命令の読み込みには2サイクル、命令の解釈には3サイクル
コアの動きであるが、命令の読み込みにはPPFとPFの2サイクルかかり、命令の解釈(Decode)はD0~D2の3サイクルを必要とする。そして、整数命令では1サイクルの実行、1サイクルのレジスタへの書き戻し(Write Back)で、合計7段のパイプラインで命令を処理する。一方、VPU命令の場合は、D2の後に演算のオペランドをマスクするE、スキャッタギャザーを行うVC1、VC2というサイクルが入り、その後、4サイクルで演算を行い、全体では13段のパイプラインとなっている。ということで、汎用プロセサと比べると比較的段数の少ないパイプラインであり、動作周波数も低くなっていると推測される。
512ビット幅のVPUは、32ビット長の単精度浮動小数点数ならば16並列、64ビット長の倍精度浮動小数点数ならば8並列で処理を行うことができる。

|
|
512ビット幅の演算を行うVPUのパイプラインチャート。デコードから演算データを揃えるまで4サイクル、演算自体も4サイクルかかる |
連続アドレスにある512ビットのデータを処理する場合は良いが、変数のアドレスが連続でない場合には飛び飛びの番地からデータを読んでくるギャザーが必要となる。また、この逆で、飛び飛びの番地にストアする場合はスキャッタが必要となる。この飛び飛びのアクセスを行うのがスキャッタギャザーである。

|
|
スキャッタギャザーのメモリアドレスはベース+Indexの形で表現し、8個のIndex値の違うアドレスにアクセスできる |
スキャッギャザーでは、アクセスするメモリ番地をベース+Indexの形で表現し、この図ではそれぞれIndex0~Index7の値がベースアドレスに加算されてAddr0~Addr7が計算される。そして、最初はマスクレジスタをAll-1 にしておき、Find Firstで最初の1を見つける。そうすると、最初のビットが1なので、Addr0がマルチプレクサで選択され、アクセスアドレスとなる。そして、Addr0とアクセスアドレスが一致するので、マスクレジスタの最初のビットがクリアされて0になる。このアドレス計算と選択を行うのがVC1とVC2というサイクルである。
次にFind Firstを行うとAddr0に対応するマスクビットは0になっているので、Addr1が選択されて、…という風にAddr0からAddr7までのアドレスを順に処理して行く。この図ではアドレスごとに1次データキャッシュをアクセスする絵になっているが、連続するアクセスが同じキャッシュラインに入っている場合は、まとめて処理する方が効率的であり、Knights Cornerでもそのようになっているものと思われる。また、この図ではIndex0~Index7の8アドレスとなっているが、単精度データの場合は16アドレスを扱えるようになっていると思われる。
50個以上のコアとGDDR MACなどをつなぐリングは、時計方向と半時計方向の2つのリングが存在する。そして各リングは、512ビット(64バイト)幅でデータを送るBLリング、アドレスを送るADリング、キャッシュコヒーレンシ情報などを送るAKリングからなっている。そして、ADリングとAKリングはBLリングの2倍の速度で動いており、1つの512ビットデータを送る間にAD、AKリングは2つのアドレスやコヒーレンス情報を送ることができるようになっている。

|
|
リングは64バイト幅のBLリング、アドレスを送るADリングとコヒーレンスメッセージなどを送るAKリングからなり、時計方向と半時計方向の2重リングとなっている |
コアがアクセスするメモリ番地の内容が自分のL2キャッシュスライスに入っており、キャッシュをヒットした場合は問題ないが、L2キャッシュをミスした場合にはADリングとAKリングを使って、他のコアのTDにスヌープを送り、AKリング経由で応答を集める必要がある。

|
|
Triadというメモリバンド幅を測るベンチマークを実行した場合の性能のAD、AKリングがBLリングと同じ速度と2倍の速度の場合の比較 |
この図のように、AD、AKリングがBLリングと同じ速度の場合は、30コア程度以上にしても性能は飽和してしまっている。そして、AD、AKリングを2倍の速度で動かすと、50コアまである程度性能が上がって行き、50コアで比較すると40%程度性能が高くなるという図になっている。
しかし、Triadは単純な連続アドレスアクセスであるが、倍速のAD、AKリングでも20コア以上では性能が飽和気味である。2つの2倍速AD、AKリングでは、キャッシュミスの多いアプリケーションではリングが性能のリミットになってしまう恐れがあるように思われる。
Knights Cornerは、コアごとにクロックを止めるC1ステート、コアの電源スイッチを切るC6ステートを持ち、すべてのコアがC6ステートになるとL2キャッシュやリングのクロックを止めるパッケージオートC3ステートになるという省電力機構が組み込まれている。また、ホストプロセサのドライバの制御で、TDの電源をデータ保持電圧まで下げ、GDDRメモリもセルフリフレッシュにして節電するパッケージディープC3ステート、PCI Expressの電源も切るパッケージC6ステートにすることもできる。
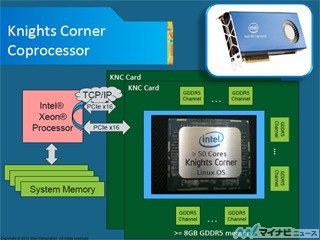
Knights Cornerの前世代のKnights Ferryは、元々はGPUとして開発されたのであるが、NVIDIAやAMDのGPUに対抗できないということでGPUとしての商品化は見送られた。今回の発表では、Knights CornerにテクスチャユニットやROPユニットなどのグラフィックス用の機能が搭載されているかどうかについては触れられなかったが、最初のスライドにある写真は、正に、ハイエンドGPUボードという感じであり、グラフィックス機能も搭載されているのではないかと推測される。
また、今回の発表ではコア数やクロック周波数などは公表されなかったのであるが、Top500 150位のシステムの諸元から推測すると、コア数は54、クロック周波数は1.111GHzとなる。この時のチップあたりの単精度浮動小数点演算性能は1.92TFlops、倍精度浮動小数点演算性能は960GFlopsとなる。この実験スパコンシステムに使われたチップと商品化されるチップのコア数やクロック周波数が同じになるとは限らないが、大きく外れることもないと思われる。