(GTC 2015 - Deep Learningを理解する(前編)はコチラ)
当初は学習に使える画像が少なかったが、スタンフォード大がImageNetを立ち上げ、現在では2万カテゴリのラベル付けがされた、1400万枚の画像が集められている。
ImageNetでは、毎年、 ImageNet Large Scale Visual Recognition Challengeという画像認識のコンペが行われている。昨年のILSVRC2014では45万6567枚のトレーニング(学習)用の画像が提供された。これらの画像には200カテゴリの画像が含まれている。そして、2万121枚のバリデーション(確認)用画像が提供されており、これを使って学習したモデルの振舞いを確認する。
そして、テスト用の4万152枚の画像を認識して、その結果を競う。競うといっても一堂に会して行うわけではなく、期限までに提出された認識結果を審査して、最高の成績をあげたものを優勝として表彰を行うという形式である。
これらのデータには全部で200カテゴリの画像が含まれているが、例えばAで始まるカテゴリをリストするとaccordion、airplane、ant、antelope、apple、armadillo、artichoke、axeとなっている。そして認識のコンペでは、各テスト画像に含まれている対象のカテゴリをどれだけ正しく認識できるが競われる。

|
|
ImageNetにはインタネットから集められ、人手でラベルが付けられた画像が1400万枚集められている |
2012年のILSVRCでは、次の図に示すDNNを使ったトロント大学のKrizhevskyのグループが優勝した。基本的には1989年にLeCunが提案したものと同じ考え方のDNNであるが、次の図に示すように、層の数が8層とモデルが大きくなっている。また、非線形関数としてRectified Linear Functionの採用、学習アルゴリズの改良が行われている。そしてGPUを使って処理を高速化しており、LeCunは1000画像でトレーニングを行ったのであるが、トロント大は100万枚のトレーニング画像を使って精度を高めている。
このトロント大のモデルは、65万ニューロンを使い、学習で調整するパラメタは6000万個で、2台のGPUを使っての学習には2週間を要したという。

|
|
2012年のILSVRCで前年から約10%認識率を高めて優勝したトロント大のDNN |
ILSVRCの画像であるが、次の図のように、1つの対象しか写っていないものもあるが、複数の対象が写っているものも多い。しかし、全部の対象にカテゴリ名を付けるのは作業として大変であるので、1つの対象にしか正解のラベルが付けられていない。
しかし、認識システムはどの対象が正解として選ばれているのか分からない。このため、認識システムが候補としてあげた上位5つの答えの中に正解が含まれていれば、認識成功としてポイントを与えるという採点をしている。Top-5 Errorというのは上位5つの候補に正解が含まれていない率で、2012年のトロント大の結果は、この率が16.5%であった。
次の図に回答の一部の例を示している。上の行の4枚は、左からダニ、コンテナ船、モータースクーター、豹で、第1候補で正解の例。下の行の左端は第1候補はコンバーティブルで正解のグリルは第2候補、2枚目は第1候補はベニテングダケで正解のきのこは第2候補であるがどちらも第5候補までには入っている。しかし、3枚目は第1候補でダルマチアン、第2候補はぶどうで、正解のチェリーはTop5に入っていなかった。また、4枚目は第1候補はリスザルで各種のサルを候補に挙げているが、正解のマダガスカルキャット(Catと呼ばれるが猫ではなく、マングースに近い)はTop5に入っていなかった。
下の行の3枚目はダルマチアンが正解でもおかしくない絵で、前景のチェリーをブドウと認識してしまったのが敗因。4枚目は動物の種類を当てる難しい絵で、人間でも正解できる人は殆どいないと思われる。

|
|
上の4枚はダニ、コンテナ船、モータースクーター、豹で、第1候補で正解の例。下の4枚は左から、第1候補はコンバーティブルであるが正解は第2候補のグリル、2枚目は、第1候補はベニテングダケで正解は第2候補のきのこ、この2枚は第2候補で正解の例。3枚目はダルメシアンが第1候補であるが正解はチェリーで外れ、4枚目はリスザルが第1候補で色々なサルを候補に挙げているが外れと正解できなかった例 |
ILSVRCは毎年行われており、2010年から2011年は2%程度しかTop-5エラー率が改善していないが、2012年のトロント大のHinton教授のグループの結果は、10%近い大幅な改善を達成した。2012年までは色々な認識法のシステムが使われていたのであるが、この成功から2013年以降は、ほとんどすべてのシステムがトロント大の方式になってしまった。GTCの基調講演で、Jen-Hsun Huang CEOがBig Bangと表現したのも頷ける。
そして、2014年にはGoogleが6.7%を達成して優勝している。
ILSVRCは、年ごとにトレーニング、ベリフィケーション、テストの画像の枚数や含まれるカテゴリ数が大きくなっている。そして、2015年のデータはまだ公表されていないので、公式記録は2014年までであるが、その後の改善も次の図には含まれている。2014年の次のHumanと書かれているのは、スタンフォード大学の研究者のAndrej Karpathy氏が1500枚の画像を見て認識した結果で、Top-5エラー率は5.1%であった。これはかなり学習した結果で、普通の人間ではとてもこうは行かない。なお、ILSVRCのテスト画像は200カテゴリ4万152枚であるが、Karpathy氏はランダムに選んだ1500枚を認識しただけであり、5.1%は参考記録である。
その後、2015年に入って、Microsoftが4.94%のTop-5エラー率、Googleが4.82%というエラー率を発表している。ただし、これらは2014年のデータでの結果で、やはり参考記録であると思われる。しかし、2015年のILSVRCの結果締切は8月であり、これらの記録を上回る結果が提出される可能性は高いと思われる。

|
|
ImageNetのILSVRCのTop5エラー率の推移。2012年にトロント大が大幅改善し、その後も改善が続いている |
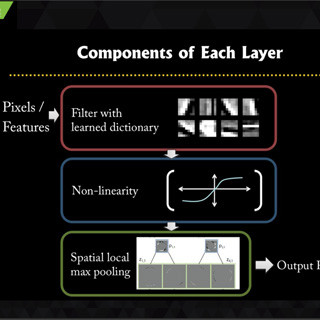
これまでに説明したように前側のConvolution層はエッジから始まって、だんだんと上位の部品を認識して行く層で、最後の3層程度が全体的な対象物の認識を行っている。従って、新しい画像セットの認識を行わせる場合も、前の方の層はそのまま使って、最後の数層を新しいデータセットを使って学習させることで対応できるという。
Facebookの論文では、このやり方でクラスあたり6枚の画像のトレーニングで以前に発表された論文のレベルの認識率が得られ、60枚の画像のトレーニング結果で比較すると、エラー率は半減した報告されている。

|
|
新しい画像セットを認識する場合も前側のConvolution層は、前のまま使用でき、対象物を認識する最後の数層を新しいデータを使って学習すればよい。チューニングされた前側の層を再利用することで、エラー率は半減するという |