|
|
IXPUGで基調講演を行うIntelのAvinash Sodani氏 |
ISC 2016の本会議が終わった翌日は、会場を近くのMarriottホテルに移し、20余りのワークショップが開催されるワークショップデイとなる。筆者は、2015年に続いて「IXPUG(Intel Xeon Phi HPC Users Group)」のワークショップに参加した。IXPUGはその名の通り、Xeon Phiを使うHPCユーザのユーザ会で、Intelからの発表と、会員からの技術発表が行われた。
今年のIXPUGの最初の基調講演は、昨年に引き続き、KNL(Knights Landing)プロセサのチーフアーキテクトであるAvinash Sodani氏が務めた。
性能向上のトレンド
次の図は、プロセサのコア数とSPECint性能の年次推移をプロットしたグラフで、2005年ころからクロック周波数が上がらなくなり、SPECint性能の伸びが鈍化している。コア数は順調に伸びており、そのペースは、1コアの性能向上を上回っている。なお、このコア数は、Top500の496位~500位の5システムのコア数を数えている。
Top500では、500位のシステム性能の年次推移は、指標としてトラックされているが、496位~500位の5システムという図を見たのは、これが初めてである。500位の1システムだけにすると、そのシステムの作りでコア数の振れが大きいので、5システムとしたのであろう。
いずれにしても、コア数の増加がスパコンの性能向上の主因であることを示している。

|
|
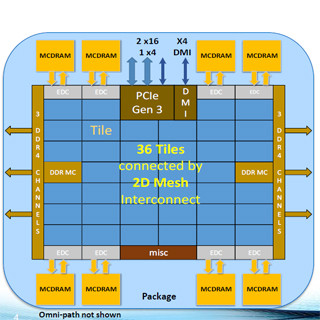
CPU計算能力の向上のトレンド (この連載のすべての図は,ISC 2016併設のIXPUGでのAvinash Sodani氏の基調講演スライドのコピーである) |
次の図は、SSEの時代から、AVX512のKNL世代までの相対的な浮動小数点演算能力の向上を示すもので、1サイクルの演算数は8倍にしかなっていないが、CPU当たりの演算能力は100倍に向上し、メニーコアのKNLでは500倍に向上している。

|
|
SSEからAVX512までの浮動小数点演算能力の向上。演算のビット幅は8倍にしかなっていないが、CPU当たりでは100倍、メニーコアのKNLでは500倍に演算能力が向上している |
ということで、並列性を追求するというのが、これから進むべき道である。たくさんのスレッドとデータレベルの並列性の組み合わせというアプローチである。シングルスレッド性能の伸びは鈍化しており、より多くのベクトル演算、CPUあたりのコア数の増加、システムのCPU数の増加で高度に並列化されたシステムになって行く。
そのため、並列化とベクトル化を行うと、アプリケーションは大きな性能向上を見込める(逆に言うと、1コアの性能はあまり伸びないので、並列化とベクトル化をしないとアプリの性能は上がらない)。

|
|
システムの並列度はドンドン上がって行く。並列化やベクトル化すれば、アプリケーションの性能は大きく向上する |
次の図は、主要なアプリケーションが何時頃開発されたかを示すグラフで、NASTRANは1960年代の終わりに作られ、(改良や機能追加は行われているが)50年近く使い続けられている。そして、このグラフでは一番新しい気象シミュレーションのWRFでも2000年の開発であり、16年使われている。このように、ソフトはハードよりずっと長い寿命を持っている。
このため、ソフトウェアを並列化対応する場合は、将来的に長持ちするプログラミングモデルを使い、コードが再利用できるような作りを考えるべきである。また、ハードは、将来のハードでも並列化したアプリが動き、そこそこの性能向上が得られるような造りにすべきである。

|
|
主要ソフトの開発時期。20年以上使われているアプリも多い。ソフト資産をどのように利用できるかは重要である |