Hot Chips 29においてARMはbig.LITTLEを改良する新クラスタデザインである「DynamIQ」を発表した。

|
|
Hot Chips 29においてDynamIQについて発表するARMのPeter Greenhalgh VP |
現在のbig.LITTLEはビッグコアとリトルコアが1対1に必要という制約があるが、DynamIQ big.LITTLEになると、その制約が無くなり、より自由な構成が可能になる。さらに、エネルギー効率も性能も改善されているという。
DynamIQでは、Cotex-A75ビッグコアとCortex-A55リトルコアを組み合わせ、各コアにはプライベートなL2キャッシュをつけ、全コアで共有されるL3キャッシュを設けるという構成になった。DSU(DynamIQ Shared Unit)はL3キャッシュに加えて、SCU(Snoop Control Unit)やすべてのクラスタインタフェースを含んでいる。

|
|
DynamIQ big.LITTLEでは1ビッグ+7リトルから1ビッグ+2リトルまで各種の構成が可能になる。DynamIQ Shared Unitには全コアで共通のL3キャッシュが含まれる (このレポートのすべての図は、Hot Chips 29におけるARMのPeter Greenhalgh氏の発表スライドのコピーである) |
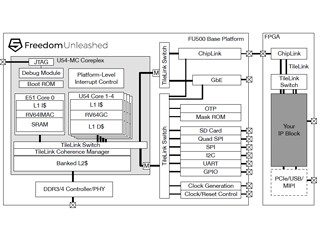
DynamIQクラスタは、0-7の最大8コアとDSUで構成される。DSUは、プロセサコアを始めとするすべての主要コンポーネントを接続する非同期ブリッジと、スヌープフィルタ、L3キャッシュ、バスI/F、ACPと周辺接続ポート(PP)、パワーマネジメントなどを含んでいる。
スヌープフィルタは、データを持っていないことが確実なコアにはスヌープを行わないようにしてブリッジの混雑を減らすものである。ACPは高速のアクセラレータなどを接続する口である。

|
|
DSUはすべてのコンポーネントを接続する非同期ブリッジとスヌープフィルタ、L3キャッシュ、バスインタフェース、ACP、電源制御などを含んでいる |
次の表にみられるように、Cortex-A75とA55は、(L3キャッシュを付けL2の容量を減らしての高速化するなどにより)前世代のA73、A53と比較するとL2キャッシュのヒットレーテンシが半減している。インタコネクトバウンダリのレーテンシは、ほぼ同じであるが、L3キャッシュがあるのでDRAMをアクセスする頻度が減っているので、メモリアクセス性能は改善されていると考えられる。

|
|
Cotrax-A75、A55はA73、53と比べると、L2ヒットのレーテンシが半減している。また、インタコネクトバウンダリのレーテンシはほぼ同じであるが、L3キャッシュの新設で、メモリアクセスの頻度が減り、性能が改善されていると考えられる |
DynamIQのL3キャッシュは、他の多くのプロセサのL3キャッシュとは異なり、コアグループに対応して区分されている。例えば通信制御の場合は、コアグループ1にデータプレーンの処理を行わせ、コアグループ2にコントロールプレーンの処理を行わせる。このような場合、L3キャッシュが共用であると、一方の処理のメモリアクセスで、他方の処理のデータがキャッシュから追い出されてしまうということが起こり、全体の処理性能が下がってしまう。
これに対して、データプレーンの処理とコントロールプレーンの処理が使うL3キャッシュの領域を分けておくと、それぞれの処理で使えるL3キャッシュ量の上限は小さくなるが、両方の処理が相手のデータをキャッシュから追い出してしまうということが無くなり性能が安定する。
車の制御の場合は、ADASのそれぞれの処理ごとにプロセサグループを分け、使用するL3キャッシュ領域も分割すれば、干渉で予期せぬ性能低下が起こるという事態を避けられる。

|
|
DynamIQではコアグループごとに使用するL3キャッシュ領域を区分できる。この図は2グループに分割した場合を示す |
そして、DynamIQでは、ACPに接続したアクセラレータやI/OはL3キャッシュやL2キャッシュに直接アクセスすることができる。このようにして、キャッシュにデータを隠しておく(Stashing)ことにより、メインメモリ経由のデータ伝送に比べて、アクセス時間を短縮して、処理性能を上げることができる。

|
|
DynamIQでは、アクセラレータやI/Oが直接L2キャッシュやL3キャッシュにアクセスすることができる |
次の図の左側の絵のようにPeripheral Port(PP)を使ってアクセラレータに指示を出し、ACP経由でコアのキャッシュからデータを読み込み、アクセラレータで処理を行ってコアのキャッシュに結果を書き戻すという密な結合は、暗号アクセラレータなどを接続する場合に向いている。
また、右の絵のように、I/Oエージェントからデータをコアのキャッシュに書き込み、そのデータをプロセサコアで処理して、処理完了をPP経由でI/Oエージェントに通知し、コアのキャッシュから処理結果を読む、あるいは次の処理のデータを送るという形態の接続はネットワークのパケット処理に向いている。
どちらのケースもアクセラレータやI/Oから直接、L2キャッシュやL3キャッシュをアクセスできるので、メモリアクセスオーバヘッドを小さくできる。

|
|
アクセラレータやI/Oがコアのキャッシュに直接アクセスすることにより、レーテンシを短縮して密な結合を実現する |