2016年6月8日に理化学研究所(理研)で、「スーパーコンピュータHOKUSAIとShoubu、研究の最前線」と題するシンポジウムが行われ、PEZYの石川仁氏が「量子アニーリングアルゴリズムの並列化」と題して発表を行った。

|
|
量子アニーリングアルゴリズムの並列化について発表するPEZY Computingの石川氏 |
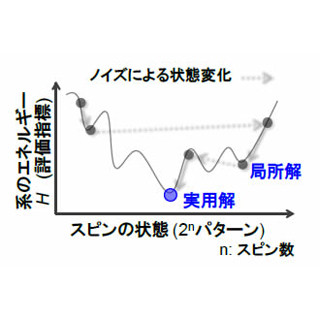
最適化問題の解を見つけるのに、アニールプロセスをコンピュータでシミュレートする「Simulated Annealing(SA:シミュレーテッドアニーリング)」は標準的な手法であるが、複雑なコスト関数の場合は、ローカルミニマムに陥ってしまい、全体的な最適解が得られないということも起こる。これに対して量子アニーリングはトンネル効果でコスト関数のバリアを通り抜けることができるので、収束性が良い。
D-Waveの量子コンピュータは、超低温の超電導状態で量子ビットを作り物理的な量子アニーリングを行っているが、PEZYのプログラムは、量子ビットの振舞いをモンテカルロ法を使ってシミュレートする「Quantum Monte Carlo(QMC)」というアルゴリズムを使っている。

|
|
シミュレーテッドアニーリングと量子アニーリングの違い。トンネル効果がある量子アニーリングの方が収束性が良い (このレポートの図は、Googleと明記したもの以外は、同シンポジウムでの石川氏の発表スライドのコピーである) |
シミュレーテッドアニーリング(SA)は熱ゆらぎによるアニール現象をシミュレートしているが、QMCは量子ビットをシミュレートし、量子ゆらぎによるアニール現象をシミュレートしている点が異なる。この計算には、「鈴木-トロッタ分解」を行い、経路積分を行っているとのことであるが、筆者の理解を超えており、これ以上の説明はできない。
量子モンテカルロアルゴリズムでは、量子ビットおよびトロッタをモンテカルロ法により選択して、コスト関数の変化分を計算し、量子ビットの反転確率を求めて、反転させるというステップを繰り返してコスト関数を最小値に収束させて行く。

|
|
量子モンテカルロ法では、この図の3つのステップを繰り返し実行して、コスト関数を最小値に収束させていく |
PEZY-SCは1024個のコアを持ち、各コアで8スレッドを走らせることができるので、このアルゴリズムの実装に当たっては、次の図のように、それぞれのPEに量子ビットを割り当て、8本のスレッドにトロッタを割り当てて並列化を行っている。
また、コア内のローカルメモリを使って外部メモリへのアクセスを減らして性能を上げている。

|
|
PEZY-SCは1024個のコア(PE)を持ち、それぞれのPEに1個のQubitを受け持たせ、各スレッドにトロッタを受け持たせる |
量子ビット間の結合は解くべき問題によって異なるので、均一ではない。このため、量子ビットごとに計算処理の量が異なる。SIMDでは、スレッドごとに処理が異なるケースはうまく扱えないし、GPUのSIMTでも効率が良くない。しかし、PEZY-SCは各PEが異なるプログラムを実行することができるメニーコアのMIMDであるので、PE(Processor Element)ごとに処理が異なる場合も比較的容易に対応できるという。

|
|
QMCでは量子ビットごとに処理が異なり、SIMDやSIMTでは扱いにくいが、PEごとに異なるプログラムが実行できるMIMDのPEZY-SCではうまく扱える |