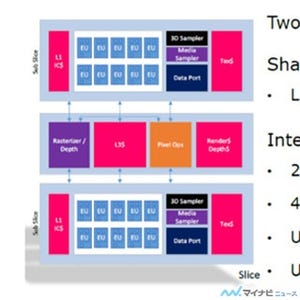
Iris GPUのメモリ階層
Iris GPUのメモリ階層は図10のようになっている。サブスライスの共通部にあるキャッシュはL3キャッシュとなっているが、L1とL2はテクスチャキャッシュで、一般のデータとしてはL3キャッシュが1次キャッシュとなっており、容量はスライスあたり256KBである。また、このL3キャッシュの箱の中にSLM(Shared Local Memory)が書かれているように、ローカルメモリへのアクセスはL3キャッシュのインタフェース部を経由して行われる。
そして、L3キャッシュは、CPUと共通のLLCを通してDRAMのメインメモリに接続されている。

|
|
図10 Iris GPUのメモリ階層 |
図10ではLLCの上に破線でEDRAMと書かれたブロックがある。これはChrystalwellの名称で開発されてきた別チップのeDRAMのキャッシュチップで、容量は128MBである。ここで、目新しいのはEDRAMの下にnon-inclusive victim cacheと書かれている点である。つまり、このeDRAMはLLCを追い出されたキャッシュラインを格納するビクティムキャッシュとなっている。
L3キャッシュのラインサイズは64バイトで、これはCPU側のキャッシュとも一致している。そして、L3$はサブスライスごとに64バイト/サイクルのアクセスができるので、Iris GPU全体の総バンド幅は332.8GB/sとなる。しかし、実質の1次データキャッシュのレベルで332.8/832=0.4B/Flopのメモリバンド幅であり、ピーク演算性能を出すには、かなりメモリアクセスを抑えたプログラムとすることが必要と思われる。

|
|
図11 L3キャッシュバンド幅は332.8GB/s |
L3キャッシュを経由してグローバルメモリをアクセスする場合は、サブスライスからのメモリアクセスのアドレスの組み合わせでキャッシュのアクセス回数が変わる。図12に見られるように、すべてのアクセスが1つのキャッシュラインに入る場合は、1回のアクセスで済み、最大のバンド幅が得られる。これは2番目の例のように、アクセスの順序がキャッシュライン内で逆順になっていてもよい。
しかし、3番目の例のように、連続アドレスのアクセスでも、最初のアドレスが64バイト境界と一致していないと2回のアクセスが必要となり、半分のバンド幅しか利用できない。これは、1つ置きにアクセスする4番目の例でも同じである。そして、一番下の例では1つのキャッシュラインで1つのアクセスしかカバーできず、16回のアクセスが必要になってしまう。

|
|
図12 アクセスするアドレスの組み合わせでキャッシュラインを読む回数が変わる |
図13に見られるように、ローカルメモリのアクセスもL3キャッシュを通してアクセスすることになり、最大バンド幅はL3キャッシュと同じである。しかし、ローカルメモリは16バンクに分割されており、同じバンクに複数のアクセスが重ならなければ、すべてのアクセスを同時に処理することができるようになっており、フルバンド幅になるケースが増えているという違いがある。

|
|
図13 ローカルメモリのアクセスは、フルバンド幅が使えるケースが増えている |
ローカルメモリの場合は、図14の一番上の例は、連続アドレスであるが先頭アドレスがキャッシュライン境界に一致していない例で、L3キャッシュの場合は2回のアクセスが必要であったが、ローカルメモリの場合は、アクセスするバンクが重なっていないので1回のアクセスで処理でき、フルバンド幅でアクセスできる。
2番目の例は2つのアクセスが同じところにいく例で、この例はL3キャッシュでも1回のアクセスで済むのではないかと思われるが、当然、ローカルメモリでも1回のアクセスで済む。
3番目の例は同じバンクに2つのアクセスが重なるので、2回のアクセスを必要とし、4番目の例は1つのバンクに16のアクセスが重なる最悪の場合である。
そして、最後のケースは4番目と似ているが16跳びではなく、17跳びになっており、すべてのアクセスで異なるバンクをアクセスしているので、ローカルメモリの場合は1回のアクセスで処理でき、フルバンド幅が得られる。

|
|
図14 ローカルメモリのアクセスの例 |
このように、Iris GraphicsはSIMTで多数のスレッド(Work Item)を並列に実行するGPUであることが明らかになり、その命令実行の振る舞いもNVIDIAやAMDのGPUと似ていることが分かった。これは意外ではないが、逆に言うと、NVIDIAやAMDのGPU用にチューニングしたOpenCLコードがIris Graphicsでもマイナーな変更で動くことを意味しており、ユーザにとって朗報である。
また、Iris Pro 5200は単精度浮動小数点演算では832.8GFlopsという、CPUチップ内蔵のGPUとしては、高い演算性能を持っており、AMDのAPUの強力なライバルになると思われる。そして、Xeon Phiの市場も一部侵略していくのではないかと思われる。