・GTC 2015 - Deep Learningを理解する(前編)はコチラ
・GTC 2015 - Deep Learningを理解する(中編)はコチラ
多くの対象物が含まれている画像の認識は難しいのであるが、次の例のような写真では食べ物が確度16%で第1候補、夕食が3.1%、バーベキューが2.9%マーケットが2.5%、食事と七面鳥が1.4%でなかなか良い認識が並んでいる。元の画像は247KBで処理時間は110msである。

|
|
この写真に対して、食べ物が16%、夕食が3.1%、バーベキューが2.9%、マーケットが2.5%、食事と七面鳥が1.4%。処理時間は0.11秒 |
一方、次の写真は洞窟の内部の写真であるが、人間でも、何の写真であるか判別が難しい。システムはスぺインのサグラダファミリア教会と間違え、バルセロナが確度6.5%、サグラダが1.9%、ファミリアが1.4%となっている。しかし、洞窟も2.2%で第3位の候補に入っている。元の画像は278KBで処理時間は113msである。

|
|
認識の難しい例。サグラダファミリア教会と間違え、バルセロナが確度6.5%、サグラダが1.9%、ファミリアが1.4%となっている。しかし、洞窟も2.2%で第3位の候補に入っている |
画像認識は、すでにFacebook、Google、Microsoft、Twitterなどで、顔認識、画像サーチ、写真の整理などに用いられている。顔認識では、正面から見た画像に変換してからフィルタを掛けて畳み込みを行う。ただし、Facebookでは、全画面に一様なフィルタではなく、目の周囲や口角など特徴的に重要な部分については特別なフィルタを使っているという。そして、最後の数層で顔の特徴を表すラベルに変換する。

|
|
認識技術は、Facebook、Google、Microsoft、Twitterなどで、顔認識、画像サーチ、写真の整理などに用いられている。GPU1台で毎秒100画像と非常に速い |
インターネットで見かけた写真の人物を探すというのは良く用いられる使い方で、左側のような有名人のデータベースとサーチする写真の顔が同一人か別人かを判定する。

|
|
有名人の顔写真のデータベースと右側の入力画像を比べ、同一人か別人かを判別する |
同一人判定では、人間の97.5%の同一判定(黒線)に対して、FacebookのDeepFace(赤線)は97.25%とほぼ同等で、現在ではこのデータよりも改善されているという。

|
|
縦軸は同一人を正しく判定する確率、横軸は別人を同一人と誤判定する確率。人間の97.5%に対してFacebookのDeepFaceは97.25%と迫っている |
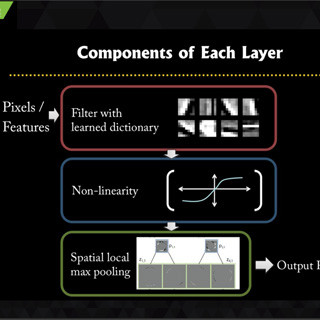
ConvNetsの第1層は、次の図のように、単位小領域の中で、各方向の線やグラデーションを検出するフィルタとなっている。

|
|
第1層のフィルタ群。各方向の線やグラデーションを検出するものが多い |
そして第2層では、この結果を受けて、第1層より上位の特徴を検出する。次の図は第2層のそれぞれのフィルタに最も強く反応する9種の小領域の画像(パッチ)を示している。左上のフィルタは黒っぽい塊がある画像に反応し、4行目の右端のフィルタはドーナツのような2重円に反応している。また、各種の台形などの幾何学模様に反応するフィルタも多く存在する。

|
|
第2層の各フィルタに反応するTop-9のパッチの画像 |
そして、次の図は、第2層のTop-9パッチに対する出力である。

|
|
第2層のTop-9パッチの出力 |
次の図は第5層の各フィルタに反応するTop-9パッチで、3行目の右端や4行目3列のフィルタは犬の検出フィルタ、2行目4列はキーボードの検出フィルタとなっている。

|
|
具体的な対象に強く反応し、3行目の右端や4行目3列のフィルタは犬の検出フィルタ、2行目4列はキーボードの検出フィルタとなっている |
次の図は、第5層のTop-9パッチに対する出力である。パターンが細かいので見るのが難しいが、犬の顔など第2層よりも高次の特徴を抽出していることが分かる。

|
|
第5層のTop-9パッチの出力 |
このように、初めの層では斜めの線などの低レベルの特徴を抽出し、高次の層になると前の層の特徴を組み合わせた特徴を抽出するようになり、第5層では犬やキーボードなどかなり具体的な対象に強く反応するフィルタが出てくる。
次の図のように、各層の出力にクラス判別機を入れてみると、1層目の精度は25%程度であるが、層を経るごとに精度が高まり、6層目では70%を超える精度になっている。このように、ネットワークの層の深さは重要であり、ILSVRC2014のモデルは約20層という構成になっている。

|
|
各層の出力にクラス判別機を入れると、層が増えると精度が上がっていくことが分かる。ILSVRC2014のモデルは約20層となっている |
ここまでは2次元の画像の認識の話であったが、時間軸を加えたビデオの認識についても研究が行われている。このためには空間と時間を合わせた3次元の畳み込みとプーリングが必要となる。
しかし、時間をいれた処理となるので、動きの検出や将来のアクションの予測ができるようになる。

|
|
ビデオの場合は時間軸を加えた3DのConvolutionとPoolingが必要であるが、動きが検出でき、アクションの予測が可能になる |
ビデオ認識の例。ローラースケートを履いたプレーヤーがかたまっているが、全体が移動していることから、ローラーダービーと正しく認識している。

|
|
ビデオの認識の例。全体の動きからローラーダービーと正しく認識している |
この一連の記事から、Deep Learningの歴史と現状、どのようにして認識を行っているかの原理について理解を深めて戴ければ幸いである。