前回のGraph500では2位に後退した京コンピュータであるが、既報のように、今回は38621.4GTEPSと前回の19585.2GTEPSのほぼ倍増のスコアで1位を奪還した。そもそもGraph500とはどのようなベンチマークで、どのようにしてスコアを倍増したのかについて、JST CREST PROJECTのリーダーである九州大学の藤澤克樹教授がISC 2015で講演を行った。

|
|
ISC 2015で講演する九州大学の藤澤克樹教授。(以下の図は、藤澤教授の発表スライドのコピーである) |
道路網は、交差点やT字路などの点を道路という線で結んだものと抽象化できる。また、Twitterはメンバーを点、そしてメンバーの間でやり取りされるメッセージを線と考えることができる。このような接続関係を表すものをグラフという。また、グラフでは点はノードあるいはバーテックス(頂点)、線はエッジ(辺)と呼ぶ。
このように抽象化すると、全米の道路網は25Mノードで58Mエッジ、Twitterは61.6Mノードで1.47Bエッジという巨大なグラフになる。また、ヒューマンブレインプロジェクトの脳の神経の繋がりは89Bノード、100Tエッジのグラフとなるとのことである。
道路の分析は効率の良い輸送路を見つけ、物流の最適化に使えるし、Twitterの分析はメンバーのグループを見つけ出すことができ、サイバーセキュリティにも応用できる。

|
|
サイバーセキュリティや医療情報の処理など期待される適応分野は広い |
これらの巨大なグラフを解析して各種の有用な情報を取り出すビッグデータ処理が盛んになりつつあるが、その処理の基本になるのが、グラフがどのように繋がっているのかを解析する処理である。
Graph500は、グラフのつながり方を調べる処理の性能を測定するもので、処理ハードウェアのメモリ容量などに応じて適当なサイズのグラフを使った測定ができるようになっている。
Graph500の概要
Graph500では、スタートに選んだ1つのノードにエッジで繋がっているすべてのノードを見つけ、次に、見つかったノードから繋がっているノードをすべて見つけるという作業を繰り返して、グラフのすべてのノードを見つけるBreadth First Search(BFS:幅優先探索)という処理の性能を競う。
グラフはTwitterなどのソーシャルネットワークと非常に近い性質を持つと言われるクロネッカーグラフをプログラムで生成して作る。この時、1つのノードは平均16ノードに接続されるグラフを生成する。ノード数はSCALEというパラメタで指定され、2SCALEのノードのグラフが作られる。これがGraph500ベンチマークプログラムが行う最初の作業である。
探索プログラムの入力は、両端のノードの番号を書いたエッジ情報の集合であるが、ノード番号はランダムに付けられ、連続した番号にはなっていない。また、エッジの入力データに出てくる順番もばらばらである。このため、入力データを読み込み、グラフデータを作成するのが第2の作業となる。
これが終わると、BFSですべてのノードを探し出す。これが第3の作業である。そして、サーチの結果が正しいことを、グラフをたどって確認するという作業を行う。この、BFSと確認という作業はスタートノードをランダムに選択して64回行う。
性能はTEPS(Traversed Edges per Second)という単位で計測されるが、トップダウンのサーチでは全エッジをたどることになるので、生成したエッジ数を実行時間で割ってTEPSを計算し、64回の実行における中央値を用いてランキングを行っている。
また、Green Graph500では、消費電力を考慮してTEPS/Wという指標でランキングを行っている。

|
次の図は縦軸にエッジ数、横軸にノード数を取り、各種の現実のグラフとGraph500で解くグラフのサイズをプロットしたものである。縦横の軸は2のベキ乗の数字の両対数のグラフである。
Graph500は色々な問題規模でベンチマークが行われている。図の4色の領域分けは、左下から順にSCALE=20以下のスマートフォン規模、SCALE=29の1台のサーバ規模、SCALE=32程度のSGIのUV2000のような大型ccNUMAサーバ規模、SCALE=40程度の大型スパコン規模の領域を示す。

|
|
現実のグラフの規模とGraph500の問題規模。縦軸はエッジ数、横軸はノード数で、目盛は2のべき乗の数 |
グラフのサーチはスタートノードから、それに繋がっているノードをすべて見つけるという作業の繰り返しになる。最初はスタートノードだけであるので、そこからエッジをたどって繋がっているすべてのノードを見つける。見つかったノードの集合をフロンティアと呼び、次回はフロンティアに繋がっているノードを見つけるという作業を繰り返してフロンティアを広げて行くことになる。なお、すでに到達しているノードに行き着いた場合は、その先のサーチは不要である。
このトップダウンというやり方が基本であるが、この逆に未到達のノードから繋がっているノードを調べ、そこがフロンティアのノードであるかどうかを調べるボトムアップという方法が提案されている。トップダウンの場合は、フロンティアのノードのすべてのエッジを調べる必要があるが、ボトムアップの場合はフロンティアのノードに繋がるエッジが見つかれば、他のエッジを調べる必要が無いので調べるエッジの数を減らせる可能性がある。ただし、ボトムアップは、未到達のノードが非常に多い序盤や、ほとんどのノードがすでに到達されてしまいフロンティアが小さくなる終盤では効率が悪いので、状況に応じでトップダウンとボトムアップを切り替える。

|
|
トップダウンサーチとボトムアップサーチを切り替えて使う |
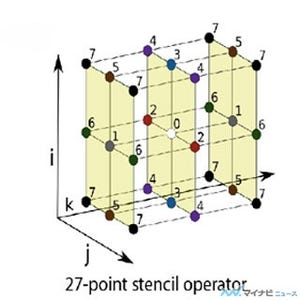
また、ノード間のエッジの存在を記述する接続行列Aを、次の図に示すように2次元に分割して、それぞれの計算ノードに対応させて処理をさせる。ノードの順番が良ければ、1つのプロセサ内の接続が多くなり、他のプロセサの行列をアクセスする頻度を減らして性能を上げることができる。

|
|
接続行列を2次元に分割して、それぞれの部分行列を各プロセサに担当させる |
これらの基本的な処理アルゴリズムはU.C.BerkeleyのBeamerなどが論文発表したものであるが、藤澤教授らのグループは、トップダウンとボトムアップでグラフデータを共用し、メモリの必要量を増加させない処理方法を考案し、また、プロセサ間の通信を計算処理とオーバラップさせることで性能を高めたとのことである。

|
|
トップダウンとボトムアップでグラフデータを共用し、メモリの必要量を増加させない処理方法を考案し、プロセサ間の通信を計算処理とオーバラップさせることで性能を高めた |
TSUBAME-2.xは、2011年11月には99.858GTEPSで4位で、アルゴリズムとしてはトップダウンだけであった。そして2012年6月にはGPUの使用でスコアを317.09GTEPSに伸ばし、今年の6月にはトップダウンとボトムアップのハイブリッドで1345GTEPSまで性能を伸ばしている。
京コンピュータの最初の登場は2013年11月で、この時はトップダウンだけのアルゴリズムで5524.12GTEPSで4位であった。それが2014年6月にはハイブリッドアルゴリズムの採用で17977.5GTEPSまで性能を伸ばして1位を獲得した。
今回は、調べるべきエッジが残っていないノードの削除(Zero-degree Suppression)と残っているエッジ数が大きい順にノードをソートする工夫(Vertex Sorting)を加えて約2倍の38632.4GTEPSを実現し、23751GTEPSのSequoiaを抜き返して1位に返り咲いた。

|
|
TSUBAME-2.xと京コンピュータの性能改善の経緯。アルゴリズムの改善で大きく性能を改善している |
次の図はGraph500の1位のデータと藤澤先生のグループが京コンピュータ、TSUBAME-2.x、TSUBAME-KFCなどのマシンで行ってきた性能改善の成果を示すものである。

|
|
Graph500の性能の推移とグラフクレストチームの性能改善の推移 |
また、Graph500の1位に加えて、グラフサーチの電力効率を競うGreen Graph500のBig DataカテゴリでもSandybridgeを使うサーバでSCALE 30のグラフで62.93MTEPS/Wを実現して1位に輝いた。

|

|
|
Graph500 1位を獲得 |
Green Graph500のBig Data部門の1位も獲得 |