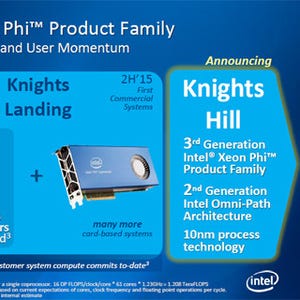
フランクフルトで開催されたISC 15のワークショップにおいてIntelの次世代Xeon Phiである「Knights Landing」のチーフアーキテクトのAvinash Sodani氏が、Knights Landingのアーキテクチャについて発表を行った。なお、Knights Landingの発売は2016年の予定である。
「Knights Corner(KNC)」はCPUから駆動されるコプロセサであったが、「Knights Landing(KNL)」は、Xeon CPUと命令互換となり、OSをブートして実行を開始できるCPUとなっている。そして、コアが更新され、性能が大幅に向上している。また、3D積層メモリをCPUと同じパッケージに搭載し、メモリバンド幅を大幅に改善している。さらに、KNLノード間を接続するOmni-Pathファブリックのインタフェースを内蔵している。
そして、KNLでは3種の形態の製品が作られるという。1つは、PCIe経由でCPUに接続するアクセラレータであり、これはKNCと同じ形態である。その他の2つの製品はSelf-Bootと呼ばれるもので、これらはOSを走らせるXeon CPUを必要とせず、KNLのコアでOSをブートして実行を開始することができる形態である。2種類のSelf-Boot製品の内の1種はベースラインと呼ばれるKNLチップ1個にDRAM、I/Oを接続するシングルソケット製品、もう1種はOmni-Pathのファブリックインタフェースを内蔵し、多数のKNLボードを相互接続する機能を持つ製品である。

|
|
次世代Xeon PhiであるKnights Landingを説明するチーフアーキテクトのAvinash Sodani氏 |
KNLはチップあたり3TFlops超の倍精度浮動小数点演算性能
KNLではSelf-Bootができるようになっているので、KNCや他社のGPUカードのように、CPUメモリのデータをPCIe経由でアクセラレータのメモリに転送したり、その逆の転送を行なったりする必要がなく、PCIeの性能がボトルネックになることがない。また、KNLコアはXeon CPUと命令互換であり、Xeon CPUのプログラムはリコンパイルなしに動作するようになる。ただし、これは動作はするが、必ずしも最適な性能が得られるということではない。
KNLのSilvermontベースのコアは、KNCのコアと比べると3倍程度のシングルスレッド性能を持っている。そして、演算性能も大幅に強化されており、512bit幅のAVX512 SIMD命令をサポートし、チップあたり、3TFlopsを超える倍精度浮動小数点(DP:Double Precision)演算性能を持っている。
AVX512命令では、8個のDP演算を並列に実行できるが、この8個のデータがメモリ上の連続したアドレスにある場合は1つの命令で512bit幅のAVXレジスタにロード、ストアができるが、飛び飛びのメモリアドレスの場合は、最大8回のロード、ストア動作を必要とする。このように、あちこちのアドレスからデータを集めてくる機能を「Gather」、あちこちのアドレスにばらまいて格納する機能を「Scatter」という。
KNCにも、Scatter/Gather命令があるが、これらはマイクロコードで実現されており、あまり、速くはなかったという。これに対してKNLではハードウェアのScatter/Gatherエンジンを持ち、短時間で飛び飛びのアドレスをアクセスしてメモリの読み書きができるようになっている。
KNLでは、MCDRAMと呼ぶ3D積層のDRAMをKNLチップのパッケージに搭載し、メモリバンド幅を大幅に向上している。AMDのFury X GPUはHBM(High Bandwidth Memory)を搭載しており、NVIDIAのPascal GPUもHBMをサポートする計画であり、2016年には高メモリバンド幅の3D積層DRAMの採用は一般的になると見られる。
そして、KNCではチップ内のコアは多重のリングバスで接続されていたが、KNLではメッシュインタコネクトに変更される。これにより、バンド幅が増加し、ホップ数も減少し、高速、高バンド幅になると見られる。

|
|
KNLの新機能の一覧 |