10月19日に東工大の大岡山キャンパスでGPUシンポジウム2010が開催されたが、その際に同シンポジウムを主催した東工大の青木尊之教授に、気象庁の次期気象予報コードであるASUCAのフルGPU移植について話を伺う機会をいただいたので、その内容についてお伝えしたい。

|
|
ASUCAのフルGPU化について説明する青木教授 |
青木教授のグループではGPUを使う各種の科学技術計算プログラムを開発しているが、2010年3月に、気象庁と共同開発を行ったASUCAのフルGPU化により、単一GPU(Tesla 10)で44.3GFlops、120GPUのシステムで3.22TFlopsを達成したと発表した(その後、TSUBAME1.2の528GPUを活用して15TFlopsを達成している)。ASUCAは気象庁が次期天気予報プログラムとして開発を進めているメソスケールの気象計算プログラムである。ASUCAでは平面方向は1km以下、数1000km程度の範囲の気象の計算を行う。つまり、XY方向に数1000個、Z方向に100個程度のセルが並び、全体では数~数十億個程度のセルの状態をタイムステップごとに計算することになり、膨大な計算が必要となる。

|
|
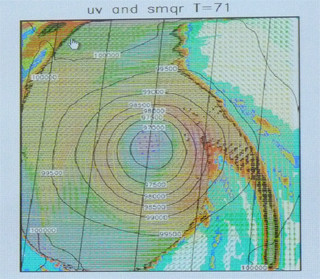
ASUCAによる台風の計算例 |
──大規模なASUCAプログラムのフルGPU化というのには驚いたのですが、どんなところが苦労されたところでしょうか?
青木(以下、敬称略):GPUに向いた計算であるという点で、津波、気象などの圧縮性流体のアプリケーションを考えていました。特に、気象の流体計算は演算よりメモリアクセスが律速になる計算なので、GPUのメモリバンド幅が大きい点が活かせると考えて選択しました。
気象の計算は、大きく分けて、大気がどう動くかという流体計算の力学過程と、湿気が凝縮して雲ができたり、雨に変わったりというような変化や、太陽による輻射の影響などを計算する物理過程があります。物理過程は自分のセルで閉じて隣のセルを参照しないのでGPU化は容易ですが、コードが頻繁に変わります。また、物理過程はここに挙げたもの以外にも多くの現象があり、物理過程のプログラム量は多いのですが、ASUCAでは、まだ、開発段階になるため現状で数万行のプログラムとなっています。
気象計算は一般的に計算処理量としては力学過程、物理過程が半々くらいですが、ASCAはまだ、開発段階にありますので、力学過程の計算量が多いのが特徴です。力学過程は直交格子上に確保した配列へのメモリアクセスなので、メモリのアライメントを揃えればGPUのメモリバンド幅が活かせます。研究用ではなくオペレーションコードなので規模が大きくてフルGPU化は大変ですが、頑張れば必ず出来る問題と考えて、ASUCAを選択しました。
気象コードは普通Z方向が最内ループになっていますが。この部分は3重対角行列で逐次計算が多く、これではGPUでの処理性能が出ないので、Y方向を最外ループ、Z方向を中間ループ、X方向を最内ループに変更しました。配列のインデックスの順番が変わるのでコードは大変更になります。元々ASUCAはFORTRANで書かれていますが、当時はGPU用のFORTRANコンパイラが無かったこともあり、大変更するくらいならC/C++で全部書き直すことにしたのですが、この作業が大変でした。
最初はCでホストCPUで動かし、部分、部分を順次GPU化して動作を確認するという方法で開発を進めました。関数が物凄く沢山あり、ボトルネックが残っているとなかなか速くならず、非常にしんどい開発でした。
計算に使ったGPUはTesla S1070で、頻繁にアクセスする変数はシェアードメモリに載せないと性能が出ないこともあり、問題サイズによって必要なメモリ量が変わったりしますが、それを一定量のシェアードメモリに載せるのが大変でした。また、通信時間を隠ぺいするため、オーバーラッピング手法などのテクニックを使いますが、通信バッファからPCI Expressバスを介したコピーの時間が掛かります。さらに、通信時間よりも計算時間が短くなって、十分に通信時間を隠ぺいできないケースも出てきました。

|
|
フルGPU化したASUCAの実行性能。528GPUで15.0TFlopsを達成 |
──シェアードメモリ化やオーバーラッピング手法などを使うとコードが見にくくなりますよね。
青木:確かにASUCAも開発が進んでいくので、それとの同期は問題です。また、1つの関数が結果をグローバルメモリに書き出し、そのデータを次の関数で入力としてグローバルメモリから読んでいるケースは、2つの関数を融合してグローバルメモリを経由しないでデータを受け渡す構造にすれば性能が上がるのですが、これをやってしまうと元のコードとの対応が付かなくなってしまうのでコード開発の継続が難しくなります。
NVIDIAのGPUはFermiコアになり1次キャッシュが入りました。我々の流体系プログラムではほとんどのコードがシェアードメモリを使わずにキャッシュを使う方が性能が高いという結果になりました。
──GPUはまだ、アーキテクチャがどんどん変わって行くと思われるが?
青木:そこはよく分からないところですが、キャッシュが使えるようになってCUDAのプログラミングの負荷は大きく軽減されました。また、指示行を入れるだけでGPU化を行うコンパイラでも性能が出やすくなるという効果も期待されます。
──Fermiになって研究者側としては使いやすくなったのか?
青木:単精度のピーク性能ではあまり改善されていませんが、使い勝手という点では大きく改善されました。キャッシュの効果でシェアードメモリを上手く使いまわすための工夫が不要になった点が大きいのですが、倍精度命令発行のスケジューリングが不十分で、倍精度のピーク性能を引き出しにくいなどさらに改善してほしい点もあります。
私が学生の頃は、将来はコンパイラがすべて自動並列化をやってくれてプログラミングは楽になるだろうと思っていましたが、現実はまったくの逆で、CPUでもマルチコアになっていますし、性能を引き出すためには、プログラマがハードアーキテクチャをかなり意識してプログラムを書かないと十分性能を引き出せない状況になっています。ということで、昔、想像していた未来とは大きく違った環境になっているというのが今の心境です。しかし、世界でトップの研究成果を目指すならGPUを使っていかないと勝てない時代になっているのは確実なので、GPU向けのプログラムの書き換え技術の習得は必須だと思っています。
──本日はありがとうございました