米国のカリフォルニア大学バークレー校(University of California, Berkeley)のHelen Wills神経科学研究所のShinji Nishimoto(西本 伸志)氏らの研究チームが生物学の学術雑誌「Current Biology」に"Reconstructing Visual Experience from Brain Activity Evoked by Natural Movies"と題する論文を発表した。

|
|
西本伸志氏(大阪大学 大澤研究室のWebサイトより転載) |
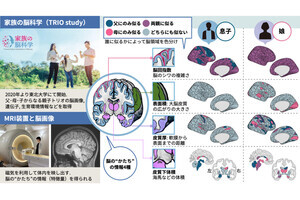
脳の視覚皮質(Visual Cortex)の活動状況をfMRI(Functional Magnetic Resonance Imaging)で検出し、その情報を処理すると、どのような映像を見ているかが分かるという研究である。この技術が実用化すれば、脳とコンピュータの直接のインタフェースが作れるし、神経関係の病気の診断、治療などにも役立つと考えられる。また、夢や幻覚なども動画映像として脳から取り出すことが可能になるかも知れない。
脳の血流量や血液の酸素濃度はニューロンの活動状況と概ね比例しており、それを測定することで間接的に脳の視覚皮質の各部のニューロンの活動を測定するという方法がとられる。BOLD(Blood Oxygen Level Dependent:血中酸素濃度依存)信号をfMRIで測定し、それを解析して何をしているのかを理解しようという研究は以前から行われており、2006年にはThirionなどが、視覚皮質のfMRIデータから、目で見ている静止画像を推定することに成功している。しかし、fMRIの信号は毎秒1フレーム(1fps)程度のゆっくりした速度でしか得られないので、この方法では見ている動画像を推定するということはできておらず、動画像の認識は、今回の西本氏らの発表が初めての成果である。
この方法であるが、まず、3人の被験者(著者たち)にYouTubeなどからとってきた約18,000,000秒(100万クリップ)の実写の映像を見せて、その時の視覚皮質の活動状況をfMRIで測定する。映像を見せるといってもfMRI装置の中なので、通常のディスプレイではなくLCDゴーグルに表示している。解像度は512×512ピクセルで15fpsにダウンサンプルされ、1つひとつのクリップは10~20秒の長さになっている。
fMRIの解像度は2mm×2mm×2.5mmで、このサイズのVoxel(volumeとcellを合わせた造語で、解像度で決まるそれぞれの箱ごとにデータ値を持つ)データとして記憶する。そして、テストデータを見せたときのVoxelデータと、このデータベースのどの動画を見ているVoxelデータと近いかという計算を行う。

|
|
fMRIデータの処理(西本氏らの論文から転載) |
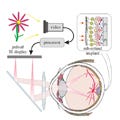
こう書くと簡単であるが、直接、Voxelのデータ同志を比較するのではなく、上図のAに書かれたようにMotion Energyフィルタを掛けて特徴を取り出し、さらにそれぞれのVoxelによって異なる血液の応答特性を補正してデータを作る。Motion Energyフィルタ処理の内容が上図のBに書かれているが、まず、色情報を落として明るさだけのL信号を作り、それをVoxelごとのニューロンの働きに対応する6555チャネルの時間領域と空間領域のフィルタを掛け、全部のフィルタの出力の2乗和を求めてMotion Energyを計算する。このようにデータに時間領域の情報を含んでいる点が特徴である。その結果を対数圧縮してから、15fpsで計算されたデータを1Hzにダウンサンプルして出力を作っている。
このデータの取得であるが、同じ画像でも視線が動いてしまうとデータが変わってしまうので、4ピクセルの視線固定カラーパターンを挿入している。データベースの作成は、100万クリップの動画をランダムなシーケンスで表示してfMRIでBOLDデータを測定する。何時間もMRI装置の中で体を固定され、視線固定パターンから目を離さないようにするのは、難行である。このようにして測定したBOLDデータに上記の処理を行ってデータベースを作る。
そして、実験の前には12個の各10分の映像ブロックを見せ、認識系のパラメタを被験者向けにチューニングし、その後、テスト映像データを見せる。テスト映像データは9個の各10分のブロックからなっており、各ブロックには10個の各1分の動画がランダムな順序で入っている。なお、テストデータの映像はデータベースの映像とは重複していない新しい映像である。
そして、テスト映像を見たときのBOLDデータと、100万クリップのデータベースとの一致度をベイズ推定を使って計算する。しかし、1つのクリップとの一致を計算すると、同じようなクリップがデータベースにある場合は良いが、似たようなクリップが無い場合はうまく行かない。このため、100クリップの映像の平均値との一致を計算するという方法をとっている。
このMotion Energyの計算とベイズ推定を使う一致度の計算が、今回の成果の鍵で、色々な工夫で精度を高めることにより、同じ映像の場合は、観測されたBOLDデータから元の映像を95%の確率で認識することが可能になったという。
なお、色情報を落とすのはデータ量を減らすためで、今回の映像では髪と顔、体などは色と明るさの境界が一致している場合が多く、認識率にはほとんど影響が無かったという。

|
|
論文に示された認識結果の例 |
上の図は、最上段が見せたテスト映像の1秒ごとの3つの画像で、次の5段がそれぞれの映像を単一の映像との一致度計算した時の上位5位までの映像、そして最下段が100映像平均で作った一致度の高い映像である。A、B、Cはそれぞれ異なる3つの映像サンプルであるが、Aの顔の映像と比べて、Bのインクのシミのような映像は単一映像との一致度計算では似ているものを見つけるのが難しいことがわかる。
また、U.C.BerkeleyのWebサイトには動画の認識結果が置かれている。これを見ると、元の映像と似ていると言われれば似ていないこともないという程度という見方もできるが、一方、人間の脳から、これだけの動画情報が読み出せるというのは驚くべきことである。
fMRIのノイズを減らし、もとのデータベースのクリップ数を大幅に増やせば、認識の精度は上がっていくので、今後の改良に期待したい。また、今回の実験ではEarly Visual Cortexという視覚の入力に近い部位の情報を用いたが、より処理の進んだVentral-temporal Visual Areaからの情報の方が特徴を良く表しているという報告もあり、両者からの情報を複合した認識により、さらに精度が上げられる可能性もあるという。
現状では個人ごとに膨大な数のクリップを見せてデータベースを作る必要がある。また、fMRIはかなり大がかりな装置であり、本人が知らないうちに勝手に頭の中の映像が覗かれてしまうということはあり得ない。しかし、音声認識の例では、最初は特定話者のデータベースを作っていたが、それが不特定話者になり、入力環境もちゃんとしたマイクを使った静かな環境から、音質の劣る電話でもOKというように改善されてきており、この脳内の映像認識も、脳内活動の測定法とデータ処理アルゴリズムと計算能力の進歩で、より広範な環境で可能になっていくものと思われる。いずれにしても気になる、興味深い研究である。