Knights Landingプロセサの構造
Knights Landing(KNL)は、メインラインのIAプロセサと命令互換を実現し、自分でOSをブートして走らせられる最初のXeon Phiプロセサである。そして、前世代のKNC(Knights Corner)と比較してスカラ性能もベクトル性能も大きく改善している。また、3D積層メモリを同一パッケージに搭載し高バンド幅と大容量を実現している。さらに、ファブリック(ネットワーク)インタフェースも同一パッケージに搭載している。

|
|
KNLはメインラインのIAプロセサと命令互換で、通常のOSをブートして走らせられる。また、KNCと比べて、スカラ、ベクトルの性能ともに大きく改善している |
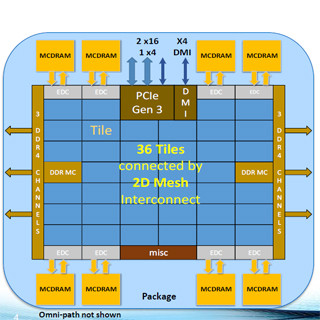
KNLは、コアと2つのVPUを2セット持ち、共用の1MBのL2キャッシュ、そしてCache/Home Agentを含むタイルとして作られている。KNLチップ全体では、この2コアのタイルを36個搭載している。次の図に見られるように、PCIeのタイルやメモリインタフェースのタイルなども含まれているので、プロセサタイルだけでは長方形の形にはならない。なお、チップには36タイルが作られているが、製品としてはいくつかのタイルを冗長として、よりタイル数の少ないバリエーションも作られている。
メモリはTSVを使って3D積層したMCDRAMというメモリを8個、同一パッケージに搭載し、16MBの容量と500GB/s程度のバンド幅を持つ。そして、I/OはPCI Express Gen3を36レーン持っている。
この構成で、DGEMMでは2TFlops、SGEMMでは4.6TFlopsの性能を持ち、メモリバンド幅を測定するStream Triadでは490GB/sをマークしている。そして、KNLプロセサの性能は、現世代のKNCのコアと比べると、スカラ性能は最大でほぼ3倍になっているという。

|
|
タイルはコアと2VPUを2セットと1MBのL2キャッシュ、Cache/Home Agentを含む。このタイルを36個とメモリやI/Oコントローラを搭載する。メモリは、同一パッケージに広帯域のMCDRAMを8個搭載する |
コアは2命令発行のOut-of-Order方式で、4つのSMTスレッドをサポートする。2つのVPUは合計で、単精度なら64演算/サイクル、倍精度なら32演算/サイクルの能力を持っている。メモリアクセスはアラインされていないロード/ストアをサポートし、飛び飛びのアクセスをサポートするGather/Scatterエンジンを持っている。

|
|
コアは2命令幅のOut-of-Orderで、4つのSMTスレッドをサポートする。2VPUは1サイクルに、単精度なら64演算、倍精度なら32演算を実行する |
KNLの命令セットは、Haswellと比べてトランザクション処理のTSX命令が無いが、それ以外の命令はすべて持っており、さらに、AVX-512系のベクトル演算処理系の命令が追加されている。

|
|
KNLは、Haswellと比べてTSX命令が無いが、それ以外の命令は互換。したがって、OSも問題なく走る。そして、KNLはAVX-512系のベクトル演算命令をサポートしている |
MCDRAMはHBMと同様に、メモリスライスを3D積層したメモリであるが、キャッシュタグ用のメモリが追加されている点が大きく異なる。そして、16GBのMCDRAMをDDRメモリのキャッシュとして使うCacheモード、MCDRAMとDDRは並列で一連のアドレスが付けられるFlatモード、そして4MB/8MBをキャッシュに使い、残りはフラットモードで使うHybridモードという使い方ができる。
Cacheモードでは、ソフトウェアはMCDRAMを意識する必要は無いが、FlatモードやHybridモードのフラットに配置されたMCDRAMを使う場合は、プログラムにこのアクセスはMCDRAMをアクセスするという指示を書いておく必要がある。

|
|
MCDRAMをDDRメモリのキャッシュとして使うCacheモード、一連のアドレススペースにMCDRAMとDDRを置くFlatモード、両者を混合したHybridモードという使い方ができる。モードはブート時に決め、運用中には変えられない |
Flatモードの場合は、MCDRAMという高バンド幅のメモリと通常のDDR4メモリが存在することになるが、DDR4メモリを使うノードとMCDRAMを使うノードの2種類のNUMAノードがあるとすると考えやすい。
Flatモードでは、通常のデータは、デフォルトではDDR4メモリに割り付けられ、MCDRAMは使われない。MCDRAMを使うにはFast Malloc関数を使うか、Intel FortranコンパイラではFASTMEM指示を付ける。

|
|
FlatモードではMCDRAMを使うノードとDDR4を使うノードのNUMA構成と考える。通常のデータはDDR4に割り付けられ、MCDRAMを使う場合は、Fast Mallocなどを使う |
KNCのコア間の接続は、Xeonと同じリングであったが、KNLは2次元メッシュ接続になった。ただし、縦横のリンクは端で折り返されたリングになっている。折り返されたといってもトーラスにはなっていない。ということで、Mesh of Ringsと書かれている。
そして、このメッシュの使い方にも3つのバリエーションがある。次の図の左はAll-to-Allという使い方で、どのタイルからどのタイルにもアクセスできるモードである。自由度は高いが、パスが長くなり性能的には不利である。中央のQuadrantモードは、全体を4つの仮想領域に分け、(2)のディレクトリと(3)のMCDRAMは同じ仮想Quadrantになるようにアロケートするモードで、パスが短くなるのと、Quadrantごとのメモリアクセスを並行して行うことができるので、メモリバンド幅も大きく取れる。
SNC-4モードは、タイル(1)とディレクトリ(2)、メモリ(3)が同一の仮想Quadrantになるように制限され、NUMAノードが4つあるように動く。パスは最も短いので、うまく使えば高い性能が得られる。

|
|
2次元メッシュの使い方は、All-to-All、Quadrant、SNC-4という3つのモードがある。モードはブート時に決め、運用中には変えられない |
KNLでは次の表に示すように、8つの大きな改善を行っている。セルフブート化は、PCIボトルネックを無くし、通常のCPUと同じにすることが目的である。そして、Xeonとのバイナリ互換はレガシーのソフトがそのまま、リコンパイルなしに動くようにするためである。
新しいOut-of-Orderコア、ベクトル密度の改善、新しいAVX-512などは性能向上のためである。MCDRAMとDDR4の併用は、高バンド幅と大容量を実現するため、メッシュの採用はコアとメモリの接続バンド幅を大きくするためである。そして、Omni-Pathのコントローラをパッケージに内蔵したのは、大規模システムへのスケーラビリティを改善し、コストの低減を実現するためである。

|
|
KNLで行われた8項目の大きな改善と、何故、改善を行ったかの説明 |