Xeonの先を目指すXeon Phi、AIを目指すNervane
最後の3つ目はXeon Phiの本格的な立ち上がりが見えてきたIntelの動向を見ておきたい。同社にとっての2016年は、最新世代のXeon Phi「Knights Landing(KNL)」(開発コード名)をメインのプロセッシングユニットとして採用したスーパーコンピュータが複数台立ち上がるなど、既存のXeon+GPUなどのアクセラレータとは異なるメニーコアアクセラレータシステムの可能性が示された年となったと言える。
日本でもTOP500で6位、理化学研究所の「京」を抜いて国内トップの演算性能となった最先端共同HPC基盤施設(JCAHPC)の「Oakforest-PACS」が「Xeon Phi 7250」を搭載していることが知られるが、最大の特徴はOpenMPなどの従来のCPUの並列処理と同じ手法で大規模並列処理ができる点にあると言える。
Xeon Phiは次世代として「Knights Hill」(開発コード名)と、ディープラーニング向けプロセッサ「Knights Mill」(開発コード名)の2つの存在を明らかにしているが、Knights Millに関しては8月に開催された「Intel Developer Forum(IDF) 2016」にて存在が明らかにされ、2017年下期に提供を開始する予定であることが発表された。ちなみに同社によると、これらは別々の製品ラインアップであり、Knights MillはKNLをベースに単精度演算性能を向上されたもので、Knights Hillは10nmプロセスを採用した第3世代品と言う位置づけに変化はないとする。
また、AI関連では同社は11月に「Intel AI Day」を米国サンフランシスコにて開催し、当該分野でのIntel Architecture(IA)についての可能性などに言及しているほか、8月に買収したNervana SystemsをはじめとしてSaffron Technology、MovidiusなどAI分野の企業を買収することで、さまざまな技術を吸収していることを明らかにしている。
「ディープラーニングに起因するAIの分野はまだまだ始まったばかりだが、今後、すごい勢いで進歩していくことが見込まれる。その間にAIの手法や実装方法も多岐にわたっていくであろうし、メソッドやインプリの方法、アルゴリズム、ニューラルネットワークのあり方なども変化していく。そうした動きすべてをIA上で最適に動かすことを目指した戦略を進めつつある」と同社は語っており、11月にはGoogleとTenserFlowの高速化やDockerクラスタの管理ツール「kubernetes」のIAによる最適化などに向けた戦略的提携も行うなど、周辺の足場固めも進めつつある。
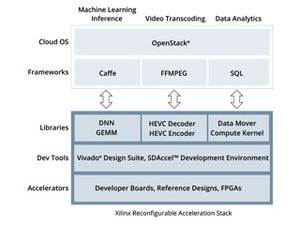
こうした動きの中でも特にNervanaは、今後の同社にとっての重要な位置づけになりそうだ。同社はAI実装の共通アーキテクチャとしてXeon、Xeon Phi、Xeon+FPGA(Arria 10)、Xeon+Lake Crest(後述)といった製品群を「Intel Nervanaポートフォリオ」としてまとめ直しを行っているほか、開発者支援のための「Intel Nervana AI Academy」の提供による技術者育成なども開始しており、Nervanaという名前を引き続きブランドとして使用している。

|

|

|
|
Nervanaプラットフォーム。2017年にはLake Crest、Knghts Mill、Skaylakeアーキテクチャ採用Xeonなどが登場する予定 |
||
ちなみにLake Crestは、もともとNervanaが開発していたASICに基づいたアクセラレータソリューションであり、高いニューラルネットワーク性能を提供するものになるという。2017年にNervanaが開発していたバージョンのチップが提供される予定で、その後、アクセラレータを統合したXeonプロセッサ「Knigits Crest」(開発コード名)を提供することで、マシンラーニングの時間を2020年までに現在の最速ソリューションと比較して100分の1に短縮するとしている。

|

|
|
Lake Crestの概要。32GBのHBM2を同一基板上に搭載するほか、並列化を実現するための独自インタフェースも搭載。また、精度が必要なときと、そうでないときの使い分けを可能とする「Flexpoint」も搭載される |
|
また、「これまでCPUはディープラーニングに向いていないといわれてきたが、ソフトウェアを最適化することで、処理パフォーマンスを向上できる」ともしており、Xeon Phiを用いたテストでは画像数/秒の正規化スループットは最大で400倍向上することを確認したとのことで、ディープニューラルネットワーク向けマスカーネルライブラリ(MKL-DNN)などのマルチノードスケーラビリティを提供するライブラリの拡充を今後、進めていくとする。
これからのAI/ビッグデータの進化を支えるのは?
GPU、FPGA、コプロセッサ、それぞれの代表的ベンダの2016年の動向を振り返ると、いかにコミュニティを構築し、多くのソフトウェアエンジニアを囲い込むか、といった動きを加速させている点が共通項として見えてくる。
そういった意味では、もはや半導体の演算性能の差だけで優劣をつける、ということは難しく、いかに使い勝手が高く、新たに参入する人への障壁を下げるか、といった部分に多くのリソースを割く必要がでてきたと言える。NVIDIAがGPUコンピューティングで躍進を遂げてきたのも、半導体の性能向上以上に長年にわたって、地道にCUDAを中心としたコミュニティの形成と、そこから上がってくるユーザーの声に向かい合ってきたことが挙げられる。
IoTによる膨大なデータの創出やデジタルマーケティングといったあらたなビジネス手法の登場など、コンピュータの演算能力向上に対するニーズはまだまだ止まる気配はなく、ムーアの法則に代表されるような半導体の性能向上は今後も求められ続ける。プロセスの微細化に物理的な限界が見えつつある近年、どうやって性能向上を継続していくのか、技術的な障壁は年々高まっていくばかりである。一方で、半導体を活用する裾野は広がり続けており、そうしたコミュニティの活性化や半導体の活用方法の伝授といった取り組みもそうした半導体企業の使命となりつつある。2017年には、そうした役割の拡大・発展がコンピューティングパワーの向上を牽引するこうした半導体企業により求められることになるだろう。