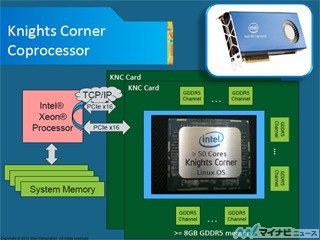
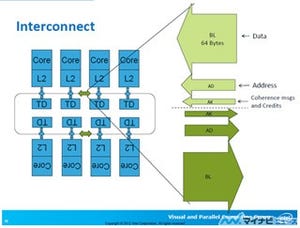
Intelは11月13日、同社が2012年6月に発表したHPC向けコプロセッサ「Xeon Phi」の第一弾製品として、「Xeon Phi 5110P」ならびに「Xeon Phi 3100ファミリ」を発表した。

|
|
インテルのクラウド・コンピューティング事業本部 事業開発本部 本部長の岡崎覚氏 |
Xeon Phiについて、インテルのクラウド・コンピューティング事業本部 事業開発本部 本部長の岡崎覚氏は、「Xeon PhiはPFops時代ではなく、ExaFlopsの時代に向けたチャレンジの結果として生み出された高並列アプリケーション向けコプロセッサ」と、2018年の1ExaFlops実現に向けた超並列演算への道筋をつけるものとして生み出されたと説明する。
Xeon Phi 5110Pは60コア(4スレッド/コア)を搭載し、コア周波数は1.053GHz、8倍精度数の演算ベクトル長(1クロックの演算数は2)で、8GBのGDDR5を搭載(ピークメモリ帯域320GB/s)し、1枚あたりピーク演算性能は1.011TFlops(倍精度演算性能)となっており、例えばXeon E5-269を2基搭載したサーバに5110Pを4基搭載したシステムの場合、ピーク演算性能は4.4TFlopsに達するという(E5-2690 2基で371GFlops、5110P 4基で4.044TFlops)。これは2002年に導入された初代の地球シミュレータに匹敵する性能であり、同システムが320ラック、1300m2で実現した性能を2ラック、4m2で実現できるようになるとするほか、実際のサードベンダによるアプリケーションを用いたベンチマークでは、Xeon単体と比較した場合で約2倍程度から、アプリーションによっては10倍を超す演算性能を達成したという。

|

|
|
Xeon単体利用時との各種ベンチマーク比較では、おおむね2倍以上の処理性能の向上が見られたほか、アプリケーションによっては10倍程度の性能向上も見られたという |
|
一方のXeon Phi 3100ファミリは6GB GDDR5を搭載(ピークメモリ帯域幅240GB/s)し、1TFlops超の倍精度演算性能を提供するコプロセッサ。5110Pに比べ、メモリ容量や帯域幅を抑え、価格を意識したファミリという位置づけで、「コア間通信をそれほど行わない、演算処理中心のワークロードでは5110Pと同程度の性能を発揮できる」(同)とする。

|

|
|
向いているアプリケーションが異なる5110Pと3100ファミリの2種類が用意され、ユーザー側で用途に応じたシステムを選択することが可能となるとのこと |
|
また、HPC/スーパーコンピュータで高い性能で並列処理を行うためにポイントとなるソフトウェアについては、Xeon Phiに対応済みの「Intel Parallel Studio XE 2013」がすでに出荷を開始しているほか、「Intel Cluster Studio XE 2013」も新たに対応版として提供される。2つのツールの違いは、Parallel Studioが1ノードでの利用を前提としたもので、Cluster Studioはスーパーコンピュータ/HPCなどのクラスタシステムでの利用を前提としたもの。
こうしたツールについて同社は、「GPUコンピューティング(GPGPU)の場合、コンパイラに投げる前に並列コード部分を抽出して、GPUで並列処理をしやすいように専用の言語やツールを用いて開発する必要があり、新しくそうした言語やツールの使用法を習得する必要がある。これだとプログラマがある程度譲歩する必要がでてくる。しかし、Xeon Phiではx86アーキテクチャベースであり、基本的にはXeonでの作業と同じプログラム環境を用いて開発することができ、GPGPUに比べてプログラマのハードルを一段下げることができる」とその利点を説明。すでにパートナー企業各社もツールの開発を進めているとのことで、11月10日から16日にかけて米国にて開催されているSC12の期間中に、さまざまなツールベンダから発表される予定としている。

|

|

|
|
GPUコンピューティングを活用するためにCUDAやOpenCLなどを習得する、といった新たな手間をかけずに従来のx86ベースのツールで並列化を可能とすることで、開発負担を減らせるというのがXeon Phiのメリットだとのこと |
||
実際のXeon Phi 5110Pの提供は2013年1月28日より、各システムベンダから搭載システムとして提供される予定。国内では、Cray、Dell、富士通、NEC、日立製作所、HP、IBM、SGIなどが提供を予定しているという。また、Xeon Phi 3100ファミリについては、2013年上半期中の出荷開始を予定しているという。価格は5110Pは2650ドル/1000個ロット時、3100ファミリが2000ドル以下をそれぞれ予定している。

|

|
|
Xeon Phi 5110Pのダイ画像とXeon Phi 5110Pの実機 |
|

|

|

|
|
Xeon Phi 5110Pの実機のフロント、リア、そして背面 |
||

|

|
|
Xeon Phi 5110Pを4基搭載した4Uサーバ。CPUとしてはXeon E5-2690が2基搭載されており、これで4.4TFlopsの理論ピーク演算性能を実現できるという |
|
なお、すでに一部の研究機関などがXeon Phi 5110Pを搭載したシステムの評価を、国内では東京大学、筑波大学、京都大学、理化学研究所などが進めているほか、11月12日(米国時間)に発表されたスパコンの性能ランキング「TOP500」で、7位にランクインしたテキサス大学の「Stampede」にも採用されており、LINPACKベンチマークで2.660PFlops(理論演算性能は3.959PFlops)を達成している。DellのPowerEdge C8220(Xeon E5-2680 2.700GHz 8コア×2基、Infiniband FDR、Xeon Phi。トータル20万4900コア)を採用しており、Xeon E5ファミリ単体では約2PFlopsのピーク性能だが、Xeon Phiを搭載することで、最大で8PFlopsまで演算性能を向上させることができるという。このほか、NVIDIA Tesla M2090なども搭載されており、最終的やシステムトータルのピーク性能は10PFlopsに達する予定としている。

|
|
テキサス大学の「Stampede」に採用されているDellのPowerEdge C8220クラスタ(出所:テキサス大学Webサイト) |