関数UNIQUEを使って「重複データを除外したリスト」を作成するときに、「複数の列」を対象にしたい場合もあるだろう。関数UNIQUEは複数列のデータ指定にも対応しているが、思い通りの結果を得るには「どのように重複データが除外されるのか?」について学んでおく必要がある。関数UNIQUEの注意点とあわせて詳しく説明していこう。
複数列を対象に関数UNIQUEを使用した場合は?
今回も関数UNIQUEの使い方を紹介していこう。関数UNIQUEを使って重複データを除外するときに「複数の列」を対象にしたい場合もあるだろう。この場合、「どのような仕組みで重複データが除外されるか?」について詳しく学んでおく必要がある。
-
複数列を対象にした関数UNIQUEの応用的な使い方

今回は、連絡先をまとめた表から「重複データを除外する方法」を例に、関数UNIQUEの挙動について説明していこう。
以下の図は、各社員が個別に管理している名刺情報を集約するために、それぞれが所有する情報を表に入力してもらったものだ。状況を把握しやすくするために、データ数は12件に抑えてあるが、実際には数百件、数千件という規模のデータが存在すると考えて頂きたい。
-
各自が名刺データを登録した表

この表をよく見ると、情報が重複しているデータがあることに気付くと思う。「麒麟設計の小久保さん」は同じ連絡先データが2件も登録されているし、「イヌワシ運送の藤本さん」は「部署」と「TEL」が異なる形で2件のデータが登録されている。
-
情報が重複しているデータ

これらの重複データを関数UNIQUEで除外してみよう。まずは「社名」~「メールアドレス」のセル範囲を関数UNIQUEに指定した例を紹介する。
-
関数UNIQUEの入力

-
関数UNIQUEにより取得されたデータ

このままでは状況を把握しづらいと思うので、セルに色を付けた図を使って解説していこう。
-
除外されたデータの確認

連絡先のデータがすべて一致している「麒麟設計の小久保さん」は、問題なく重複データが除外されている。一方、「イヌワシ運送の藤本さん」はデータが2つとも残っており、重複は解消されていない。
これは関数UNIQUEの仕様に従った結果といえる。セル範囲に「複数の列」を指定した場合は、「すべての列でデータが一致する場合」のみ重複データとみなされる。先ほどの図において、「イヌワシ運送の藤本さん」は「部署」と「TEL」のデータが異なるため、重複データとはみなされない。よって、出力リストからも除外さない、という結果になる。
では、どのようにセル範囲を指定すれば上手くいくのだろうか? 解答例を一つ紹介しておこう。たとえば、以下の図のように「社名」と「氏名」のセル範囲だけを対象にして関数UNIQUEを実行すると、重複データを確実に除外することが可能となる。
-
関数UNIQUEの入力

-
関数UNIQUEにより取得されたデータ

念のため、セルに色を付けた図も紹介しておこう。データが重複していた「麒麟設計の小久保さん」と「イヌワシ運送の藤本さん」が、それぞれ1件のデータとして取得されているのを確認できるだろう。
-
除外されたデータの確認

これで重複データを除外できたことになるが、「社名」と「氏名」しかない状態では連絡先としての役割を果たさなくなってしまう。よって、他のデータを補完してあげる必要がある。
重複を除外して最新データだけを残すには?
ということで、連絡先から重複データを除外するときの具体的な操作手順を紹介していこう。まずは「登録日」の新しい順(降順)にデータを並べ替える。
-
データを「登録日」の降順に並べ替え

続いて、先ほど示したように「社名」と「氏名」のセル範囲だけを対象にして関数UNIQUEを実行する。すると、重複データを除外した形で「社名」と「氏名」のリストを作成することができる。
-
関数UNIQUEの入力

-
関数UNIQUEにより取得された「社名」と「氏名」

なお、重複データを除外する際に「氏名」だけを対象にする方法も考えられるが、万が一、同姓同名の人物がいた場合、どちらか一方のデータが抜け落ちてしまうことになる。よって、上記のように「社名」と「氏名」の両方を対象にしたほうが確実性は高くなる。なお、方法では、同じ会社に同姓同名の方がいるケースには対応できない。ただし、そういった状況はかなり稀なケースと考えられるだろう。
話を元に戻そう。続いて、これらのデータをもとに「部署」、「TEL」、「メールアドレス」のデータを補完していく。この作業には関数XLOOKUPが活用できる。
このとき、検索値(キーワード)が「社名」と「氏名」の2つになることに注意しなければならない。このような場合は、文字列を結合する「&」を使って引数を指定してあげると複数のキーワードでデータを検索できる。
-
関数XLOOKUPで他のデータを取得

このテクニックの使い方は第60回の連載:XLOOKUPやVLOOKUPで「複数の検索値」を指定する方法で詳しく解説しているので、よく分からない方はあわせて参照しておくとよいだろう。また、オートフィルで関数をコピーできるように「検索範囲」と「取得範囲」は絶対参照で指定している。
「Enter」キーを押して関数XLOOKUPを実行すると、「部署」、「TEL」、「メールアドレス」のデータが正しく取得されていることを確認できる。
-
関数XLOOKUPにより取得されたデータ

あとは、この関数XLOOKUPをオートフィルでコピーするだけ。これで全データの「部署」、「TEL」、「メールアドレス」を補完することが可能となる。
-
関数XLOOKUPをオートフィルでコピー

状況が分かりやすいように、セルに色を付けた形で結果を示しておこう。データが重複していた「麒麟設計の小久保さん」と「イヌワシ運送の藤本さん」が、それぞれ1件のデータとして取得されているのを確認できるだろう。
-
重複したデータを除外した表

なお、最初に「登録日」の新しい順にデータを並べ替えたが、この作業は関数XLOOKUPの仕様を考慮したものとなる。
「麒麟設計の小久保さん」はすべての連絡先データが一致しているため、元データの2件のうち、どちらのデータが取得されても問題は生じない。
問題となるのは「イヌワシ運送の藤本さん」だ。こちらは「部署」と「TEL」のデータが一致していない。これらのうち「どちらが正しいデータか?」の判断をExcelに任せることは不可能だ。この問題は人間が判断しなければならない。
そこで、今回の例では「登録日」が新しい方を“正しいデータ”と判断することにした。関数XLOOKUPはデータを上から検索していき、最初に見つかったデータを取得する仕様になっている。よって、あらかじめ「登録日」の新しい順にデータを並べ替えておくと、「登録日が最も新しいデータ」を取得できるようになる。
もちろん、この方法で絶対に“正しいデータ”を取得できるとは限らない。状況によっては、登録日の古いデータのほうが“正しいデータ”である可能性もあるだろう。ただし、この表だけでそれを判断することは不可能だ。
また、元データに「登録日」などの日付情報が含まれていなかった場合は、データを新しい順に並べ替えることすら不可能になってしまう。このため、より悩ましい問題が発生してしまう。
このように、重複データの除外は「かなり奥の深い問題」になるケースが少なくない。すべてのデータが完全に一致していれば重複データを問題なく削除できるが、「部分的に異なるデータをどう処理するか?」は対処に悩む問題といえる。
「実際にどう処理すべきか?」はケース by ケースになるため一概には示せないが、最低限の知識として「関数UNIQUEがどのような仕組みで重複データと判断するか?」は知っておく必要がある。
関数UNIQUEを使用するときの注意点
そのほか、関数UNIQUEを使用する際は以下の点にも注意しておく必要がある。
◆関数UNIQUEの注意点
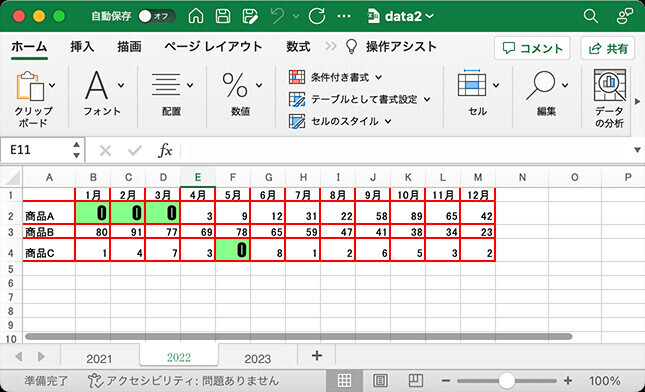
・空白セルは数値の0(ゼロ)としてデータが取得される
・「大文字/小文字」や「半角/全角」の違いは同じデータとして扱われる
・日付や時刻は「シリアル値」としてデータが取得される
簡単な例を紹介しておこう。以下の図は、セル範囲に「B2:F13」を指定して関数UNIQUEを実行した例だ。空白セルは「数値の0」として取得されることを確認できるだろう。
-
空白セルを取得した場合

続いては「大文字/小文字」や「半角/全角」が混在している場合の例だ。この場合は、元データの文字が異なっていても“重複データ”と判断される。よって、重複データを問題なく除外することが可能である。
-
全角/半角、大文字/小文字が異なるデータ

最後は、元データに「日時のデータ」が含まれていた場合の例だ。この場合は、日時を「シリアル値」に変換した数値が取得される。
-
日時を取得した場合

これらの数値を日時として表示するには、該当するセルに適切な表示形式を指定してあげる必要がある。
関数UNIQUEを使用する際は、このような仕様があることも知っておくと不要な混乱を回避できる。念のため、覚えておくとよいだろう。