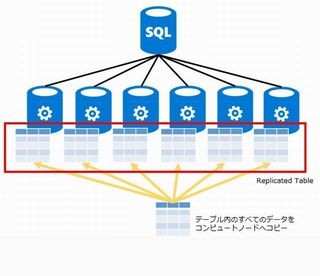
SQL Data Warehouseではテーブルのデータをディストリビューションへ分散して格納することは、前回まででご説明した通りです。今回はSQL Data Warehouseで作成可能なテーブルとインデックスに焦点を当てて説明します。
SQL Data Warehouseで作成可能なテーブルおよび、インデックスは主に3種類あります。
- クラスター化列ストアインデックス(デフォルト)
- ヒープテーブル
- クラスター化インデックスと非クラスター化セカンダリインデックス
以下、それぞれの特徴を説明します。
クラスター化列ストアインデックス
テーブル作成時、何も指定しなければクラスター化列ストアインデックスとしてインデックスが作成されます。クラスター化列ストアインデックスは、データを列指向型で格納し、格納されたデータに対して非常に高い圧縮を実現します。OLTPなどで利用されるDatabaseの多くは行型でデータを格納しますが、大量のカラムから少ないカラムを抽出する、あるいは集計するなど特にDWHのような分析処理を行うDatabaseの場合、列指向型でデータが格納されておりなおかつ高圧縮であるほうが、データのアクセス効率が良く、結果として高速な処理が可能となります。
 |
DWHシステムの環境下におけるファクトテーブルに代表される、非常にカラム数の多い大量の件数のデータを格納するような要件のあるテーブルで、このクラスター化列ストアインデックスを選択することが最適といえます。
クラスター化列ストアインデックスについて、もう少し細かいアーキテクチャを紹介します。
 |
もともとクラスター化列ストアインデックスはSQL Server 2014の機能としてリリースされたものであり、SQL Data Warehouseの独自の機能ではありません。このオブジェクトにデータが格納されると、カラムストアかデルタストアのどちらかの領域にデータが格納されることになります。このカラムストアとデルタストアの違いは、カラムストアは列指向でデータが格納され、データの圧縮が行われる一方、デルタストアは行型でデータが格納され、データは非圧縮だということです。
クラスター化列ストアインデックスを使用する場合、カラムストアの領域にデータが格納されることが重要です。デルタストアにデータが格納されると、データは行型で格納され非圧縮の状態となるため、パフォーマンスは著しく低下してしまいます。カラムストアでは行グループが構成されており、この行グループの単位で列ストア形式に圧縮が行われています。行グループの最大は1,048,576行です。
デルタストアにデータが格納されてもクラスター化列ストアインデックスとして本来の性能を発揮できないため、どのようなタイミングでカラムストアにデータが格納されるのかを理解しておくことは重要です。カラムストアにデータが格納されるのは以下の場合です。
- 一括ロードで102,401行以上のデータを投入した場合
- デルタストアに格納されるデータの件数が1,048,576行を超えた場合
- インデックスのメンテナンスを行った場合
上記からも確認いただけるように、クラスター化列ストアインデックスはデータが100万件を超えるような大きなテーブルで初めてパフォーマンスが最適化されます。
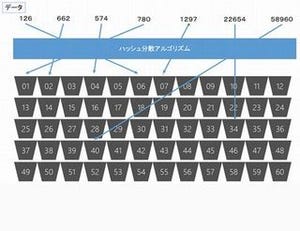
また、注意が必要なのは、SQL Data Warehouseは60のディストリビューションへ分散してデータを格納する点です。それぞれのディストリビューション単位でクラスター化列ストアインデックスを作成するため、SQL Data Warehouseの場合は100万件ではなく100万件の60倍の6000万件以上、実際にはディストリビューション単位でのデータの偏りも考慮に入れると1億件以上のデータがあって初めて最適なパフォーマンスを得られるといえます。
CREATE TABLE TEST_TABLE
( id int NOT NULL, Name varchar(20), Code varchar(6) ) WITH ( CLUSTERED COLUMNSTORE INDEX )
ヒープテーブル
クラスター化列ストアインデックスは大量の件数のデータがあって初めてパフォーマンスが最適化されることは先述の通りですが、いくらDWH環境や分析環境といってもすべてが大量のデータを有しているテーブルばかりではありません。
そうした場合に利用を検討すべきテーブルがこのヒープテーブルです。ヒープテーブルは行指向でデータが格納され、クラスター化インデックスを持っていません。一時的に少量のデータを読み込みたい場合や、様々な変換を行う前にデータを一時的にステージングするためのテーブルとして利用する場合は最適です。
また、クラスター化列ストアインデックスが本来のパフォーマンスを発揮できる1億件程度のデータに達さないようなテーブルの場合、このヒープテーブルの利用を検討します。
CREATE TABLE TEST_TABLE
( id int NOT NULL, Name varchar(20), Code varchar(6) )
クラスター化インデックスと非クラスター化セカンダリインデックス
大量のデータから1件あるいは非常に少数のデータへアクセスする場合、クラスター化インデックスが有効です。大量の件数から非常に少量の件数(少量の範囲)のデータへのアクセスを行いたい場合、このクラスター化インデックスを使用して、特定のデータへアクセスする方法を検討します。
ただし、クラスター化インデックスが機能し、少量のデータへ素早くアクセスできるのは、クラスター化インデックスで指定した列のみです。その他の列でも絞り込みやフィルターを行いたい場合には非クラスター化セカンダリインデックスを作成します。
ただし、非クラスター化セカンダリインデックスをたくさん作成すると、そのテーブルにデータを格納する時など、非クラスター化セカンダリインデックスに対する更新のオーバーヘッドでデータを格納するための処理時間が長くなることに注意が必要です。
CREATE TABLE TEST_TABLE
( id int NOT NULL, Name varchar(20), Code varchar(6) ) WITH ( CLUSTERED INDEX(id) )
山口 正寛
1984年生まれ。大阪府出身、東京都在住。データベースエンジニア。SQL Server、Oracle、MySQL、PostgreSQLなどのデータベースで、小規模から大規模な案件まで数多く経験。現在ではクラウドの流れに逆らうことなく、「データベース×クラウド」をキーワードに案件対応、セミナー活動、執筆活動など幅広く活動中。株式会社システムサポート所属。