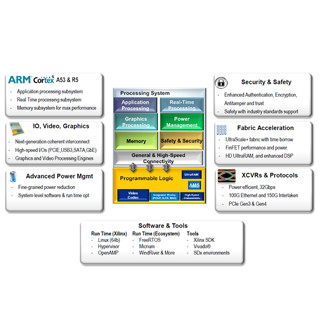
各部の詳細な構造
FetchとWavepoolの構造は次の図のようになっている。この部分は、実行するWavefrontに対応してPC0~PC39を選択して命令キャッシュから命令を読み出してWavepoolの命令キューに格納する。そして、Wavepool Controlの制御で、それを読み出して実行ユニットに供給する。命令と同時にLDSやSGPR、VGPRのどのエントリから使うのかを示すBase0~39の値を実行ユニットに供給する。Wavepoolはインクリメンタを持ち、次に実行する命令を指すように命令キューのポインタを更新する。

|
|
40 Wavefrontの中から実行するものを選び、そのPCにしたがって命令キャッシュから命令を読み出し、Wavefrontごとの命令キューに格納する。格納された命令は入力が揃っているかをチェックし、順次取り出されて、レジスタなどのベースアドレスとともに実行ユニットに送られる |
ベクタALU実行ユニットは、4エントリのOperand & Opcode0~3キューと、Output & VCC0~3キューを持つ。Operand & Opcode0~3キューはVALUコントローラから命令を受け取り、レジスタファイルから読み出されたオペランドを格納する。
そしてベクタVALUは整数演算や論理演算を16WideのSIMDで実行し、Operand & Opcode0~3キューは4命令を含むので、全体では64スレッドのWavefrontの処理を行うことができる。
演算結果はWrite Backキューを経由して、レジスタファイルに書き戻される。

|
|
4命令分の入力キューと出力キューを持ち、それぞれの命令が16WideのSIMD演算であるので、4命令で64スレッド分の計算を行なう。演算結果はWBキューを経由してレジスタファイルに書き戻される |
命令のイシュー部は命令の情報と、CUのWaitなどの状態と各実行ユニットのレディ状態を見て、どの命令を発行するかを決定する。

|
|
命令の動作やメモリ待ちなどのCUの状態と各実行ユニットの使用可否の情報を総合して、次にどのWavefrontの命令を実行するかを決めて実行ユニットに命令を発行する |
ロード、ストアユニットは命令の情報を受け取り、アクセスするメモリアドレスを計算してLD/STバッファに格納する。そして、LD/STバッファからアクセス要求を取り出してメモリのアクセスを行う。

|
|
命令の情報とレジスタに格納されたベースなどの値からアクセスするメモリアドレスを計算し、ロードストアバッファに入れる。ロードストアバッファのメモリアクセス要求は、順次、取り出されてメモリをアクセスする。ロード命令の場合は、WBキュー経由でレジスタファイルに書き戻す |
MIAOWの設計手法とFPGA部の実装
MIAOWの設計であるが、次の図の(a)のようにすべてをRTLとハードマクロで設計すれば本当の設計に最も近いが、設計変更の自由度が小さい、設計コストが高いという問題がある。(b)のようにFPGAを使い、DispatcherやCUのロジックはRTLで作ってFPGAにマップし、キャッシュやレジスタファイルはFPGAのブロックRAMを使い、DRAMインタフェースはFPGAのマクロを使うという設計は、設計の自由度やリアリズムは中くらいで、コストは安いが、設計の期間は長くなる。(c)は折衷案で、ブロックRAMの部分とDRAMインタフェースの部分をC/C++モデルにしてしまうという案である。
この(c)案が自由度が高く、コストも安く、設計期間も短くできることから、MIAOWでは(c)案で設計を行っている。

|
|
(a)ASIC設計、(b)FPGAでの実装、(c)FPGAとC/C++モデルのハイブリッドの3種の設計の比較。MIAOWでは(c)を採用した |
そしてロジック部分は、次の図に示すように、XilixのVirtex 7 FPGAに実装している。133K個のLUTと100K個のレジスタを使い、FPGA1個に1CUを作り込んでいる。このFPGAでできたNEKOと呼ぶCUは、50MHzで動作するという。

|
|
Virtex 7 FPGAで設計したCUのロジック部。これは1CU分で133K LUTを使用。50MHzクロックで動作する |
MIAOWの互換性
MIAOWのAMDのGCN GPUとの互換性であるが、OpenCLで書かれたプログラムは変更なしに実行できるという。また、AMDのAPP SDKのOpenCLのすべてのベンチマークが動作する。また、バージニア大学がヘテロジニアスな環境用に開発したRodinaベンチマークの内の多くのものが動作するという。

|
|
OpenCLのプログラムは変更なしで動作し、AMD GPUと高い互換性を有している |
次の図は、MIAOWのCUとAMDのGCNアーキテクチャのGPUのCU(2014年のHot Chipsで発表されたもの)を比較したもので、MIAOWでは実装していないテクスチャ処理の部分を除くと似たようなものである。

|
|
MIAOWとAMDのGCN GPUのCUのフロアプランの比較。3Dグラフィックス用のテクスチャ機能がない点を別とすれば、よく似ている。MIAOWはチップの物理設計は行っていないので、ハイレベルの検討結果と思われる |
(次回は9月23日に掲載します)