英単語で正規表現をマスターしよう
「正規表現」という言葉を聞いたことがあるだろうか。正規表現はとても便利なので、プログラマーでなくてもマスターしておきたい機能だ。多くのテキストエディタに正規表現を使った置換機能があるので、正規表現を覚えると、Pythonだけでなくあらゆる場面で活用できる。今回は、英単語辞書のデータを利用して、正規表現をマスターしよう。
英単語で正規表現とはどういうことか?
「正規表現」とは、文字列の集合を特殊なメタ文字を利用して表現する方法だ。正規表現に似た表現に「ワイルドカード」がある。ワイルドカードでは「*.txt」のようなパターンを記述することで、「abc.txt」や「書類.txt」などを表すことができる。これは主に、ファイル検索などで、拡張子「.txt」(テキストファイル)を列挙するのに役立つものだ。そして、正規表現は、このワイルドカードを何十倍も便利にしたものと言うことができる。
ところで、前々回、データベースの操作言語SQLを学習するのに英単語データベースを利用した。フリーの英語辞書を利用することで、さまざまな英単語を表示することができて楽しかったのではないだろうか。今回は、正規表現をマスターするために、英単語辞書のデータを利用してみよう。SQLの時と同じく、とても楽しく正規表現を学ぶことができる。今回は、SQLデータベースではなく、テキストデータの辞書を使う。
こちらから、テキスト形式の辞書データをダウンロードしよう。そして、ZIPファイルを解凍すると「ejdic-hand-utf8.txt」というファイルができる。これが、テキスト形式の辞書データだ。これを、Pythonから読み込んで使ってみよう。
Python3をインストールした状態で、コマンドラインを起動しよう。WindowsならコマンドプロンプトやPowerShell、macOSならターミナル.appを起動しよう。その後、コマンドラインから、対話型実行環境REPLを起動しよう。
# --- Windowsの場合
python
# --- macOSの場合
python3
Pythonの対話型実行環境が起動したら、以下のPythonプログラムを実行して、辞書ファイルを読み込もう。(なお、『>>>』は、Pythonにプログラム入力可能なことを表す記号で、入力する必要はない。)一度にメモリ内に辞書データを読み込むので、古いPCで試すと、実行に非常に時間がかかる可能性もある。その場合には、Colaboratoryなどクラウドの環境で試すこともできるだろう。以下を実行すると、辞書ファイルをメモリに読み込んで変数txtに代入する。
>>> txt = open("ejdic-hand-utf8.txt", "rt").read()
次に読み込んだ辞書データを改行で区切ってみよう。
>>> lines = txt.split("\n")
この辞書データは、一行一データになっている。len()関数を使うと、辞書のデータ数を調べることができる。実行すると、46726語の単語があることが分かる。
>>> len(lines)
46726
続いて、辞書から単語部分だけを抽出しよう。以下のように記述すると、辞書から英単語だけを取り出したリストwordsを作成する。
>>> words = list(map(lambda s: s.split("\t")[0], lines))
そして、正規表現をテストするための関数を定義しよう。今回、この関数を利用して正規表現を試すので重要だ。この関数は、英単語リストwordsから指定の正規表現に合致する単語のみを返すというものだ。ラムダ関数やfilter()関数などを使っているのでちょっと複雑に見えるかもしれない。しかし、各単語ごとに正規表現検索re.search()を実行して、検索にマッチすれば、その単語を返す。
>>> import re
>>> m = lambda pat: list(filter(lambda w: 1 if re.search(pat, w) else 0, words))
それでは、いよいよ正規表現を試してみよう。
英単語を検索しよう
それでは英語辞書から任意の単語を抽出してみよう。まずは、以下のプログラムを実行して、lowを持つ単語をピックアップしてみよう。
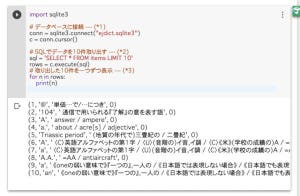
>>> m(r"low")
すると、以下のようにowを含むたくさんの単語が列挙されるだろう。このように、正規表現検索re.search()関数を使うと、検索対象の一部にマッチするものがあれば、それを返す。なお、r"文字列" のように書くと、エスケープ文字の「\」などをエスケープ文字と扱わないようになる。正規表現を記述する際に便利なので、覚えておこう。
-

lowを含む単語を検索したところ

末尾にマッチする語句を調べたい場合の「$」
正規表現では特殊な意味を持つ「メタ文字」と呼ばれる特殊な記号を指定することで、パターンに意味を持たせることができる。例えば「$」記号は末尾を意味するメタ文字だ。「low$」のように指定すれば、「allow」「glow」など単語の末尾がlowで終わる単語のみをピックアップできる。試してみよう。
>>> m(r"low$")
実行すると、次のように表示される。
-

末尾に「low」を持つ単語を抽出したところ

行頭にマッチする語句を調べたい場合の「^」
逆に、lowから始まる語句を調べたい場合には「^」を利用して「^low」と記述する。以下のパターンを試してみよう。
>>> m(r"^low")
実行すると、以下のように「low tide(干潮)」や「lowery(陰気)」などの単語が表示される。
-
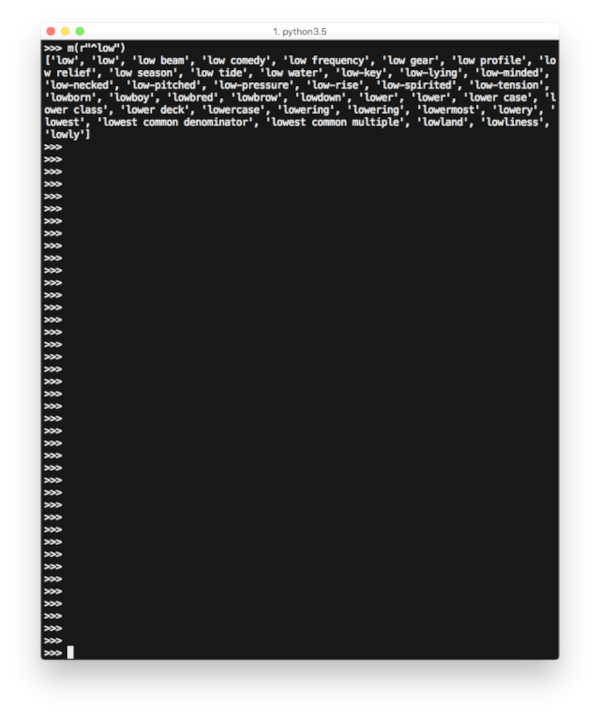
「low」から始まる単語を抽出したところ

任意の一文字を表す「.」
次に、任意の一文字を表す「.」を使ってみよう。先ほど紹介した行頭の「^」や行末の「$」と組み合わせて、「^a.t$」のように記述すると、aからはじまりtで終わる3文字を抽出することができる。
>>> m(r"^a.t$")
実行すると、重複もあるが、以下のように「ant(アリ)」や「art(芸術)」などが列挙される。
['act', 'aft', 'ant', 'ant', 'apt', 'art', 'art']
全く同じだが、aからはじまりtで終わる5文字の単語を列挙するには「^a...t$」と記述する。すると「about(〜について)」や「alert(警告)」が列挙される。
>>> m(r"^a...t$")
このように任意の一文字を覚えると、面白い検索が可能であることが分かるだろう。
1文字以上の繰り返し「+」と0文字以上の繰り返し「*」
次に、1文字以上の繰り返しを表す「+」について見てみよう。例えば、「a+」のように書くと「aa」や「aaa」、「aaaaa」などがマッチする。「f+」のように書くと、「ff」や「ffff」がマッチする。
そして、任意の一文字「.」と組み合わせると、任意の一文字以上という意味になる。そのため、oから始まってwで終わる単語を調べたい場合には、「o.+w」というパターンを指定する。試してみよう。
>>> m(r"^o.+w$")
すると、「overflow(あふれる)」や「overgrow(大きくなりすぎる)」などの単語が見つかるだろう。
また、「+」と似たメタ文字には「*」がある。これは、0文字以上の繰り返しを表す。下記のように書くと、「^o.+w$」で列挙した単語に加えて、「ow(激痛を表して)ウウッ」も列挙する。
>>> m(r"^o.*w$")
-

oからはじまりwで終わる語を抽出したところ

まとめ
このように、正規表現を使うと、とても細かく検索条件を指定することができる。ここで紹介した正規表現は、代表的なものであり、他にも便利な機能がたくさんある。各メタ文字の意味を理解するために、いろいろなパターンを指定して、その結果を確認してみよう。そうするなら、正規表現をより深く理解することができるだろう。Pythonの公式マニュアルには、利用できる正規表現の一覧が載せられているので、マニュアルを参考に、いろいろなパターンを試してみると良いだろう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。