OpenACCで使用するGPUをダイナミックに切り替えて複数GPUを使う
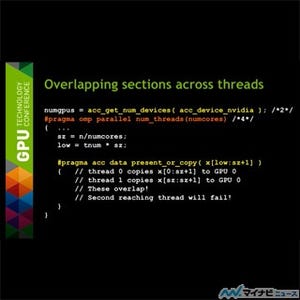
複数GPUを使う第3の方法は、1つのスレッドで使用するGPUをacc_set_device_num関数で切り替えて使用するという方法である。これにasnyc節を組み合わせると、複数のGPUを並列に動作させることができる。しかし、GPUごとにメモリ空間は独立であり、データをシェアする場合は明示的に転送を行う必要がある。

|
|
図6 使用するGPUを切り替えて、単一スレッドで複数GPUを使う |
この場合のコードは図7のようになる。図7の例では、forループでacc_set_device_num関数を呼んで使用するGPUを切り替え、データのコピーを行うupdateディレクティブや演算処理を行うparallel loopディレクティブにasync節を付けている。Asyncを付けると、CPUはGPUとのデータ転送やGPUでの処理を起動するだけで、完了を待たずにプログラムの次の行を実行して行くので、全てのGPUでの処理を並列に実行させることができる。

|
|
図7 1つのスレッドで、使用するGPUを切り替えて複数GPUを使う例 |
MPIを使用する場合は、それぞれのランクが1つのGPUを使用し、OpenMPを使用する場合は、それぞれのスレッドが1つのGPUを使用するという構造が良い。MPIのrank数やOpenMPのスレッド数が実GPU数より多い場合は複数のスレッドが1つのGPUを共用することになり、処理が面倒になる。
また、1つのスレッドで使用するGPUを切り替える第3の方法は原理的には可能であるが、正しく実装して性能を上げるのはチャレンジングであるという。
複数のGPUを使用する場合の根本的な問題は、自動的にはGPU間でデータが共有されないことであり、必要なデータを必要なところに正しくコピーし、GPU間のデータの一貫性を維持することに注意が必要である。

|
|
図8 複数GPUを使うには3つの方法があるが、いずれもGPU間のデータの一貫性を保つことに注意が必要である |
まとめ
1個のGPUでは性能が不足する場合は、OpenMPやMPIを使って複数のスレッドに処理を分散し、各スレッドではOpenACCで1個のGPUを使うというのが、標準的な複数GPUを使う方法である。この場合、1つの計算ノードのCPUはマルチコアであるのが普通なので、各コアで1つのMPIプロセスを動かしたり、OpenMPスレッドを動かしたりすれば、1個のCPUで複数のGPUを使うことができる。
また、OpenACCで使用するGPUのデバイス番号を切り替えて、1つのMPIプロセスやOpenMPスレッドで複数のGPUを使うことも可能であるが、現状では、CPUチップに十分なコア数があるので、無理に1コアで複数GPUを使う必要はなく、1コア、1GPUの構成で使うのが良いと思われる。