米Tabula Inc.は3月26日(米国時間)、同社の次世代3PLD製品「ABAX2 P1」を搭載するリファレンス・デザイン・スイートを発表したが、これに先立ち国内でこのABAX2 P1に関する記者説明会が行われたので、その内容とあわせてご紹介したい(Photo01)。

|
|
Photo01:説明を行ったのは昨年と同じくVice President of MarketingのAlain Bismuth氏。氏は4月にもまたSpacetime Forum(後述)のために来日というか、全世界を廻る事になるらしい |
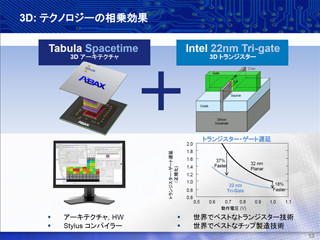
そもそもTabulaという会社をご存知無い、という読者は昨年のこちらの記事を参照していただくのが早いのだが、要するにIntelの22nmプロセスを使ってFPGAを製造する2社のうちの1社(もう1社はAchronix Semiconductor)である。そのAcronixの方は? というと、2013年2月20日に22nmプロセスを使って製造したSpeedster 22iの出荷を開始したとのリリース )をだしており、またAlteraがIntelの14nmプロセスを使って量産を行うアナウンスをしていることもあって、残るTabulaの動向が注目されていた。
動作周波数は2GHz、Fold数は12
ちょっと氏の説明とは順番が異なるが、まずは肝心のABAX2 P1についてご紹介する。初代のABAXはTSMCの40nm Gプロセスで製造され、1.6GHz駆動で最大8Foldという構成であるが、ABAX2では動作速度が2GHzに向上、Fold数は12になっている(Photo02)。ちなみにプレゼンテーションには出てこないが、LUT数(TabLUT)は57万、Logic-carry Brockは8万、RAMは最大23.6MBになっている。この23.6MBのRAMは、最大24ポートのShared Memoryとしても機能し、全体としてのスループットは13.8TB/secにも及ぶ(Photo03)。

|

|
|
Photo02:Tabulaの場合、3次元とは「X・Y・時間」の3次元の意味。1cycleごとにLUTの内容を書き換える事が可能で、これを最大12構成持てる。なので2GHz駆動だと現実問題としては1Fold構成になるが、166MHz駆動であれば内部を12Fold構成にすることで、利用できるLUTやMAC、Memoryなどが全部12倍になるので、利用できる回路規模が膨大になるという仕組み |
Photo03:RAMは144KB/36bit WidthのLRAMと18KB/可変幅のMRAMの2種類のブロックが用意され、LRAMはブロックあたり12ポート、MRAMはブロックあたり24ポートのマルチポートメモリとして機能する。ちなみにSpaceTimeでLUTの切替の際に必要とされるFIFOにあたるものとしてはTransparelent Latchを「配線1本につき1つずつ」配しており、なので結果としてSpaceTimeそのものがユーザーRAMを圧迫する事はない |
ただTabulaはPrimary TargetをCommunication Market、それもData CenterあるいはBackboneといった分野に絞っており、従ってABAX2の能力に関しては、LUT数とか動作周波数よりも、このPrimary Targetでどれだけの性能が実現できるかという観点での説明が行われた。ということで、以下ちょっと紹介したい。
これも昨年の話になるが、XilinxがVirtex-7で100Gbpsのソリューションを提供できるという話をちょっとご紹介したが、Tabulaがターゲットとしているのがまさにこのエリアである(Photo04)。以下具体的な事例として紹介されたのはこの3つ(Photo05)。こうした高速な機器を構築する場合、従来のソリューションだと幾つかの問題があった(Photo06,07)。これに対し、ABAX2では100G EthernetのEMACとDDR3コントローラ×4をHard IPの形で実装することで最初の2つの問題に対応し、残る2つについては同社のSpacetimeによって解決できる、と説明している。

|

|
|
Photo04:Tabulaは単にCore Componentだけでなく、100G向けのSolutionを提供する、という点を強く前面に出している。ちなみにComponentの中のStylusについては後述 |
Photo05:具体的な構成は後述 |

|

|
|
Photo06:これは一般的な100Gのルータを構築した場合の典型的な構成。どちらかというとフロントエンド向けで、バックエンドに向けてはInterlakenで繋がる形になる |
Photo07:問題点は4つ。まず100Gの入力をどうサポートするか、ついで外部メモリの帯域をどう確保するか。また100Gを通すためには内部で広帯域のバスが必要になるし、もちろん内部メモリの帯域も高速でないと間に合わない |

|
|
Photo08:最初の2つの問題の解決は別にTabulaのみという訳ではないが、残りの2つが大きな特徴になると説明した |
面白いのは、この解決策として今回Tabulaが提供するのはFPGA単体ではなく、Bridge/Switch/Search Engine向けの各Reference Designという形になる事だ(Photo09)。まずBridgeの場合、100Gbps×1と10Gbps×12のBridgeを構成する場合、ご覧の通りABAX2が1個に外部のPHYを取り付けるだけで完成する。必要なIPも、主要なものは全てTabulaから提供されるので極めて迅速に構成できる(Photo10)。

|

|
|
Photo09:Communication、それもWired Backbone向けのキットのみ、というあたりが同社の割り切り方の面白い部分だと思う |
Photo10:ちなみに内部のMACは100GbE×4 or 40GbE×16 or 10GbE×64となっているので、もっと大規模なBridgeの構成も可能だが、その場合はRouting Tableが内部RAMで収まるか微妙なところで、外部メモリも必要だろう |
これを構成する場合のABAX2側の構成はこんな感じ。クロック周波数の471MHz/314MHzは「この処理を行わせるために必要となるUser Frequency」(Bismuth氏)という話であり、実際にどの程度の速度で動作するのかはStylusが決定する事になる。だからとりあえず471MHz以上ということでUser Frequency(ユーザーから見たABAX2の動作周波数)を500MHzに設定する場合、内部的には2GHz駆動だから4 Fold構成が可能になるという訳だ。Photo11における「ABAX2P1の使用率」の数字は、当然これを加味したものである。

|
|
Photo11:利用するLUT率はこの時点でもまだ21%、LRAMの利用率も18%に過ぎないので、もう少し大規模なBridgeでも無理なく構成出来そうである |
もう少し負荷が高いものとしては、100GbE×4ポートのCrossbar Switchなどがある(Photo12)。こちらの場合、Crossbarを真面目に実装すると猛烈な配線数になるのはPhoto12を見れば判るわけだが、ABAX2の場合、配線は(Userから見れば)256bit幅となるものの、実際には4Foldで実行できるので実質64bit幅で接続することになる。これにより配線の爆発を防ぐ事ができるという話で、Port-to-PortのLatencyも12nsと低めに抑えられる事が示された。またAES-128のEncryptionを実施する場合、従来のFPGAよりもずっと少ないリソースで実現できるといった数字も示された(Photo13)。

|

|
|
Photo12:従来型のFPGAの場合、どうやっても1チップでは収まらないので複数チップに分割するが、そうなるとさらに配線数が増え、レイテンシも増えるために「現実的ではない」と説明される。まぁやり方次第ではあるのだろうが |
Photo13:AESの場合、ABAX2だとLCB(Logic-Carry Block)のみで処理できる。LCBは2つの8bit値の加算/比較をキャリー付きで行える。複数のLCBを組み合わせると減算や乗算も可能 |
こうしたABAX2へのインプリメントを行うのは、同社が提供するStylusというコンパイラである(Photo14)。このコンパイラは他のFPGA向けコンパイラと同様にVerilog/VHDLを入力すると合成/配置/配線を行い、最終的なビットストリームを生成してくれるものだが、単にそれだけでなく高度な最適化も搭載されているとする。例えばInterlaken用のCRC24の回路を設計する際に、一切パイプライン化や最適化などをVerilogレベルで施さないままStylusで合成を行っても、2GHz駆動で120Gbpsのスループットを実現したことが説明された(Photo15)。同様にPacket ParserをABAX2とVirtex-7でインプリメントした場合、必要なリソースをずっと減らせる事も紹介された(Photo16)

|

|

|
|
Photo14:Spacetime technologyの場合、FoldをいくつにしてUser Frequencyをどの程度にするかのトレードオフが利用効率を上げるためのポイントになるが、こうした処理はStylusが自動で行ってくれるのでユーザーがこれを意識する必要は無い、との事 |
Photo15:64bitだと120Gbpsだが、128/256bit CRCではスループットが400Gbpsに達したとの事 |
Photo16:後で「Virtex-7のどの製品との比較か」という質問も出たが、正確には覚えていないとの事。ただ通常同社は、一番適切と思われる製品との比較を示す、と説明された |
もう少し面白いのが、顧客によるPacket Classification Engineの実装で、Virtex-7だと205MHzだったのもをABAX2に載せかえるだけで500MHzを達成したが(Photo17)、さらに顧客がSpacetime向けに最適化を施したところ703MHz駆動、さらにStylusでTiming Reportを出力させたところ、ボトルネックがある場所に加えて、その解決策としてLatencyを加える事を示された。これを行ったところ、最終的にFmax=2GHzを達成できたとする(Photo18)。単にStylusは合成や配置配線を行うだけでなく、高度な最適化が可能であるという事であった。

|

|
|
Photo17:ここで言うFmaxはUser FrequencyではなくDevice Frequencyである |
Photo18:ボトルネックのハイライト化も、レイテンシの追加も「ワンコマンド」である事を氏は強調した |
すでに同社はさまざまな種類のSoft IPを提供しており(Photo19,20)、これを組み合わせる事で40G~100Gクラスの高性能なネットワーク機器を迅速に構築できるとしている。

|

|
|
Photo19:余談だがABAX2P1の場合、最大2.133GHzで駆動できるParallel I/Oを576本利用でき、これで利用できるI/Fの中にはDDR2/3/4といったものまで含まれる。なので標準で搭載される4chのDDR3のHard IPで不足の場合、さらにSoft IPでDDR3コントローラをインプリメントして帯域を増やす事が可能である |
Photo20:今はWired Networkに特化していることもあり、用意されているデザインもそうしたものばかりである |
また、こうした事を開発者に知ってもらうため、2013年4月より全世界でSpacetime Forumを実施することも明らかにした(Photo21)。

|
|
Photo21:日本でのSpacetime Forumの登録ページはこちら。ちなみに後で「なんでヨーロッパはロンドンとストックホルムだけなのか?」と氏に尋ねたところ、苦笑いしていた。要するに欧州ではむしろWireless向けが現在盛んであり、同社のターゲットであるDatacenter/Backhaul向けのメーカーがあまりないということなのだろう |
最後にTabula Japanの荒井雅氏(Photo22)がまとめを行ったが、氏の話の中で興味深いのはStylusの最適化に関する部分だった。Stylusは3つの革新の特徴があるとしている。まず1つ目がTiming Closureに関する部分で、Sequential Timingと呼ばれる技法で最適化を図っているという事。2つ目は配置に関してで、配線認知配置(配置を行う際に、配線がどうなっているかを理解しながら配置する)という技法で、設計の上流工程で配置の最適化を図る事で手戻りを減らしている事。3つ目は速度とロジック密度の両立を図れる(Fold数を加減することで両立が実現できる)という話だった。

|
|
Photo22:Tabula Japanのシニア・マーケティング・ディレクタである荒井雅氏 |