Rustはさまざまな用途で利用されていますが、最近は、AI/機械学習分野でも利用されるようになってきました。そこで、今回は簡単な機械学習のアルゴリズムであるk近傍法を使ってアヤメの分類に挑戦してみましょう。
-

「アヤメの分類」データを使ってk近傍法で分類してみよう

アヤメの分類に挑戦しよう
今回は「アヤメの分類」に挑戦します。これは、機械学習の中でも、教師あり学習の分類問題に分類されるものです。と言っても、機械学習にあまり詳しくない人からすると、「教師あり学習」とか「分類問題」とは何だろうと思うことでしょう。しかし、それほど難しいものではありません。
「アヤメの分類」データセットは、機械学習のベンチマークに使われる有名なものです。これは、名前の通り、アヤメの品種を分類したデータセットです。
そもそも、アヤメには多くの品種がありますが、品種を見分けるとき、花弁の幅や長さ、がく片(花の外側にある大きが異なるもの)によって分類できるのです。それで、花弁とがく片の大きさ(幅と長さ)だけを与えて、品種を特定するというのが、この分類問題です。
このデータセットには、アヤメの品種として「Iris-setosa」「Iris-versicolor」「Iris-virginica」という3種のアヤメの品種の150個のデータが収録されています。
-

「アヤメの分類」データについて

そして、データセットと言っても、ただのCSVファイルであり、次のようなデータとなっています。
がく片の長さ, がく片の幅, 花弁の長さ, 花弁の幅, アヤメの品種
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
〜省略〜
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
〜省略〜
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
最初に上記のアヤメについてのデータを学習させます。そして、最終的に4つの値(がく片の長さ, がく片の幅, 花弁の長さ, 花弁の幅)だけを入力して、アヤメの品種を当たることができるかどうかというのが「分類問題」です。
このデータセットのオリジナルデータは、クリエイティブコモンズ(CC BY 4.0)で、こちらから入手できるのですが、今回のプログラムでテストしやすいように加工して、こちらからダウンロードできるようにしました。右上の[Download ZIP]からダウンロードしてください。解凍すると「iris.csv」があります。このファイルを使いましょう。
k近傍法について
次に、今回Rustで実装するアルゴリズムの「k近傍法」について紹介します。「k近傍法(k-nearest neighbor algorithm, k-NN)」とは、機械学習アルゴリズムの一つです。教師あり学習の分類や回帰などのパターン認識で使われます。アルゴリズムが簡単なことから、さまざまな用途で利用されています。
k近傍法のアルゴリズムは、次のような手順で分類を行います。
- (1) ラベル付きの学習データを全て座標に配置
- (2) 入力データAと全学習データの距離を調べる
- (3) 学習データをAと距離が近い順に並び替える
- (4) 距離の近い上位k個を選ぶ
- (5) 選んだk個のデータにどのラベルがついているか調べる
- (6) 最も多いラベルを入力データAのラベルとする
以下の図は、上記の手順を図にしたものです。この図の中では、全ての学習データの中から点Aまで距離が近いものを3つ選びます。すると、●が2つ、▲が1つなので、入力データAは、●に分類されるということが分かります。
-

k近傍法で入力データAが●か▲のどちらに分類されるのか調べたところ

このように、k近傍法はとてもシンプルに分類を行うことができます。
Rustのプログラムを作ってみよう
それでは、k近傍法のプログラムをRustで作ってみましょう。そして、アヤメの分類問題を解いてみましょう。
ターミナル(WindowsならPowerShell、macOSならターミナル.app)を起動して、次のコマンドを実行してプロジェクトを作成しましょう。
# プロジェクトディレクトリを作成
mkdir program
cd program
# プロジェクトを初期化
cargo init
# randクレートを追加
cargo add rand
すると、次のようなプロジェクトが作成されます。
.
├── Cargo.toml
├── iris.csv
└── src
└── main.rs
そして、src/main.rsを編集します。プログラムは70行ほどあり長いので、少しずつ確認しましょう。なお、プログラム全体は、こちらにアップしてあります。
プログラムの先頭から確認していきましょう。このプログラムでは、データとラベルを持つ構造体KnnItemを定義して利用します。下記の(*1)でKnnItemを定義します。
use rand::seq::SliceRandom;
// データとラベルを持つ構造体を定義 --- (*1)
#[derive(Debug, Clone)]
struct KnnItem {
data: Vec<f64>, // データ
label: String, // ラベル
}
続いて、以下の(*2)で、k近傍法でデータを予測する関数knn_predictを定義しましょう。
// k近傍法でデータを予測する --- (*2)
fn knn_predict(items: &[KnnItem], test: &[f64], k: usize) -> String {
// testとitemsの距離を求める --- (*3)
let mut distances = items.iter().enumerate().map(|(i, item)| {
(i, calc_distance(&item.data, test))
}).collect::<Vec<_>>();
// 距離が近い順にソート --- (*4)
distances.sort_by(|a, b| a.1.partial_cmp(&b.1).unwrap());
// 最も近いk個のラベルを取得 --- (*5)
let mut votes = std::collections::HashMap::new();
distances.iter().take(k).for_each(|(i, _distance)| {
let label = &items[*i].label;
// println!(" - {}: distance={}", label, distance);
*votes.entry(label).or_insert(0) += 1;
});
// 最も多いラベルを返す --- (*6)
let label = votes.into_iter().max_by_key(|&(_, count)| count).unwrap().0;
label.to_string()
}
上記のプログラムを少しずつ見てみましょう。(*3)では、全学習データitemsと、分類対象のデータtestとの距離を求めます。mapメソッドを使って、Vec型データに対して一気に距離を計算します。
なお、距離の計算には、以下の(*7)のユークリッド距離を利用していますが、これは下記のようなプログラムで計算します。
// ユークリッド距離を求める --- (*7)
fn calc_distance(p1: &[f64], p2: &[f64]) -> f64 {
let mut distance = 0.0;
for (i, d) in p1.iter().enumerate() {
distance += (d - p2[i]).powi(2);
}
distance.sqrt()
}
ちなみに、ユークリッド距離を計算するには、下記のような公式を使います。配列xと配列yの距離を求めるには、各要素の差を2乗した合計の平方根を計算します。
d(x, y) = sqrt( (x1 – y1)^2 + (x2 – y2)^2 + … )
それから、以下の(*8)では、複数データを一度に予測するように、上記knn_predictを連続で実行する関数knn_predict_allも定義します。
// 複数データを一度に予測 --- (*8)
fn knn_predict_all(items: &[KnnItem], tests: &[Vec<f64>], k: usize) -> Vec<String> {
tests.iter().map(|test| knn_predict(items, test, k)).collect()
}
そして、ここまでに定義した関数を使うmain関数を見ていきましょう。まずは、アヤメの分類データ(iris.csv)を読み込む部分を確認しましょう。
fn main() {
// アヤメの分類データのCSVを読み込む --- (*9)
let text = std::fs::read_to_string("iris.csv").unwrap();
// CSVを行に分割し、各行をカンマで分割して、KnnItemに変換 --- (*10)
let mut items: Vec<KnnItem> = vec![];
for (i, line) in text.lines().enumerate() {
if i == 0 { continue; } // ヘッダをスキップ
if line.trim().is_empty() { continue; } // 空行ならスキップ
// カンマで分割してVec<f64>に変換 --- (*11)
let parts: Vec<&str> = line.split(',').collect();
let (cols, label) = parts.split_at(4); // 4:1に分ける
let cols: Vec<f64> = cols.into_iter().map(|s| s.trim().parse::<f64>().unwrap()).collect();
items.push(KnnItem { data: cols, label: label[0].trim().to_string() });
}
〜この後で紹介〜
}
上記の(*9)では、アヤメの分類データCSVファイルを読み込みます。そして、(*10)以降の部分でCSVを一行ずつ読んで、Vec
(*11)では、カンマ(,)でデータを区切って、データとラベルを持つKnnItem型のオブジェクトを作成し、itemsに追加します。なお、ここでは、最初にカンマで区切ったデータをVec<&str>型の変数partsに区切っておいた後で、冒頭の4つのデータをVec
続いて、main関数の続く処理を見てみましょう。
// データを学習用とテスト用に分ける --- (*12)
items.shuffle(&mut rand::thread_rng());
let (train, test) = items.split_at(100); // 100:50に分ける
let test_x = test.iter().map(|item| item.data.clone()).collect::<Vec<_>>();
// テスト用データを使って正解率を求める --- (*13)
let k = 7;
let test_y = knn_predict_all(&train, &test_x, k);
// 正解率を調べる
let ok = test.iter().zip(test_y.iter()).filter(|(item, label)| item.label == **label).count();
let accuracy = ok as f64 / test.len() as f64;
println!("正解率: {}/{} = {}", ok, test.len(), accuracy);
// 適当なデータを与えてアヤメを予測する --- (*14)
let test_data = vec![5.9, 2.5, 4.4, 1.2];
let label = knn_predict(&items, &test_data, k);
println!("{:?} => {}", test_data, label);
上記の(*12)では、データを学習用とテスト用に分割します。アヤメの分類データをシャッフルした後、学習用の100件と、テスト用の50件に分割します。データを分割する目的ですが、ここでは、未知のデータをどれくらいの精度で分類できるかを確認するためです。
(*13)では、テスト用のデータを使って、正解率を求めます。テストデータのデータ部分だけを取り出して分類予測してみます。そして、予測した内容が実際のデータとどれくらい合致しているのかを調べます。50件中50件正解できれば、完璧な分類器と言えます。
そして、最後の(*14)では、適当なそれっぽいデータを与えて、どのアヤメの品種に分類できるかを試しています。
プログラムを実行しよう


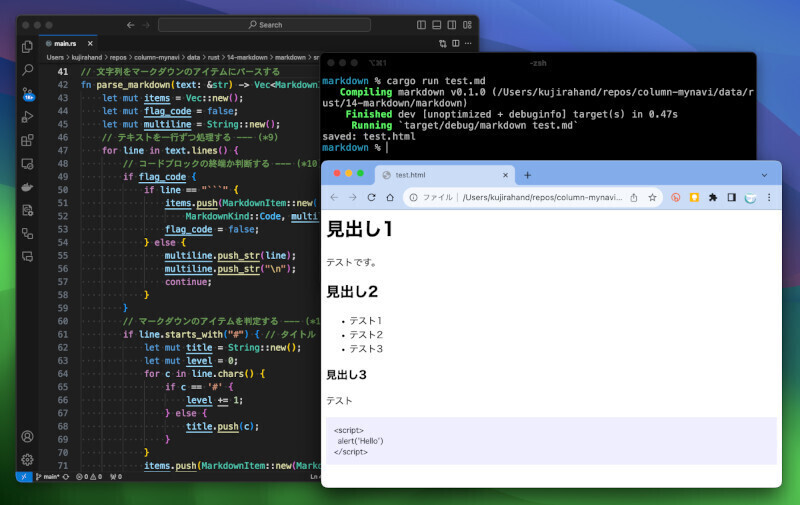
それでは、実際にプログラムを実行してみましょう。programディレクトリに、こちらからダウンロードしたiris.csvを配置したら、ターミナルで下記のコマンドを実行します。
cargo run
すると、下記のように実行結果が表示されることでしょう。データをシャッフルしているため、実行するごとに、微妙に異なる値が表示されますが、だいたい正解率が0.98(つまり、98%)と表示されます。CSVの読み込み処理も入れて70行であることを考えると、かなり良い結果と言えるのではないでしょうか。
-

コマンドラインから実行したところ

まとめ
以上、今回は、k近傍法を使って、アヤメの分類を行うプログラムを作ってみました。k近傍法は手軽に実装できるので、簡単な分類問題を解くことができます。「アヤメの分類」は、機械学習の基礎の基礎ではありますが、機械学習のライブラリなどを使わず、ゼロから自分で実装してみると、より深く仕組みを理解できるのでオススメです。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。直近では、「実践力をアップする Pythonによるアルゴリズムの教科書(マイナビ出版)」「シゴトがはかどる Python自動処理の教科書(マイナビ出版)」「すぐに使える!業務で実践できる! PythonによるAI・機械学習・深層学習アプリのつくり方 TensorFlow2対応(ソシム)」「マンガでざっくり学ぶPython(マイナビ出版)」など。