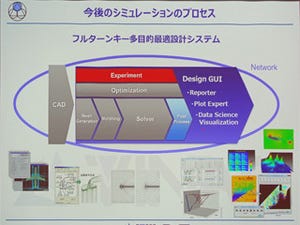
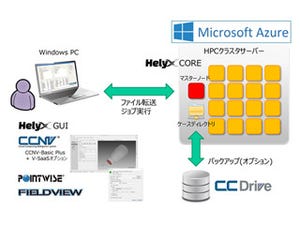
ヴァイナスは10月12日~13日にかけて、都内で同社のユーザー会である「VINAS Users Conference 2017」を開催。メインテーマ「大規模高速計算・最適設計・ワークフローマネジメントのためのソリューション -オープンソースとクラウドコンピュータの設計利用-」をメインテーマに同社が提供する設計ソリューションや、ユーザー事例の紹介などを行った。
|
|
|
京都大学大学院医学研究科の奥野恭史 教授 |
基調講演には、京都大学大学院医学研究科の奥野恭史 教授が登壇。「AI創薬の現状と可能性」と題し、同氏が代表を務める創薬コンソーシアムの取り組みを中心に、スーパーコンピュータ(スパコン)や人工知能(AI)などの先端計算技術の創薬への適用に向けた可能性についての紹介を行った。
冒頭、奥野氏は、昨今加熱するAIに対する報道に対する危惧を示し、大きな可能性を秘めていることを認めつつも、今はまだ、過去の膨大なデータを元に、学習を行い、そこからの発展系を導くことは可能だが、何もない状況から、いきなり新たな発見をすることはできないことを強調。そうした中で、製薬業界におけるAIの活用とはどのようなものかといった応用を検討していった結果、過去の実験や医療における薬を使った際のデータが蓄積されていることを踏まえ、これを学習させることで、AIにより新たな薬の設計ができるのではないか、という考えのもと、2016年12月にライフサイエンス系企業や大学などを中心とした「ライフインテリジェンスコンソーシアム(LINC)」を設立。以降、次々と加盟者が増えており、現在では約80の企業・団体が参加し、参加者の数も約550名におよんでいるとする。

|
|
「ライフインテリジェンスコンソーシアム(LINC)」の概要。参加費用は無料だが、代わりに人材を拠出してもらい、AI開発に参加することが義務付けられている (以下のスライドはすべて、VINAS Users Conference 2017における奥野教授の発表資料より抜粋) |
LINCの特徴について奥野氏は、「ライフサイエンスのためのAI開発を業界あげて一気に進めましょう、ということで、ライフサイエンス企業とIT企業が一緒になって、そこにアカデミアが入った枠組みとなっている点」と説明。2016年12月の設立から、約半年で、テーマ提案、調査、AI設計を進め、2017年7月より実際に29種類のAI開発を開始するという、スピード感をもった取り組みが行われている。
では、実際に、どういったAIの開発を進めていくのかというと、医薬品の開発は、病気の原因となるターゲットたんぱくなどを探索した後、それに対して効果のある化合物を探索。それが実際に効果を発揮することを細胞や動物実験などを経て、人間への臨床試験、副作用の評価などを行い、そこでも問題ないとなって、価格なども含めた形で承認がおり、その後、ようやく一般の患者のもとに届けられるという流れで、実際の開発には1000億円以上の開発費と10年ほどの研究期間が必要となり、この開発コストと期間を削減したいという考えのもと、「業界丸ごとAI化」をキーワードに、開発プロセスの全域をカバーするAIの開発を進めているという。

|
|
LINCが2017年7月より開発を始めた29種類のAIの概要。ヴァイナスはWG10の「AI基礎」に人材を拠出している。このWG10と、WG9「知識ベース・NLP」は、ほかのAIの共通部分という位置づけとなっているとのこと |
具体的には、開発プロセスなどで分けられた10のワーキンググループ(WG)を組織、その内部で、さらに複数の目的に応じたAIの開発が進められ、その数は合計で29種類が予定されている。「どういったAI活用の可能性があるかといえば、例えば画像処理をベースとした病理診断」(同)とするが、細胞レベルの画像を認識いて、良否の判別などを行うためには、さまざまな工夫を施していく必要があるとする。また、一方でパフォーマンスを発揮しにくい分野としては、「分子設計」の分野が挙げられた。分子設計では、創薬のターゲットとなる原因たんぱくに結合する物質を探索する必要があるが、どういったたんぱくと、どういった化合物が過去に結合した可能性があるという実験データなどを学習させることになるが、こうした過去の結果からの判定については、奥野氏自身も長年、研究を進めてきており、「これだけではAIになったからすごい、とはいえない」と語る。というのも、この手法で、たんぱくと結合する化合物を探索するためには、なんらかの化合物の構造を人間があらかじめ用意する必要があり、結局、人間の手を必要とするためだ。「期待されるのは、たんぱくの情報だけを入力するだけで、AIが勝手に化学物の構造をデザインしてくれる」というものであり、そうした研究が進められていくこととなる。

|
|
奥野教授が京大病院と協力して行ったディープラーニングによる腎臓の病理画像診断(糸球体の認識)。人間の識別は、特徴点が分かりやすいため、認識しやすいが、細胞はそういった特徴を抽出するのが難しく、その中から糸球体のみを認識させるには工夫を施す必要があったというが、3か月程度で90%ほどの正答率で自動認識させることができたという |
また、例え薬が完成し、承認を得て、販売出来たからといっても、例えばがんでは、米国FDAの少し前の統計だが、がん患者の75%は抗がん剤が効いていないという調査結果が出ているという。抗がん剤は高価で、かつ副作用の生じることから、薬が効かない患者に副作用のリスクを負わせ、高額な医療を施す必要があるのか、という話になり、そこでゲノム情報を活用して、どの薬が効果を発揮できるのか、ということを事前に調べて投与する「プレシジョン・メディシン(Precision Medicine)」に注目が集まることとなっている。京都大学医学部附属病院(京大病院)でも、がん患者からサンプルを受け取り、そこから正常な遺伝子との配列の違いを調査。その違いが薬で対応できるのかを判断した上で、患者に抗がん剤で投与、というフローのもと、取り組みが進められているとのことであるが、実際に過去の文献や関連データベースなどから、効果があるかどうかといった調査は人間が行っているのが現状だという。「ゲノム解析は10年以内には数万円で可能になる。そうすると、何でもかんでもゲノムを調べよう、という流れになり、蓄積されるゲノムの量が一気に増加。併せて文献も増加の一途となり、これまでのマニュアルでやってきたことが追いつかなくなる。しかし、病気の進行は待ってくれない。そうしたデータの増加に追いつくために、AIが人の代わりにデータベースや文献からマイニングを行う必要がでてくる」(同)とし、詳細は明らかにしなかったが、日本人のゲノム情報を元にした最適な薬を探索する技術の開発も進めているとした。

|

|
|
左が現在の臨床ゲノムシーケンスの手法。文献やデータベースを人間の手によって調べ、判断している。しかし、近い将来、ゲノムデータが爆発的に増えたときに、同様の手法はとることが難しくなることから、そこをAIに行わせ、その結果を人間が判断するという方向にシフトする必要があるという |
|
ただし、「こうしたシステムができれば現場の問題は解決するかというと、それほど現実は甘くない。がんの場合では、ゲノム情報を書き換えることで、薬剤に耐性を持ってしまうため、一度、ゲノムを解析すれば大丈夫、ということはないし、遺伝子の変異についても、論文に出てくるものは、解釈しやすいものが多いが、実際の患者のデータからは、解釈が難しいものも出てくる。そうした臨床的意義が不明(VUS:Variants of uncertain significance)な変異に対しては、現状のAIでは、何も情報がないため、解決はできない」ということで、ゲノム情報をAIで判断するアプローチを行いつつ、たんぱく上で変異を再現し、薬剤の反応性が変わるのかについて、物理モデルでシミュレーションを行うことも並行して進めていく必要があるという。

|
|
スーパーコンピュータ「京」を用いた肺がんのターゲット遺伝子となるALKタンパクの変異シミュレーション。通常の配列から、変化した状態になると薬が効かなくなるということが知られている。ゲノムの配列解析を実施し、予測解析ができるか、という話で、過去に似たようなデータがなければ推論ができないのが現在のAIであり、そうしたデータを生み出すためには、シミュレーションによる実験で予測を行うことが現場では重要になるという |
このシミュレーションを行うという行為の重要性について同氏は、「実験側から、こういった物質に対する予測をしたいという依頼がくるが、未知の物質であると、データが存在していない。そのため、実験側に少々実験をお願いするのだが、実験側からは、実験の手間を省きたいから、計算をお願いしている、というかみ合わない事体が発生することになる。この解決方法の1つとして、実験データのないものに対するシミュレーション実験を行い、それをAIに学習させる。ただし、それだけでは、実世界との誤差が膨れ上がるので、必要最低限の実験を行うことで、それを修正し、適切なモデルを構築していく必要がある」と説明。こうした取り組みで生産プロセスを加速させつつ、開発時間の短縮とコスト削減を図っていかなければ、規模の大きな中国や米国企業とのグローバルの競争に勝ち残っていけないとし、「AIに興味がある人は、シミュレーションを捨てずに、物理実験も重視していってもらいたい」と、両輪で開発を行っていくことの重要性を強調した。

|

|
|
ライフサイエンス分野における現在のAI利活用で生じる2つの大きな課題(左)と、それに対する奥野教授の答え(右) |
|
最後に、同氏はLINCの目指す方向性として、「AIは産業革命が起きたときのような、産業シフトを引き起こすインパクトを有している。10年も経てばAIの利用は当たり前の社会になる。そうなったとき、薬の研究開発にあたって、どのような薬を作ればよいかをAIに聞くと、社会情勢などを踏まえ、最適な薬の開発を提案するところから、病気の原因たんぱく、それに効果を及ぼす化合物、副作用、安全性、そして適切な値段といった答えが返ってくることを目指して29種類のAIの開発を進めている」としたほか、その先の野望として、「これらができたら、29種類のAIのアウトプットが、その後段のインプットになることで、すべてを自動的に開発できるようになる世界を構築したい」と述べ、2030年ころには、こうした野望に近いものが製薬業界で、しかも日本発のソリューションとして実現できることを今後、目指していきたいとしていた。

|

|
|
LINCの目指すゴールのイメージ。最初は、それぞれのAIが別個に結果を出すが、将来的には、それが次のプロセスと結びつき、一貫した流れを生み出すことを目指したいという |
|