今回のIDFでは、Nehalemに関する話題も色々出てきたようだ。基調講演のみならず、テクニカルセッションやChalk TalkでもNehalemに色々触れられている。このあたりをまとめてレポートしてみたい。
内部構造
Nehalemの設計ポリシーはいくつか語られたが、まず回路レベルにおける目標としては、より低消費電力/高パフォーマンスを目指すこと(Photo01)、及びパフォーマンスと消費電力のトレード比を再び1:1に戻すこと(Photo02)の2つが挙げられる。前者はともかく、後者はちょっと興味深い。「再び」1:1に戻すというのは、Banias/Dothan世代では、これが1:3だったからだ。もっとも当時の発想は逆で、「1%の性能の犠牲で3%の消費電力削減が可能ならば、それは採用する価値がある」というものだった。要するにMicroArchitectureレベルで、より低消費電力の方向を志向していたわけだ。対してNehalemでは、再び高性能の方向に舵を切りなおしたという事になる。勿論低消費電力の方向性を捨てたわけでは無いが、少なくともMicroArchitectureレベルではこうした配慮をしなくても済む程度に、Process/Circuitのレベルで低消費電力が実現できそうだという目処が立った、と考えるべきなのかもしれない。
 |
 |
|
Photo01:90nmまでと65nmを比べて、という文脈での話だったから、直接Nehalemに関係するわけではないが、Performance(トランジスタのスイッチング速度)を高めつつ、Power(消費電力。この中にはリーク電流に起因する分も当然含まれる)を減らそうというのが右側のグラフとなる。ただし微細化が進むにつれ、VminとVmaxの幅がどんどん縮まってゆく傾向にあり、これへの対処も重要な課題となる。 |
Photo02:こちらは回路というよりはMicroArchitectureレベルの課題。1%以上性能を上げるにあたり、消費電力の増加を1%に抑えようという目標を立てており、それを実現するのがLoop Stream Detectorである。Loop Stream Detectorは既にデコード済命令の再デコードを省く事で、省電力化を図ろうというものである。Chalk Talkではするっと流して説明したが、冷静に考えると色々重要なヒントが詰まっている気がする。 |
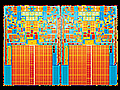
さてそのNehalem、今回はダイ写真内部の詳細(Photo03)も公開された。昨年のIDF Fallの時の筆者の推定図はそれほど間違ってなかったというのはちょっと嬉しいところだが、それはともかくとして内部構造をもう少し仔細に見てゆきたい(Photo04)。
 |
 |
|
Photo03:QPIとMISC I/Oが混在しているのは読めなかった。あとMemory Controllerが意外に大きいのにもびっくり。Tagについては、Photo03は単に省いただけであろう。 |
Photo04:これはあくまで主要な特徴を適当に割り振ったというだけで、これが実際のダイ上の配置という訳ではない。 |
プロセッサコアの概略がこちら(Photo05)である。パッと見て判るのは、Reservation UnitsからExecution Unitが同時6命令になっていること、それと2nd Level TLBが増設されていることだ。逆に言えばDecodeやRename/Allocateは従来と変わらない様に見えるが、実際はそういう単純な話ではないだろう。
 |
|
Photo05:もっとも後述するとおり、MacroFusionが更に広く利用されるようになったため、Decode段から出力される実効命令数はむしろ従来より増えている筈である。なので、Rename/Allocateについても実際にはCore Microarchitectureよりも強化されていると考えたほうが良さそうだ。 |